Apache Kafka - Product Vision and Problem Analysis
The arrival of social media platforms, video streaming, and large-scale system monitoring services introduced new requirements for data processing, pushing the boundaries of available software at the time. Large amounts of data were continuously uploaded to and requested from servers1. Everyone rushed towards possible solutions: GraphQL, Caching, Localized servers and more were all brought to the table. The search for optimization had started. LinkedIn is one of these platforms that faced the problem. They went through multiple possible solutions and eventually settled on their own creation: Kafka2.
Kafka
Kafka is a distributed streaming platform with support for querying and aggregating its complete history. It aims to decouple processes that produce data and services that analyze and/or consume data. Decoupling the streaming of data from these processes and services ensures that the services and processes do not have to take messaging into account. There are other messaging systems that achieve decoupling, but what makes Kafka unique is its complete accessible history of streamed events.
Publish-subscribe system
Kafka is built on the pattern of a publish subscribe system, also known as pub-sub system, which is a system that adheres to the publish subscribe pattern3. The publish subscribe pattern is used to displace the overhead of sending messages from an individual publisher to a general broker. The broker will publish the message to the subscribers. This is often done through the use of topics, which are containers of similar events. A subscriber can subscribe to a topic in order to receive a message associated to that topic when the broker receives one.
Streaming
Streaming is a term that is used within computer science to state that the data handling is continuous. This means that Kafka runs as a continuous process. It not aimed at handling the data in batches, but rather send it through a pipeline such that a message is always on its way. This means that Kafka is capable of working in data intense application where new data is continuously generated. Kafka is capable of handling this amount of data because of its streaming architecture and scalability.
Scalability
Kafka is scalable. Being scalable in this case means that Kafka is capable of growing the amount of brokers when more throughput is required without being heavily impacted. It achieves this by writing records to disk and replicating this to other servers through the zero copy4 functionality that is available on most modern operating systems. Zero copy allows Kafka to copy data on the kernel level of an operating system. Operations on the kernel level require less processor cycles for execution which in turn means less overhead for the data transfer. Kafka is able to scale up the number of brokers without losing performance and data consistency.
Main Capabilities and Use Cases
Before Kafka was created, LinkedIn was using a batch-oriented file aggregation mechanism5. These files would then be copied to ETL(extract, transform, load) servers where they were further processed. The issue with this approach is that the data they would operate on was not real-time, since it had to be parsed and then saved into a relational data warehouse and Hadoop6 clusters. Hence LinkedIn created Kafka a real-time publish-subscribe system. With the creation of this system LinkedIn was able to use real-time data for its monitoring, security, machine learning pipelines and more. A bug that has been undetected by system metrics could be found by looking at the data, for example a decrease in sign-up rates. The core capabilities of Kafka are:
- high throughput
- scalability
- permanent storage
- high availability
The users profiting from this are the ones who use systems that function on these real-time high volume data. The official Kafka website mentions some use cases like: processing payments and financial transactions in real-time, tracking and monitoring cars, trucks, fleets, and shipments in real-time and more7. They also mention companies that make use of Kafka and how they use it8, companies like Rabobank who use it for Rabo Alerts. A service that alerts customers in real-time upon financial events. Another company mentioned is Netflix, who uses Kafka for real-time monitoring and event-processing.
System Context
Without a system like Kafka the consumer needed to directly talk to the source, and in some cases this communication would be going both directions, as many systems (databases, Hadoop) are both sources and destinations for data transfer. This meant you would be building two pipelines: one to insert data and one to retrieve data.
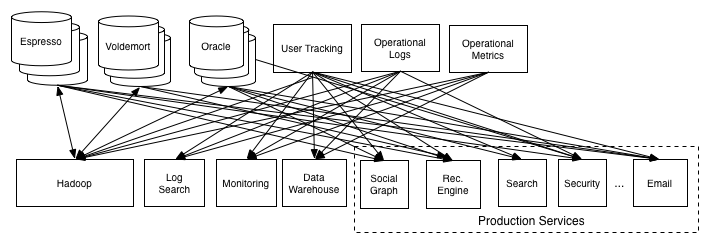
Figure: Complex pipelines where each consumer needs to communicate with the data source.
The idea was to isolate each consumer from the source of the data9. They should ideally integrate with just a single data repository that would give them access to all data. The idea is that adding a new data system means simply connecting it to a single pipeline instead of each consumer who needs the data. Now, Kafka fulfills the role of the unified log in the image below. A project builds on Kafka and eliminate the connections between all processes from the image above, both images are courtesy of LinkedIn5.
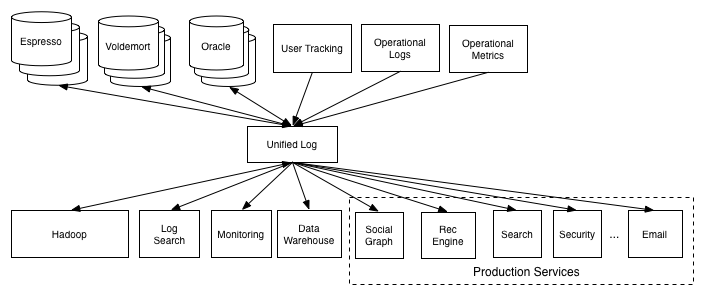
Figure: Simple pipelines where each consumer simply needs to communicate with a single data repository.
People can use Kafka to simplify their architecture, using Hadoop as an example; developers can send data from a Hadoop to Kafka and use this data easily within other data systems inside their environment.
Stakeholders
Kafka is one of the many open-source projects developed by the Apache Software Foundation (ASF) and used by many companies and applications8. The Apache Software Foundation builds upon the political system of meritocracy10, governing on the basis of individuals' abilities and achievements within the Apache Software Foundation, and has a governance structure with the following three main categories for identifying its stakeholders1112,
- Corporate Governance, managing The Apache Software Foundation, similar to how conventional corporations are managed.
- Technical Governance, managing the technical aspects of the projects and being the only ones with direct write access to project repositories.
- Non-Governance Groups, providing work and services for the projects and The Apache Software Foundation, but do not have any governance roles or write access to project repositories.
Each of said categories can be further categorized into individual stakeholders, depicted in the table below, with the category a stakeholder classifies at, the type of stakeholder, and its responsibility within The Apache Software Foundation and Kafka.
| Governance Category | Stakeholder | Responsibility |
|---|---|---|
| Corporate Governance | Members | Proposing Candidates, Voting in Elections |
| Corporate Governance | Board of Directors (board) | Setting Corporate Policies, Appointing Officers, Delegating Responsibilities |
| Corporate Governance | Project Management Committees (PMC) | Vote on Committers and Project Members |
| Corporate Governance | Executive Officers | Managing the Foundation, Monthly Status Reports for the board |
| Corporate Governance | Corporate Officers | Legal Affairs, Fundraising, Public Affairs |
| Corporate Governance | Board Committees | Legal Affairs, Security |
| Corporate Governance | President’s Committees | Managing Committees, Brand Management |
| Technical Governance | Project Management Committees (PMC) | Vote on Software Releases and Release Software, Elect Committers |
| Technical Governance | Committers | Commit to Projects (have write access to project repositories) |
| Non-Governance Groups | Contractors | Maintaining The Foundation (Security, SysAdmins, etc.) |
| Non-Governance Groups | Contributors | Contribute Patches and Source Code, File Issues, Test Code |
| Non-Governance Groups | Users | Using Kafka (LinkedIn Users, Netflix Users) |
| Non-Governance Groups | Developers | Using Kafka for Application Development (Developers at LinkedIn, Rabobank, PayPal, and many more8 ) |
| Non-Governance Groups | Sponsors | Sponsor Projects with Donations |
| Non-Governance Groups | Suppliers | Components Kafka depends on (ZooKeeper, JUnit, Log4j, Scala, Java, etc.) |
| Non-Governance Groups | Researchers (can also be members of other categories) | Using Kafka for Research |
Table 1: Categories of stakeholders and their roles in The Apache Software Foundation and Apache Kafka.
Any individual contributing to Apache projects will initially start out as a contributor, classified as a Non-Governance Group, since individuals can only contribute with pull-request, filing issues, or contributing on mailing lists. However, as the company’s governance relies on merit, with continuous contributions said individual can be elected to become a committer, at which point full write access of the project’s repository is granted to them. The change in stakeholder category also introduces new governing responsibilities, such as assessing pull-requests, contributing code directly, and reviewing code.
Quality Attributes
As big data processing is the main use case of Kafka in commercial applications, there are several quality requirements coming from the companies using Kafka, in order to maintain a good quality of service, high performance, and efficiency. Vergilio et al. [^13] presented 10 of the most important non-functional requirements for big data processing applications for companies such as Facebook, Twitter, and Netflix. Based on empirical research, emphasis in their research is on the implementation of real world applications and presents the following requirements,
- Batching of Data, being able to process data in groups.
- Streaming Data, being able to process infinite data streams.
- Out of Order Processing, being able to handle events that can be delayed by means of having a logical ordering on events.
- Processing Guarantees, guaranteeing that data will at some point be processed.
- Integration and Extensibility, being able to add new components or services to the system.
- Distribution and Scalability, being able to grow and distribute across multiple servers.
- Cloud Support and Elasticity, being able to be moved to cloud services, due the economic advantages of cloud services.
- Fault Tolerance, being able to continue operations after faults occur, since in real world applications faults will occur.
- Flow Control, being able to handle producers that are at some instances generating much more data than usual.
- Flexibility and Technology Agnosticism, being able to use different technologies in homogeneous technology environments.
All of said requirements apply differently to varying use cases of Kafka, as some applications might batch data for more network efficiency, while others do not batch for achieving lower latency, as producers do not need to wait for collecting enough data to fill a batch. However, Kafka delivering the implementation of these requirements with the possibility of configuring them to one’s needs, makes it a valuable framework for building big data processing applications.
Roadmap and Future Design
Kafka originated at LinkedIn around 2010. In 2011 Kafka was donated to the ASF, after development was open sourced. Kafka was turned into an active ASF project in late 2012. From the first versions, where Kafka aimed to be a scalable stream processing service outputting to Hadoop, it evolved, replacing and introducing many external dependencies with its own implementations and it continues to do so for the most optimal performance.
There is not a single roadmap for years to come for the Kafka project. Instead, changes are planned out in short-term releases13. These changes are time-based, where every four months a new release is planned. Features will be included when they are declared stable and are included based on suggestions by committers, mostly first published in Kafka Improvement Proposals14 (KIPs). If the features are not stable when the release time has come, the feature will be skipped and scheduled for the next release.
A very important long-term goal of Kafka is performant scaling15. For example, when adding brokers, the performance should scale linearly, this has not yet been achieved by the framework, due to some design limitations. If this is achieved, the system will be optimized for capacity, which is very desirable.
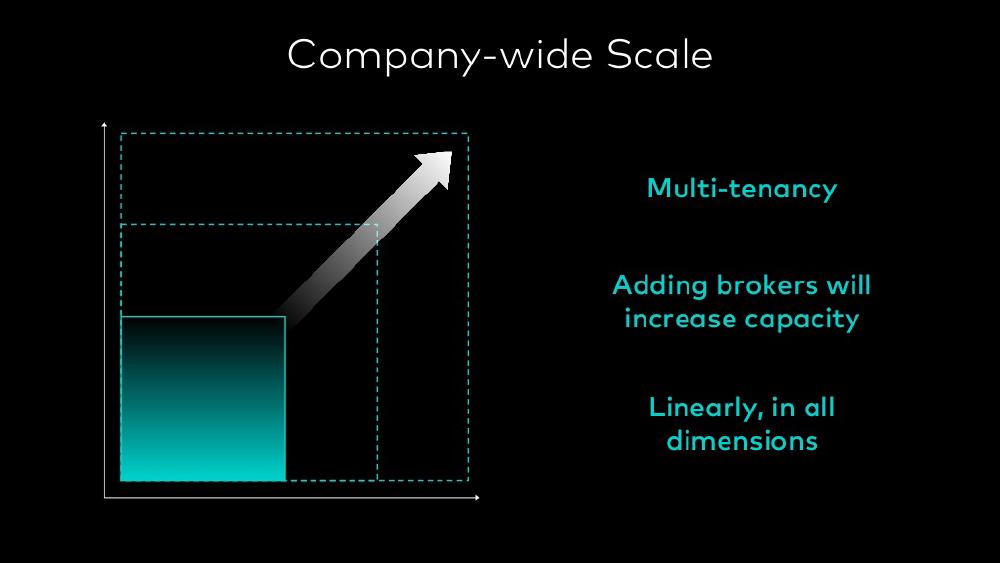
Figure: The linear scaling goal of Kafka
Besides improving the existing methods to scale external data from the users, there are plans to change the core storage of Kafka metadata. This is a large proposal KIP-50016, which describes how ZooKeeper could be replaced by a Kafka implementation of Raft17, a distributed consensus algorithm. This change will help Kafka metadata to be more scalable and more robust. Removal of an external dependency will also decrease the complexity of building and configuring Kafka. When looking at the current scaling, visible in the figure below18, and the linear scaling in the figure above15, we can see there are some improvements to be made.
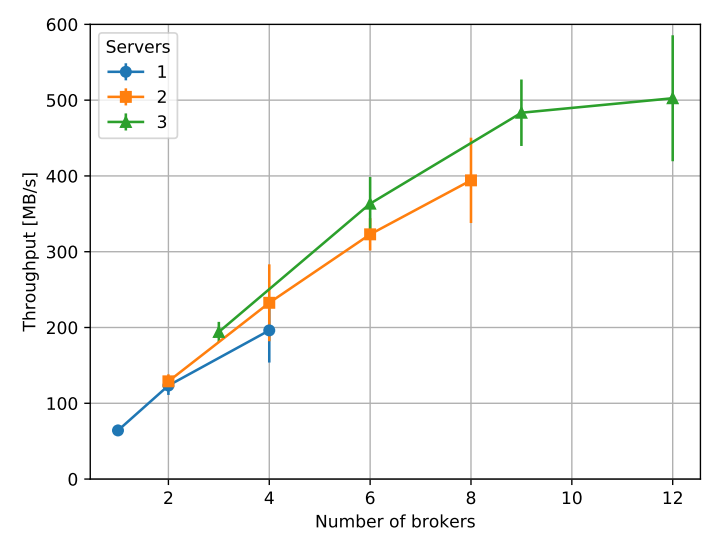
Figure: Performance of brokers on Kafka’s current infrastructure
Ethics of Kafka
Although Kafka is a tool that can be used as a foundation for many different programs and no direct ethical properties can be derived from its use, there are some things to be considered about the construction of the code. Looking at the core goal of Kafka, relieving the workload of a system by introduction of a broker, there is less communication overhead. With that, a faster system and less power consumption is achieved. Kafka is built by volunteering committers, who can freely submit Pull Requests. The open-source nature of the project and Apache’s code of conduct to be open, collaborative and inclusive19, is a good motivator for the code to evolve reliably and robustly. Reuse of code is in the committer’s favour, which helps the project in being accessible and maintainable. Overall, Kafka seems to be ethically sound as these last points conform to ACM’s code of ethics20.
References
-
How LinkedIn customizes Apache Kafka for 7 trillion messages per day, John lee, https://engineering.linkedin.com/blog/2019/apache-kafka-trillion-messages ↩︎
-
Kafka: a Distributed Messaging System for Log Processing (2011) http://pages.cs.wisc.edu/~akella/CS744/F17/838-CloudPapers/Kafka.pdf ↩︎
-
Publish/Subscribe - Encyclopedia of Database Systems, Hans-Arno Jacobsen, https://link.springer.com/referenceworkentry/10.1007%2F978-0-387-39940-9_1181 ↩︎
-
Efficient data transfer through zero copy, IBM, https://developer.ibm.com/languages/java/articles/j-zerocopy/ ↩︎
-
Building LinkedIn’s Real-time Activity Data Pipeline, http://sites.computer.org/debull/A12june/pipeline.pdf ↩︎
-
Apache Hadoop. a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. https://hadoop.apache.org/ ↩︎
-
Apache Kafka, What can I use event streaming for ? https://kafka.apache.org/intro#intro_usage ↩︎
-
Apache Kafka. Powered By. https://Kafka.apache.org/powered-by ↩︎
-
The Log: What every software engineer should know about real-time data’s unifying abstraction. https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying ↩︎
-
The Apache Software Foundation. What is the Apache Software Foundation?. http://www.apache.org/foundation/how-it-works.html ↩︎
-
The Apache Software Foundation. Apache Governance Overview. http://www.apache.org/foundation/governance/ ↩︎
-
The Apache Software Foundation. Apache Corporate Governance - Reporting Structure. http://www.apache.org/foundation/governance/orgchart ↩︎
-
M Maison (2021) Future Release Plan. https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=34841903 ↩︎
-
W. Carlson (2021) Kafka Improvement Proposals. https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Improvement+Proposals ↩︎
-
G. Shapira (2020) Kafka’s New Architecture | Kafka Summit 2020 Keynote. https://www.confluent.io/resources/Kafka-summit-2020/gwen-shapira-confluent-keynote-Kafkas-new-architecture/ ↩︎
-
C. McCabe (2020) KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum. https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum ↩︎
-
D. Ongaro and J. Ousterhout (2014) In Search of an Understandable Consensus Algorithm. (https://raft.github.io/raft.pdf) ↩︎
-
Mukai, A. et al (2018). Architecture of the data aggregation and streaming system for the European Spallation Source neutron instrument suite ↩︎
-
ASF (2019) Code Of Conduct. http://www.apache.org/foundation/policies/conduct ↩︎
-
ACM (2018) ACM Code of Ethics and Professional Conduct. https://www.acm.org/code-of-ethics ↩︎