fastai - Quality and Evolution
Fastai is a Deep learning library with Jupyter notebooks to allow for expository programming1. The documentation and the Python source code of the library are automatically generated from these notebooks. The combination of these characteristics makes this library unique with regards to what it offers, but also how it (might not) safeguard(s) the quality and architectural integrity of the library.
This post evaluates the quality and evolution of fastai, with special attention to the rate of change. We provide a bird’s eye view of the overall software quality processes in section Software quality. Then, in the section Continuous integration, the automated quality improvement process is elaborated. Next, how tests are implemented and run is discussed in section Testing. Afterward, we go over which parts of the library changed over time in section Hotspot components. Later, assessment of the quality, with a focus on the hotspot components is discussed in section Code quality. Then collaborative effort towards code quality improvement is found in section Quality assurance. Lastly in section Technicacl debt an assessment is made.
Software quality
Having a good understanding of what your non-functional requirements are will help you develop the product that you intended to develop, by setting constraints on what implementations can be done. For non-functional requirements, we consider quality attributes like performance, scalability, and maintainability. In the figure “functional vs non-functional” the difference between functional and non-functional requirements are depicted for the fastai library. The requirements have been further split into a user and a product category. From this figure, we can conclude that the non-functional requirements set the direction on how functional requirements should be implemented.
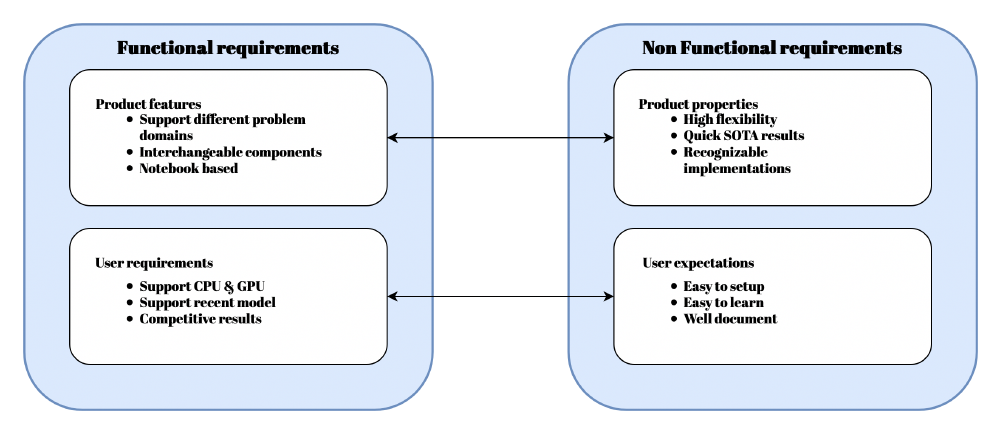
Figure: Functional vs non-functional
As discussed in our first essay, fastai emphasizes flexibility and ease-of-use. The non-functional requirement: “flexibility” is reflected throughout the entire code base, as most components can be swapped out and replaced with other components. A good example of this is the Optimizer class. Selecting the correct optimizer is important for deep learning as it can greatly influence the models' performance. Swapping from one optimization strategy to another is just as easy as creating a new class.
Next to flexibility, ease-of-use is one of the non-functional requirements of fastai. This especially targets newer deep learning practitioners, one of fastai’s stakeholders. Throughout the whole library, an emphasis has been put into making fastai as easy to use as possible. This can be seen in the many examples given for various models and even a deep learning course has been published to teach these new practitioners how deep learning works.
Continuous integration
Verifying the different functional and non-functional requirements promptly is a part of a continuous improvement process. In this process, the product perpetually adapts to the current situation. Currently, there are three consecutive ways to go about this improvement process; Continuous integration, delivery, and deployment2.
Fastai only follows the Continuous integration principle. Every few days pull requests are accepted by the founder of the project. These pull requests automatically trigger tests found in the Jupyter notebooks. However, some tests are flickering. Thus, changes to the codebase while some tests failed are sometimes accepted.
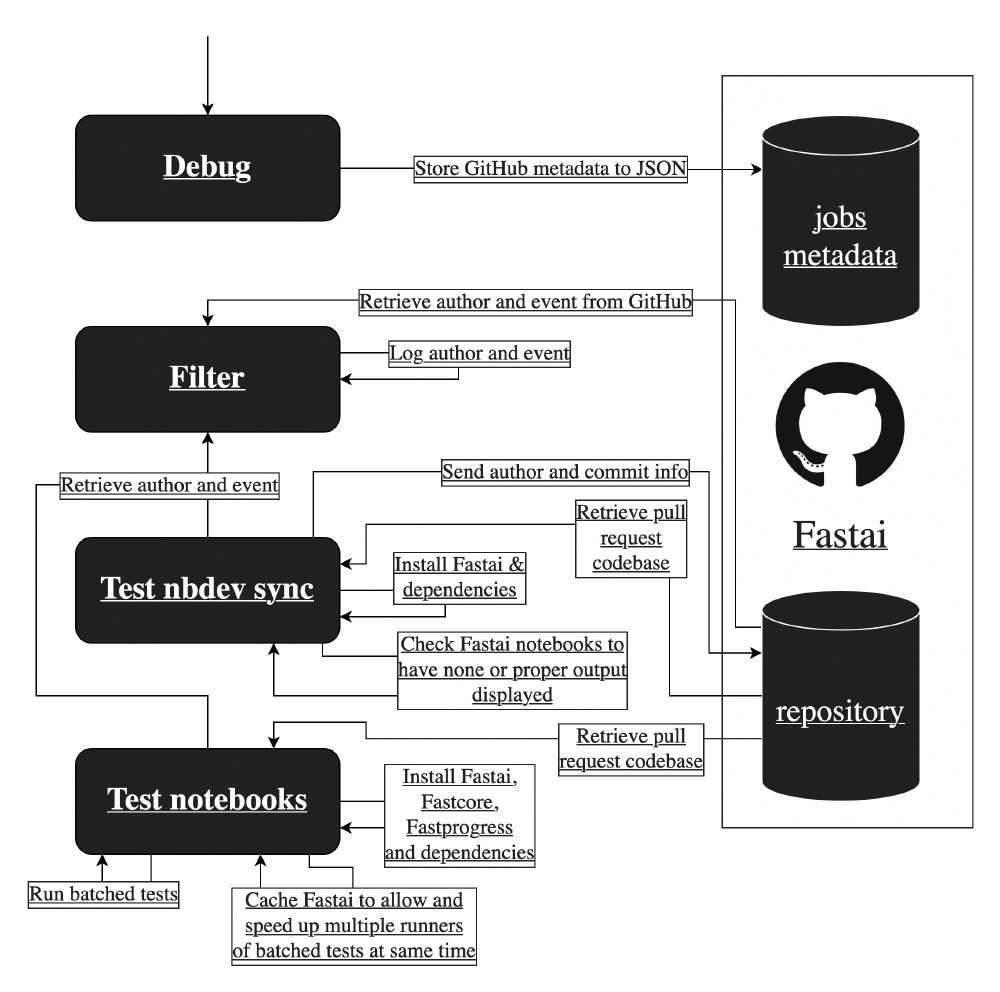
Figure: Continuous integration flow
We summarize the process that is run every time a pull request is created in the image Continuous integration flow. The events shown by arrows are run up to down, in a clockwise fashion. Since the project makes extensive use of Jupyter notebooks, pull requests often include irrelevant output. Jupyter notebooks create changes in the file when run. Thus the Continuous integration process is often stalled when changes made explicitly get mixed up with irrelevant changes automatically generated.
Changes to the library, which have gone through the process described by the image Continuous integration flow, are directly published on GitHub. Afterward, another flow is started that generates the API docs with the latest changes and pushes it to the API docs website.
Testing
Previously we discussed the continuous integration pipeline of fastai. We will now zoom into a particular part of the continuous integration: Test notebooks.
Fastai tries to take the tests one step further, integrating unit tests together with the notebook code. Fastai provides a few different test functions that cover most of the unit test scenarios. Next to these testing functions, fastai provides the nbdev_test_nbs3 hook, which can be run to discover the different tests implemented throughout the code. In figure “testing strategy” the general conversion from a Jupyter notebook (IPYNB) to python code is given. The processor filters the lines that have been annotated with test by the preprocessor to the tester component. In there the tests are executed and the result is collected in a test report.
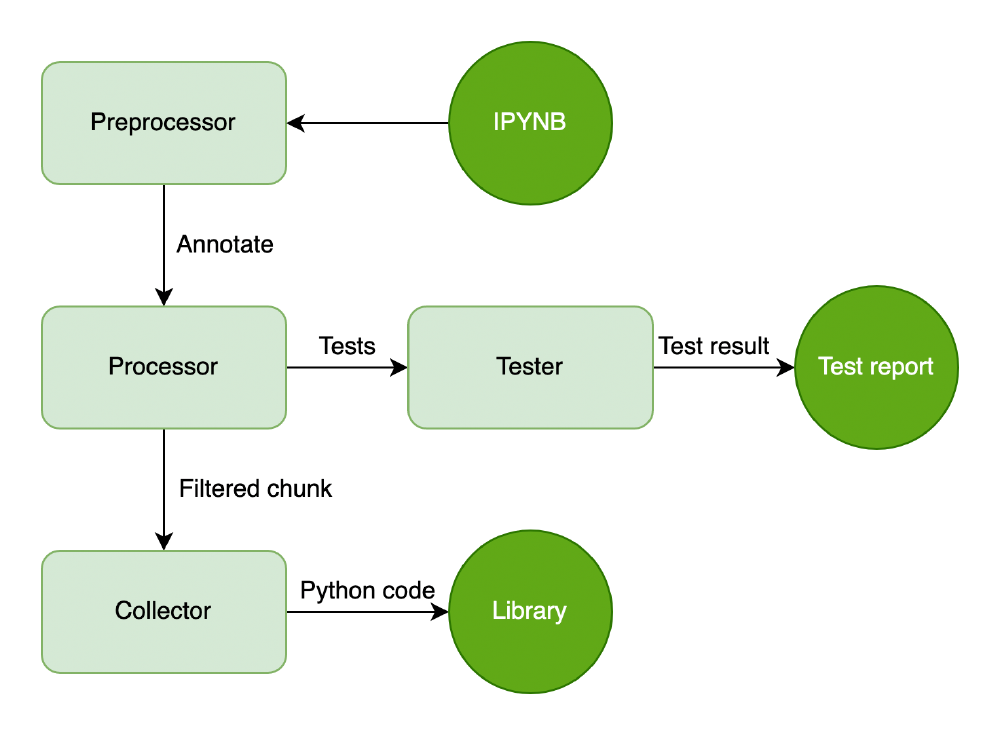
Figure: Testing strategy
Although the effort that fastai puts into allowing users to write tests is admirable, it immediately uncovers one of the biggest problems in the deep learning world: how to test. Testing in deep learning is often seen as model evaluation, verifying your dataset, or testing if your model has improved4. However standard software architecture principles are usually forgotten and code duplication, code coupling, and other code smells often arise in such architectures.
To conclude, fastai offers rudimentary testing functionality, which should be improved. As of the time of writing fastai mostly offers model validation tools.
Hotspot components
It is often the case that most of the development of a project is devoted to a few modules, hotspot components. To identify these modules we did a hotspot analysis, which consists of quantifying the number of changes for each module. The result of this analysis is visible below in the form of a heatmap.
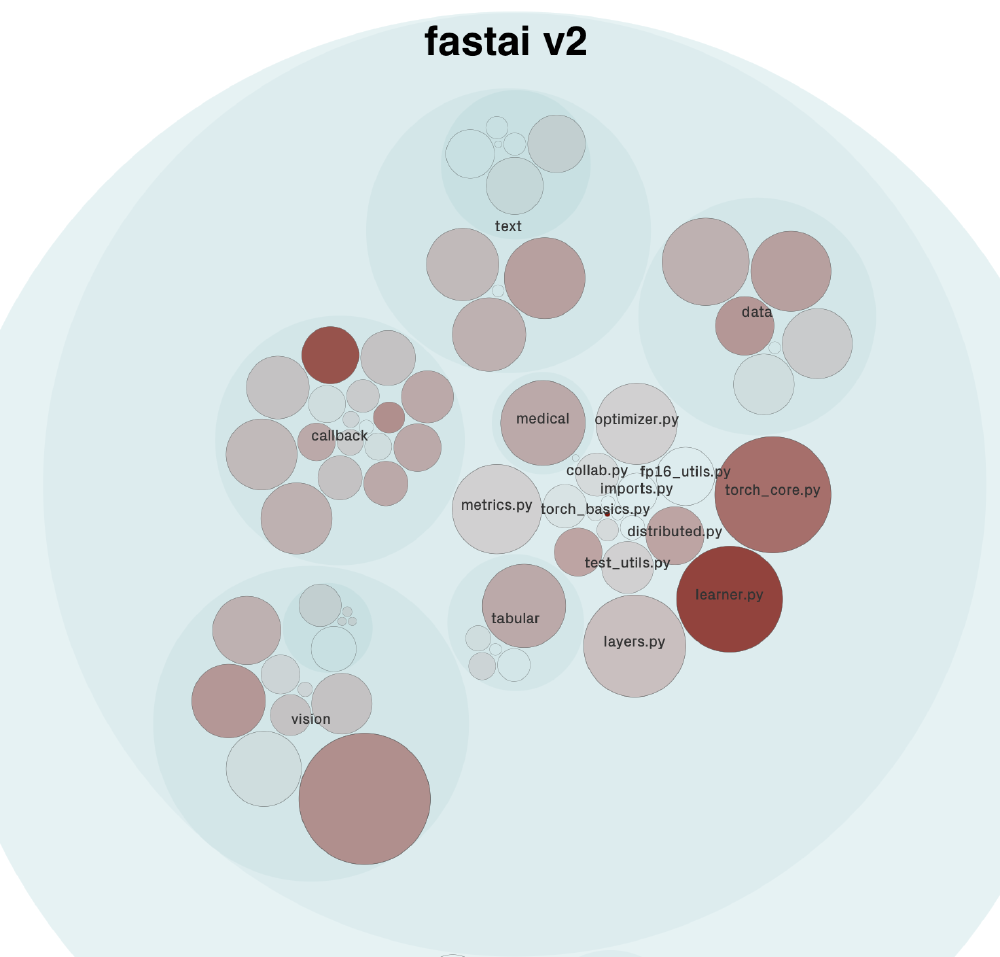
Figure: fastai v2 hotspot components from codescene.io
Each circle being named represents a component of the library. According to our analysis, the components in red represent about 64% of the development effort.
The two components having the most development activity are learner.py and torch_core.py. As the state-of-the-art models in machine learning evolve rapidly, it seems logical that the learner.py component is frequently updated. The torch_core.py is an essential module as “it contains all the basic functions [using pytorch], needed in other parts of fastai”5.
After investigating the history of changes for both components it is interesting to see that the majority of changes are bug fixes. Being a hotspot component seems to be related to a high amount of bug fixes rather than architectural changes.
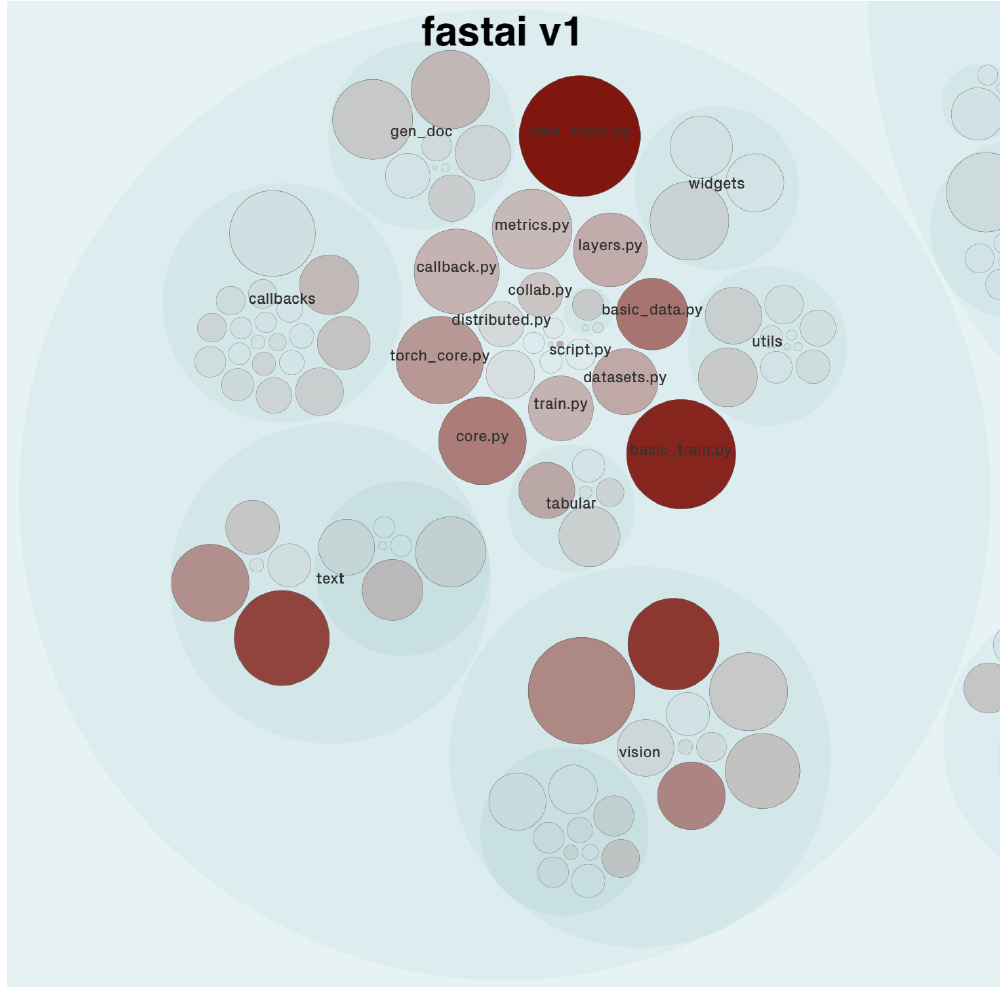
Figure: fastai v1 hotspot components from codescene.io
In fastai (v1) data_block.py and basic_train used to be the components with the highest development activity. However, in fastai (v2) data_block.py has been subdivided. The overall activity of the data component in fastai (v2) is about the same as the activity of data_block.py and basic_data.py combined in fastai (v1). basic_train is no longer part of the library. Apart from some small minor changes, the overall hotspot components have stayed the same between the two versions.
According to the roadmap of fastai6, the DataLoader, Learner, and Models components will be changed. We predict that the Models component stays active since new state-of-the-art models are published.
It is worth mentioning that, according to our analysis, the code health of some hotspot components is in decline. This decline mainly occurs in the modules callback and vision. The reason for this drop is the lack of encapsulation.
Code quality
There is not a singular definition for code quality. Tools exist that help the programmer get insights into the code quality, understanding the structure of the code, and raising awareness about possible issues. Tools like Coverity, SonarQube, or JArchitect offer ways to statically analyze the implemented code, explore its architecture, detect possible bugs and even estimate its technical debt.
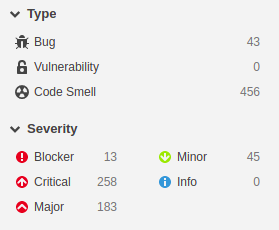
Figure: SonarQube code quality overview
Most of the code of fastai is written in Python, however, some parts are written in HTML, Javascript, and XML. For each one of these languages, SonarQube has a set of “rules” that are used to compute metrics like the amount of Bugs, Vulnerabilities, Code smells or Security Hotspots.
In the analysis that we have performed, 43 bugs were reported of which 13 are cataloged as ‘Blockers’. The majority of the 258 reported as ‘Critical’ refer to duplicated string literals in the code.
Despite having many reported issues for the whole fastai library, the detected hotspots files like learner.py or torch_core.py contain no serious reported bugs or vulnerabilities. They still have 11 and 15 code smells, respectively, but these are small issues related to the “wildcard imports” or calling specific “exception classes”. Roughly 70% of the found bugs are located in the docs_src folder which contains the web tutorials and web pages. The folder fastai has the main programmatic components of the library and has only 13 bugs evenly distributed among its sub-modules and this shows that the project complies with most of the expected code quality rules.
Quality culture
A good quality culture is necessary to achieve a high code quality. One aspect of quality culture is the number of active contributors. This shows a positive quality culture. Indeed according to 7, the median time an issue or pull request stays open is 8 hours, which is considered very short. Also, the percentage of open issues and pull requests are only 1%. In the last 5 years, more than 1300 issues have been solved.
To assess with more depth the quality culture of the library, we have selected ten issues as well as their pull requests and will analyze them below.
The first thing we observed in the selected issues, is that they do not adhere to the issue creation standards: 8 9 10 11 12 13 14 15. These issues are not reproducible. Even issues created by the founder of the library 13 14 15, do not have a proper description of the issue at hand. Also, there does not seem to be proper discussions for these issues, since they were immediately closed. Additionally, the founder of the library Jeremy Howard is almost the only person accepting or rejecting merge requests. Thus, making it an opinionated library that has considerable knowledge risk.
So, while these standards are not correctly followed, the team behind fastai put processes in place to ensure the quality can be maintained. The documentation of fastai is (mostly) up-to-date. A standard template for an issue is given which assists the user on GitHub to make reproducibility of the bug easier. There is are extensive contribution guidelines. A forum concerning the fastai library has been created. Thus, users can have in-depth discussions about the development of the library. Moreover, continuous integration is in place.
Technical debt
Another aspect of code quality is assessing the technical debt. SonarQube defines the technical debt as the “estimated time required to fix all maintainability issues or code smells”16. The technical debt is usually measured in hours but can be also translated to money and thus can be monitored by the development teams17. Static analysis using this tool was performed on the fastai library.
It states that around 9 days of technical debt was derived from 43 potential bugs and 456 code smells. These are many small issues like “wildcard imports” or a call of specific “exception classes”. It is mostly related to improving the understandability of the code. Each issue has an estimated time it should take to fix with possible fix suggestions. An example is the image Code smell Sonarqube which shows an issue in the learner.py file.
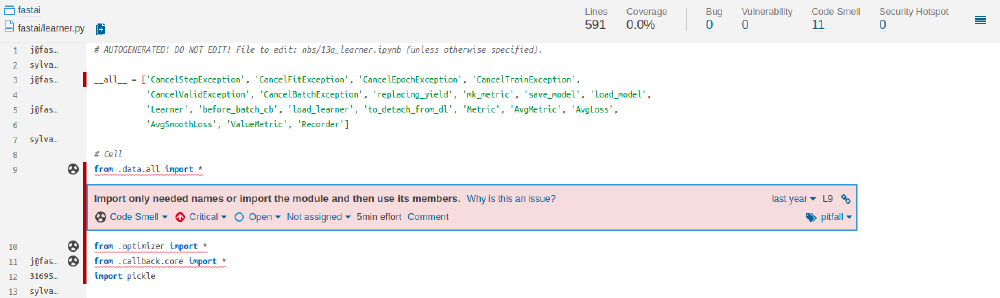
Figure: Code smell Sonarqube
This issue is misclassified by SonarQube since fastai intentionally imports everything with operation star. During runtime, fastai makes sure it only imports the specifically used imports.
Takeaways
The characteristics of the library make it difficult to assess the code quality. None of the tooling found online works properly for the expository programming use-case. Jupyter notebooks don’t have a defined standard for tests. Also, writing tests for Deep learning applications are in their infancy, there are little common standards. Continuous integration is applied but is error-prone. The community around fastai is active and errors are often identified and fixed. Thus its strength for evolution and quality lies with its contributors and not the tooling.
-
fastai docs (n.d.). Style. Retrieved March 19, 2021 from https://docs.fast.ai/dev/style.html ↩︎
-
medium swlh (October 10, 2019). CI vs CD vs CD — What Are The Key Differences? by Almasi. F. Retrieved March 19, 2021 fom https://medium.com/swlh/ci-vs-cd-vs-cd-e102c6dd88eb ↩︎
-
fastai docs (n.d.). Welcome to fastai. Retrieved March 19, 2021 from https://docs.fast.ai/ ↩︎
-
serokell.io (November 11, 2020). Machine Learning Testing: A Step to Perfection by Gavrilova Y. Serokell. Retrieved March 19, 2021 from https://serokell.io/blog/machine-learning-testing ↩︎
-
fastai (n.d.). fastai torch_core. Retrieved March 19, 2021 from https://fastai1.fast.ai/torch_core.html#Other-functionality ↩︎
-
fastai (n.d.). v2.3. Retrieved March 19, 2021 from https://github.com/fastai/fastai/projects/1 ↩︎
-
isitmaintained.com (n.d.). Fastai/Fastai - IS IT MAINTAINED? Retrieved March 19, 2021 from https://isitmaintained.com/project/fastai/fastai ↩︎
-
GitHub fastai/fastai (November 12, 2017). RuntimeError: received 0 items of ancdata #23 by kevinbird15. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/23 ↩︎
-
GitHub fastai/fastai (January 6, 2021). Promote NativeMixedPrecision to default MixedPrecision #3127 by jph00. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/3127 ↩︎
-
GitHub fastai/fastai (October 22, 2020). ImageDataLoaders num_workers >0 → RuntimeError: Cannot pickle CUDA storage; try pickling a CUDA tensor instead #2899 by dreamflasher. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/2899 ↩︎
-
GitHub fastai/fastai (September 6, 2018). System halted when calling model.fit #751 by geekan. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/751 ↩︎
-
GitHub fastai/fastai (September 7, 2020). Support persistent workers #2768 by jph00. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/2768 ↩︎
-
GitHub fastai/fastai (December 28, 2020). Add GradientClip callback #3107 by jph00. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/3107 ↩︎
-
GitHub fastai/fastai (December 23, 2020). New class method TensorBase.register_func to register types for torch_function #3097 by jph00. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/3097 ↩︎
-
GitHub fastai/fastai (December 23, 2020). Make native fp16 extensible with callbacks #3094 by jph00. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/3094 ↩︎
-
SonarQube Concepts. Retrieved March 19, 2021 from https://docs.sonarqube.org/latest/user-guide/concepts/ ↩︎
-
SQALE (n.d.). Software Quality Assessment based on Lifecycle Expectations. Retrieved March 19, 2021 from http://www.sqale.org/ ↩︎