PaddleOCR - An Elegant And Modular Architecture
This essay is going to research PaddleOCR from the perspective of its architecture. We first derive its architecture style - pipe-and-filter and blackboard patterns from its working mechanism. Then we illustrate the containers and components to describe their structure. Furthermore, we analyze PaddleOCR from development and run-time views. At last, we simply show some API design principles that PaddleOCR applies.
- PaddleOCR’s Architectural Style
- Trade-off! The Tricky Architecture
- Architecture Structure Design
- Development View
- Runtime. What Does It Look Like?
- API Design Principles
- Reference
PaddleOCR’s Architectural Style
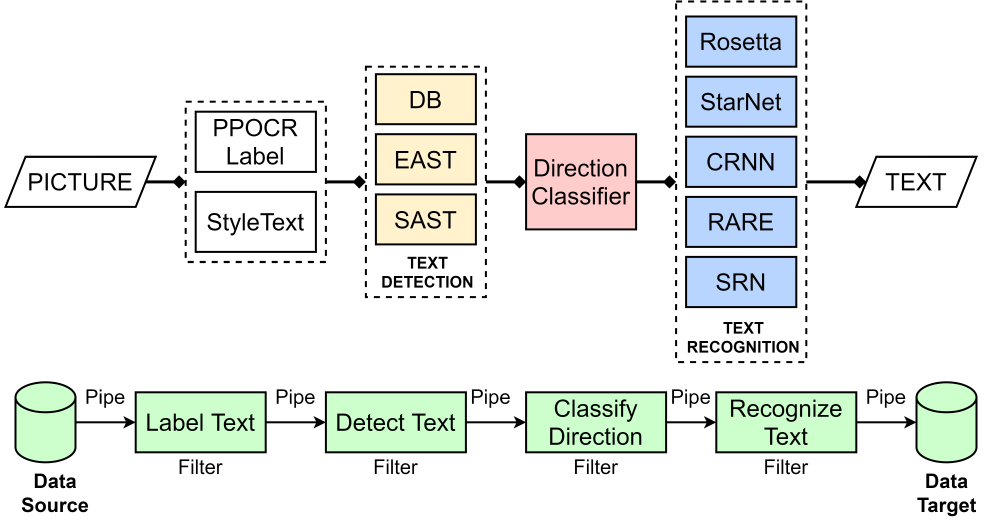
Figure: PaddleOCR Working Procedure
In the development of recognition software, there are two classic models - blackboard1 and pipe-and-filter. The blackboard model suits the open problem domain without deterministic solutions. The pipe-and-filter pattern extracts and processes data with sequential filters. Based on research and analysis, we believe that PaddleOCR adopts both of them and reaches a great integration.
As you can easily imagine, when PaddleOCR gets one picture, it cannot identify the language, direction, or position of characters. Firstly, Baidu engineers divide the procedure of processing a picture into text detection, direction classification, and recognition, where the pipe-and-filter model works. These developers also design and control diverse models corresponding with the knowledge source in blackboard to get an approximate solution with various algorithms. By utilizing these two models, PaddleOCR converts original data (picture) into advanced structures (texts).
Furthermore, in PaddleOCR, various algorithms are applied to solve one partial problem like text recognition. The mechanism of the blackboard model perfectly satisfies the demand for applying multi-algorithms to address one partial problem. As shown in the figure below, each participant agent in this model has its own expertise and solving-knowledge (knowledge source) that is applicable to a part of the problem. Blackboard allows multiple processes (or agents) to communicate with the global database by reading and writing requests and information. Agents communicate strictly through a common blackboard whose contents are visible to all agents. Just like the blackboard in the classroom, when a partial problem is to be solved, candidate agents that can possibly handle it are listed. The aforementioned mechanism not only enables algorithms to use others’ results but helps PaddleOCR to select the best result among many algorithms in one step.
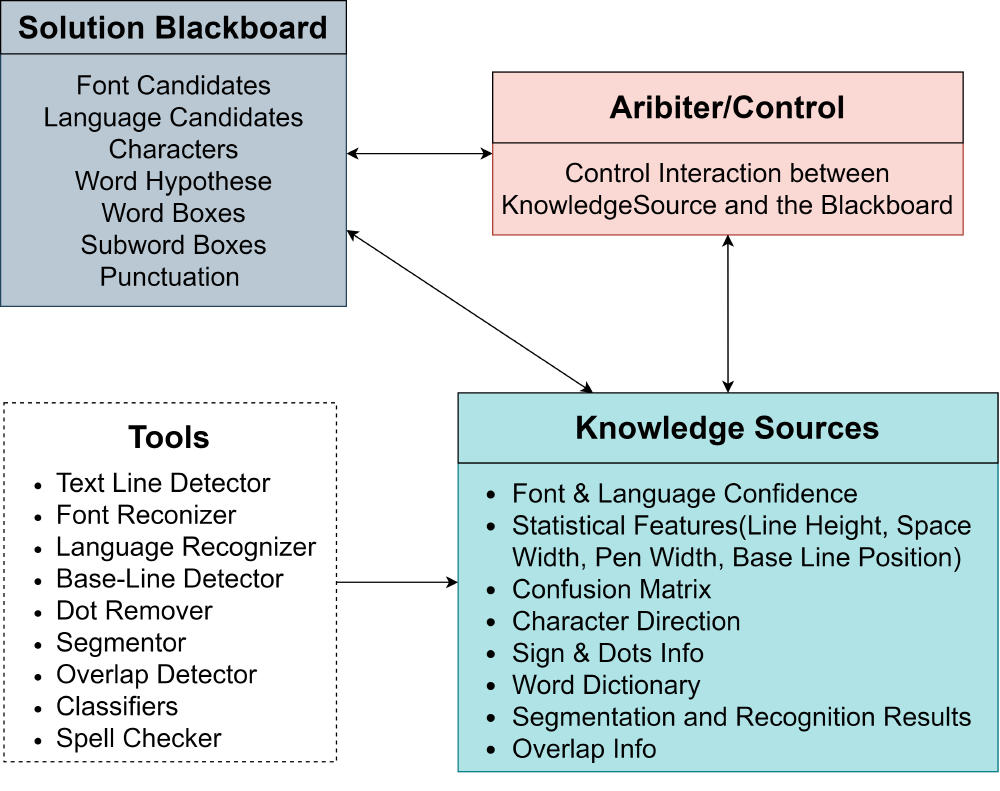
Figure: Architectural Features and Quality of PaddleOCR
Trade-off! The Tricky Architecture
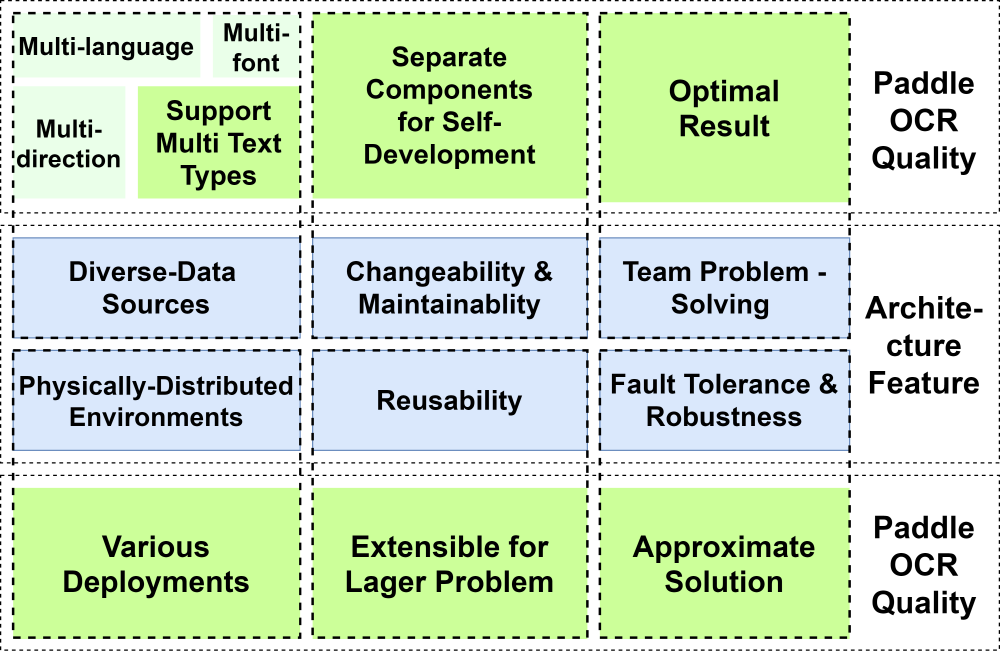
Figure: Architecture Quality and PaddleOCR’s Features
From the perspective of pattern features, blackboard and pipe-and-filter architectures share the core concept to separate the components, which endows PaddleOCR with re-usability, maintainability, and changeability for further extension. The figure above is our analysis of the key qualities of PaddleOCR contributed by the architectural style.
As for the trade-offs in designing architectures, we visualize it in the below picture. The main compromise is between accuracy and speed. In the blackboard model, multiple algorithms are applied to process data and obtain the optimal result, which guarantees the solution’s quality and robustness.
The efficiency gain in the pipe-and-filter pattern by parallel processing is often an illusion. Not only data transformation overhead between filters may be relatively high compared to the cost of the computation, but also the slowest filter determines the speed of the whole pipeline.
All former architectural features bring the computational overhead and low efficiency, limiting the response time. Baidu developers did not merely adopt one algorithm to avoid this kind of a waste but focused on polishing algorithms. In other words, the deficiency in the architecture model is offset by advanced algorithms and code, which requires developers’ great devotion. And in paper1, we see that the PaddleOCR developers successfully proposed an 8.4 MB ultra-lightweight model, which strikes a balance between speed and accuracy.
Furthermore, PaddleOCR can be simply viewed as a data-processing tool with pictures as inputs and texts as output rather than a highly-interactive software. The weak interaction is the shortcoming of the blackboard and pip-and-filter pattern. However, it does not bother PaddleOCR users as they only get the text as outputs.
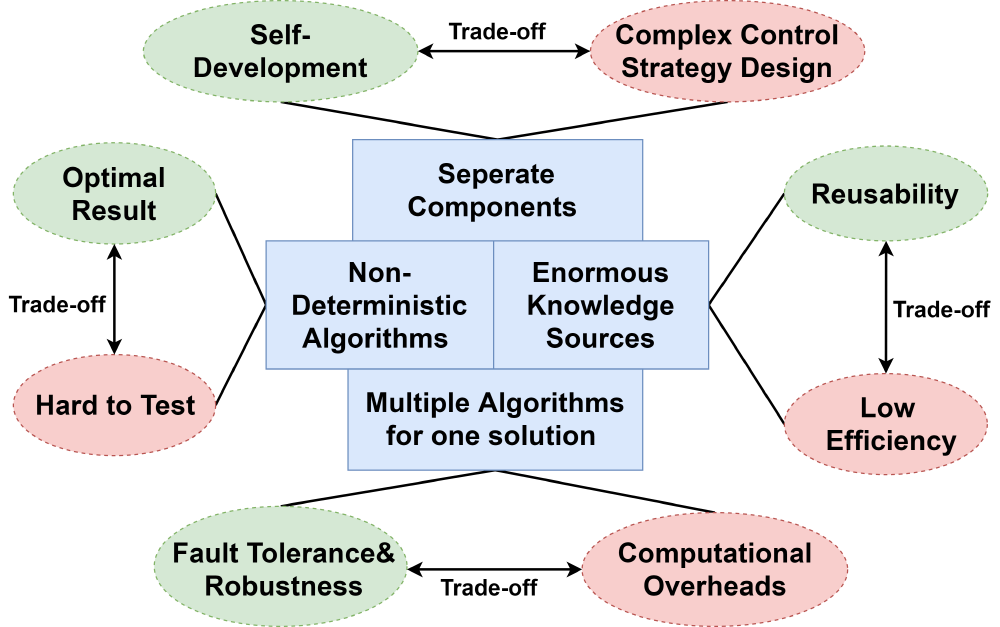
Figure: Trade-off in Modular Architecture Style Design
Architecture structure design
After the description of the main architectural style of the Paddle OCR system, we use part of the C4 model4 to visualize the architecture structure, from two aspects - containers and components. The C4 model reflects the main idea of the software system.
Container: Server and Mobile
Firstly we introduced the container diagram of the PaddleOCR software system. PaddleOCR currently has two deployments - server and mobile. Based on these deployments we drew the container diagrams.
The right part of the diagram is the model training procedure where users are able to provide their own dictionary and transform the data format by adopting the python script provided. Users are also allowed to choose the lcdar2015 data set to train the model. After input of the training set, the model will calculate the loss and pass it to the optimizer, while the user can modify the hyperparameter in the optimizer to control the learning rate, regularize and optimize the loss function. And the optimizer will pass the optimal estimate parameter to the training model. Since we get the fully trained model, we can deploy the trained model to the PaddleHub server or the mobile.
The left part of the diagram focuses on the mobile and server deployments. Paddle-Lite is used for mobile side deployment, we can get the prediction results in our own mobile. Since we still transfer the inference model to our mobile device, either we can download the inference model from the library or use the model that we trained ourselves. Users are allowed to push the original figures to mobile devices, then users can only get text results.
In contrast with the ultra-lightweight quality that PaddleOCR has, the server deployment is designed for a faster recognition speed and remote computing, where users are able to send images as prediction requests and get the results from the Hub server. The blue dotted line expresses the possible mobile application which does not include the inference model but users can utilize the model within the server.
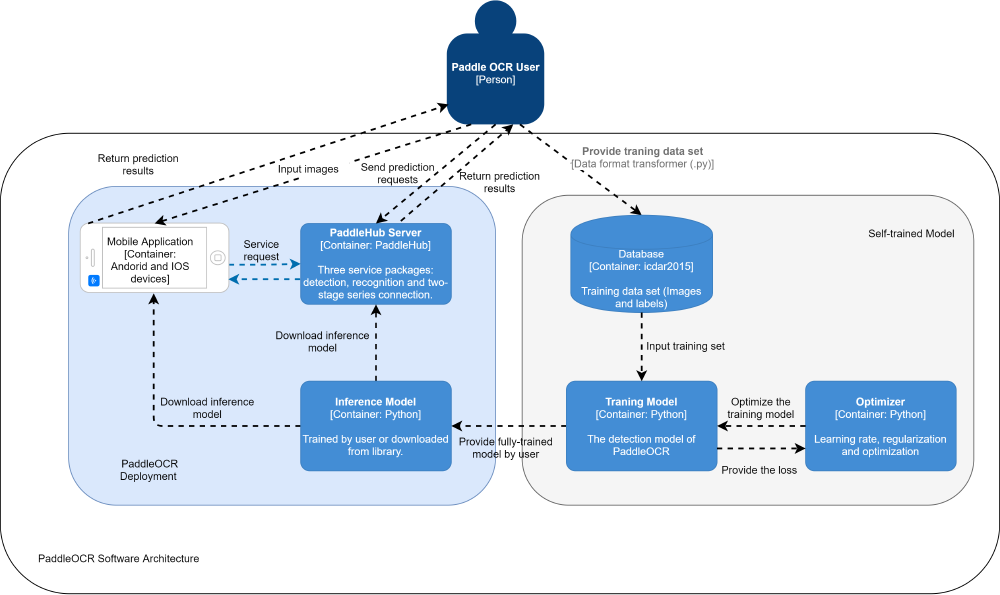
Figure: PaddleOCR Container Diagram
Component & Connector
The PaddleHub server includes detection, angle class, and recognition components. Compared to the server deployment, the mobile application with no need for these components.
From the perspective of component, the mobile side deployment has no inference model, cannot be used for the local text recognition, but provides a user interface and image storage. The network port builds a transmission between users and the server.
For the training model, loss analysis returns the result to the modelling component and guides how to adjust parameters. A model evaluation result will be produced through the test path.
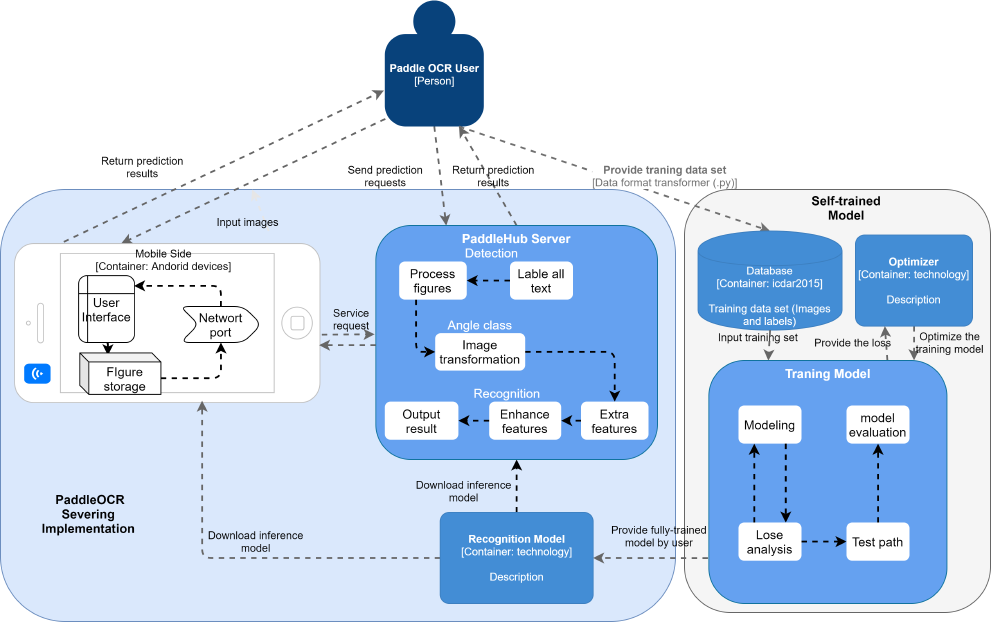
Figure: PaddleOCR Component Diagram
The software connectors perform the transfer of control and data among components9. The connectors between PaddleHub server components, mobile side, and training model components are well-defined software interfaces. All information will be passed to the next component through the interface after being processed.
Inside the self-trained model, software interfaces are the connectors between the model and deployment. The download of the model is data transmission through the network, as well as the service request.
Development View: Data flows through modules
Normally, when developing software, the developers always break the whole architecture into several blocks/modules to make them become modular architecture. Such modularization has two great advantages. On the one hand, it simplifies management. On the other hand, it extends the scope of application - any single module can be applied to another software within a few modifications. PaddleOCR also applies this scheme.
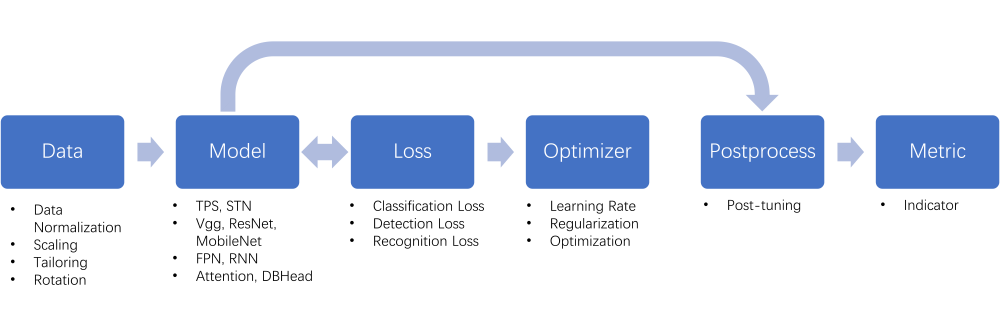
Figure: PaddleOCR Module Overview
The structure of PaddleOCR can be mainly divided into 6 modules, presented in the above figures, including data, model, loss, optimizer, post-process and metric. There are two propagating paths, one for training and another one for testing.
As for the training path, initially, the data module loads and pre-processes the raw images including but not limited to data normalization, data argumentation, and filtering. After that, the model module enhances and locates the features/information in the images and then extract them out using various algorithms. Those features/information will be compared with the labels by the loss module, and the module will return the classification loss, the detection loss, and the recognition loss backwards to the former modules for training the parameters. The optimizer module is controlled manually, where users can modify the hyper-parameters to determine the decay of learning rate, the global regularizer, and the type of optimizers. If a model is well-trained, it will pass all its parameters to the postprocess module for deeper pruning.
Comparing the testing path with the training path, the main differences are 1) the trained parameters and hyper-parameters are fixed now; 2) the predictions will be converted to the metric module rather than the loss module for the model evaluation. The report will give feedback on the performances of the model in detail, such as the F-score and accuracy for different algorithms.
Runtime, What does it look like?
The runtime view shows how system components interact at runtime3 to realize the application of key scenarios. The two main usage scenarios of PaddleOCR are server deployment and mobile side deployment. Considering their overlap, this section explores how a server deployment PaddleOCR serves as a user.
In server deployment, users will directly interact with the OCR service client and import one or more pictures to the client. The network interface of the client uploads pictures to the server where the PaddleOCR system has already been deployed. The detection component in the system processes the picture by locating texts and generating labels at corresponding positions. The angle class component performs image transformation. The recognition component extracts and enhances the features of the processed image, then returns the result to the server client.
As for the mobile-side deployment, the components in Server will be replaced with smaller packages and integrated into the OCR Server Client.
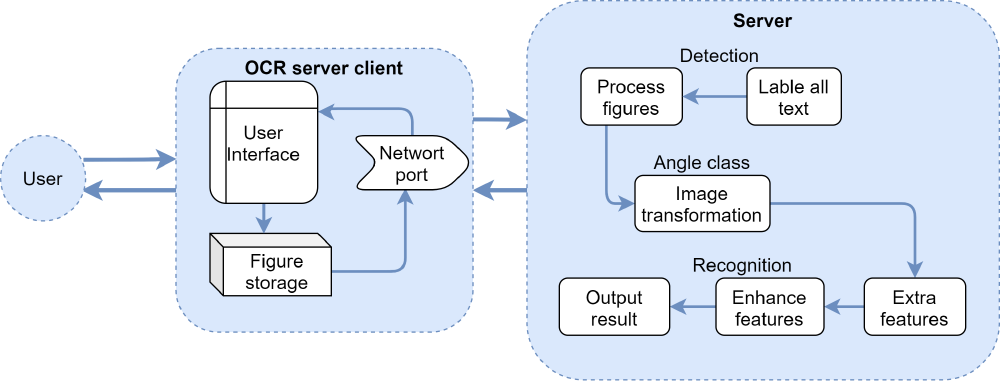
Figure: PaddleOCR Runtime View
From an architectural point of view, regardless of the application scenarios, the architectural design of PaddleOCR allows various model customizations. The system realizes optical character recognition through the following three service packages: detection, angle class, and recognition module service package. Users can freely choose the inference model or self-training model. This architecture design hides the complexity of applying OCR to pictures, simplifies the dependencies between components, and provides convenience to the user.
API Design Principles
This section will analyze the most significant 5 principles of PaddleOCR that contribute to its common and wide uses.
Explicit Interfaces Principle
In order to make the operations of calling more consistent and secure, the interfaces are implemented explicitly. The default global configuration can be modified in configs in which parameters relevant to cls (classification), det (detection) ,and rec (recognition) can be manually set by developers or users. The parameters can also be changed during implementation. For instance, using paddle.nn. can set the parameters for different neural networks.
Principle of Least Surprise
The model building, training, and utilization are similar to the mainstream deep learning software. Therefore, users and developers who are familiar with those conventional building tools such as TensorFlow can easily understand and use this architecture. For instance, if you want to build a 2D pooling layer, you can call tensorflow.nn.avg_pool2d() with TensorFlow, while you can call paddle.nn.AvgPool2D() when using Paddle similarly. In addition, some functions used in TensorFlow can be called paddle.Tensor..
Interface Segregation Principle
Since the general design obeys modularization, some components can be separated out easily and applied to other fields. We can see that the “Paddle” algorithm is not only used for PaddleOCR fields but some other fields like PaddleNLP. This designing principle significantly promotes the reusability of the architecture.
Uniform Access Principle
The naming scheme and the structure are both sensible. There is no syntactical difference between working with an attribute.
Design From Client’s Perspective
For different users and developers with various purposes, PaddleOCR provides different interfaces. In terms of libraries and frameworks, it provides both Python and CPP versions. Turning to operating systems, it can work on PCs (Windows and Linux) and mobile phones (Android and IOS). Furthermore, it currently has an initial hub server version, which also has a docker image version, offering a more powerful computation.
Reference
[1] Hossein Khosravi, Ehsanollah Kabir.“A blackboard approach towards integrated Farsi OCR system”. IJDAR (2009) 12:21–32.2009. (https://link-springer-com.tudelft.idm.oclc.org/article/10.1007/s10032-009-0079-7)
[2] Wikipedia: API
[4] C4 model diagram
[5] David Hutchison, Takeo Kanade, Josef Kittler, et al. “Software Architecture”. 5th European Conference, ECSA 2011. Sep. 2011.
[6] Juliana Freire. Emanuele Santos, et al. “The Architecture of Open Source Applications”. Jan. 2011.
[7] Buitinck L, Louppe G, Blondel M, et al. API design for machine learning software: experiences from the scikit-learn project. arXiv preprint arXiv:1309.0238, 2013.
[8] Yuning Du, Chenxia Li, Ruoyu Guo, et al.“PP-OCR: A Practical Ultra Lightweight OCR System”. arXiv:2009.09941v3 15 Oct 2020.