RustPython - Quality & Evolution
Hello again and welcome to our third blog on RustPython! Today we’ll be discussing the quality of the RustPython system, and how to protect it as the code evolves. For RustPython this is especially important as it is still in an early stage of its development, making clarity and technical debt hard to ignore. We’ll start by considering what the essential software quality processes are for RustPython, describe how it ensures these (hint: Continuous Integration is involved), and then look at the current quality of the code and the culture behind it. Then we’ll delve into some of the more active and complicated parts (so called hotspots) and how they may become either aids or blockades in the future of the project.
Hope you enjoy!

Figure: What happens when you don’t look at software quality
Maintaining Quality
Quality is not an act, it is a habit. ― Aristotle
When you’re coding a project, it’s all too easy to fall out of good coding practices. Perhaps this function will run with a “quick and dirty fix,” or you just spent an entire night hacking on a new feature and don’t care if the code along with it looks ugly. On itself these occasions are usually not a problem, but they accumulate and increase the amount of effort and time that has to be put in to keep things working in the long run.
To keep the codebase from degrading, we make use of both codes of conduct and static analysis to keep it in pristine conditions. Some statistics about the current codebase:
-
RustPython has a code coverage of 64%, focusing on hotspot components (we’ll go into those below!)
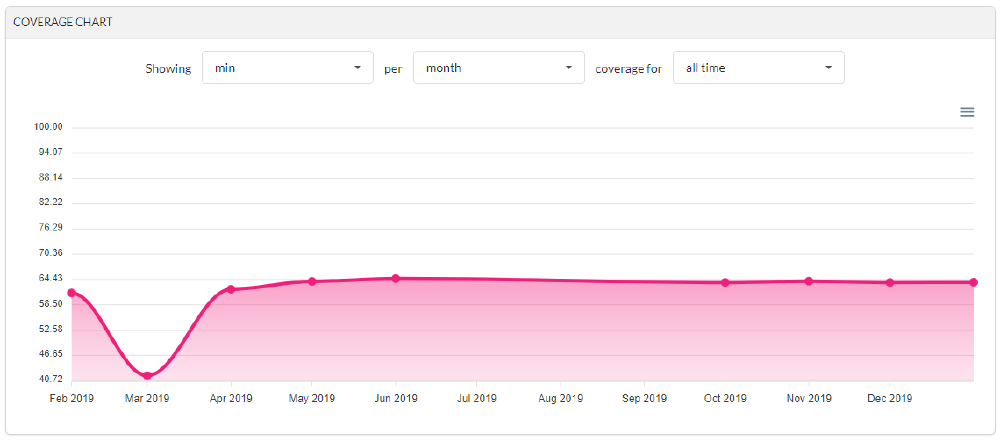
Figure: The code coverage of RustPython over its history https://app.codecov.io/gh/RustPython/RustPython/
-
Functions are all very small with a low cyclomatic complexity as computed by rust-code-analysis
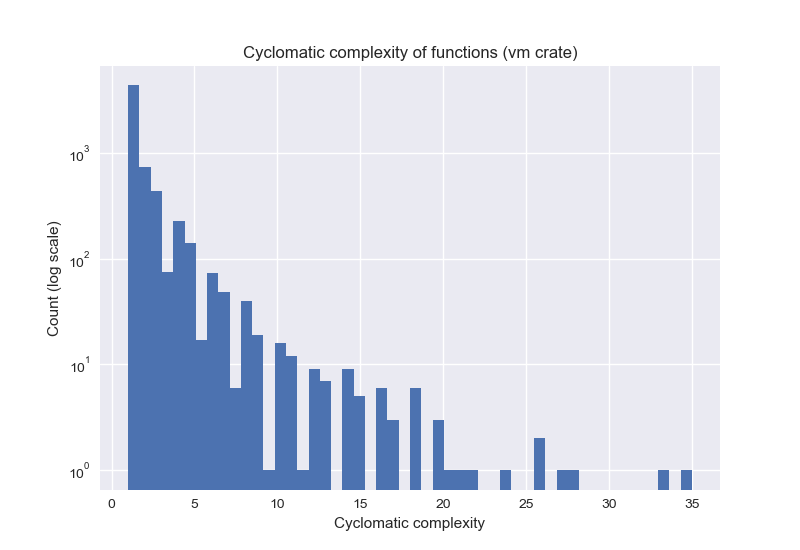
Figure: Distribution of cyclomatic complexity of the vm sub-crate. Note the log scale on the y-axis.
- There are 14 files with more than 1000 LOC, of which the largest has more than 3000, something which can make the code hard to oversee.
The main problems with the current structure in the RustPython repository is the length of specific files. Although this might be a specific problem of an interpreter, efforts need to be made to minimize the length for new files as well. This improves or at least ensures the same level of maintainability. The reusability aspects are much better handled in RustPython, as the parser, compiler and VM can clearly be separated.
Contribution Process
“If 10 years from now, when you are doing something quick and dirty, you suddenly visualize that I am looking over your shoulders and say to yourself: ‘Dijkstra would not have liked this’, well that would be enough immortality for me.” ― Edsger Dijkstra
To gain some insights into the quality procedures and their effectiveness, let’s walk through all the steps of adding a new feature, from creating the initial issue to passing the code review from maintainers.
Creating the initial issue
Issues that are architecturally significant are usually opened by core contributors and maintainers of the project, using labelling to indicate what it is for. Depending on the significance, there is a moderate amount of discussion. Unfortunately, the usage of issue templates is not widespread yet, there is not a clear determination of which individual components need to be implemented.
After having created the issue, you create a branch that has a clear name in which you can start working. To clarify that you have taken this issue into your hands, contributors usually open a pull request.
Opening a Pull Request
Ideally, the PR you open, especially when it is for a major feature, should be correctly labeled and follow a template. Because RustPython is maintained by only a few core contributors there is not always an effort made to clarify the PR beyond the code written. Another oversight we have seen is that issues are not referenced and thus remain open when the PR is merged, though that is usually remedied over time.
Frequently you will have to include tests, and those are also discussed along with their impact on the code coverage and performance. How are those visible? Well, that brings us to the CI!
Before that however, the code that you are contributing has to compile and be formatted, which follows some stringent standards:
- Rust code has to compile, and for code to compile it has to be
- Syntactically correct
- Unambiguous on ownership throughout the entire code
- Formatted according to rustfmt’s style guideline
- Without any of the 400 code smells that clippy can detect
- Python code has to pass through the
- Opinionated black formatter to be formatted according to PEP8
- Flake linter, to find common python code smells like unused variables
Then, on a project as large as RustPython (and with 40,000 significant lines of Rust and 300,000 lines of Python, it is quite large), the CI has quite a few steps in it, let’s dive in for a closer look.
The Continuous Integration Pipeline
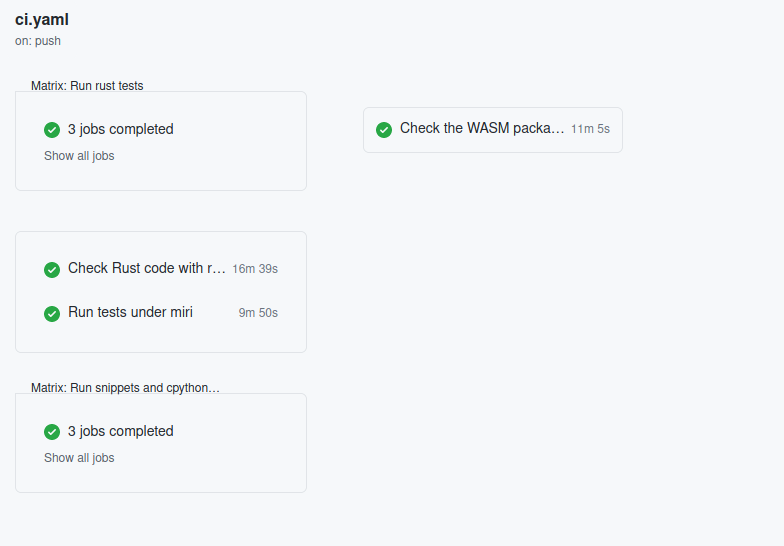
Figure: The summary of the CI pipeline
As shown above, there are four ‘parts’ to the CI pipeline. What do each of these do?
Running the Rust tests runs all the (integrated) tests of the packages along with calculating statistics like code coverage and performance. In Rust, tests are usually not defined in separate files, but instead are defined as submodules, or even within the documentation.
Testing Intermediate bytecode is done through Miri, and goes over Rusts mid-level intermediate representation (MIR) to “detect certain classes of undefined behaviour” like leaving memory allocated at the end of execution.
Testing the python code against CPython makes sure that the python code that is written can still hold up against a standard interpreter, and doesn’t require special conversion.
Checking the WASM package tests whether the RustPython package can still be exported to a WASM package without issues.
Review & Merge
There will always be at least one, usually two others that review the PR before it can be merged, and they will comment both about the style of the coding and potential issues they can spot. If the code coverage is increased by the PR, then that is usually also discussed.
Now, having looked at the contribution process, which files are most often the target of these contributions and do they hold up well as a result? Indeed, it’s time for hotspot components!
Hotspot Components
“Talk is cheap. Show me the code.” ― Linus Torvalds
In any library, there are parts that subject to more change than others, usually in a kind of exponential function. We visualized these components by going over all the commits and constructing a so called wordcloud:

Figure: Wordcloud representing how often files are changed.
The larger a word is in this cloud, the more commits make changes to the file. Let’s go over some of the largest: pyobject, vm, and builtins .
Current Hotspots
The pyobject file contains the Rust representation of a Python object. As per the implementation, each object is represented by a distinct class. This representation is one reason why edits were often needed, as new or optimized ways of object features were often added. A reason for why this file is difficult to split is that it serves a single purpose.
The vm file contains the Rust implementation of the virtual machine running the given instructions. As this file contains all of the possible instructions available to the user, its modifications are frequent. New instructions or optimized variants were often added. As the different operations are hard to group together, splitting the vm file into smaller parts will also not work well.
The builtins file was a file that represented all the built in functions available to Python. This includes functions, tuples or other operations. As this file was very large and kept growing through its frequent edits, it was split into multiple files (43 currently). Each file represents the Rust implementation of a specific Python function like zip or int.
Future Hotspots
The future of RustPython mainly resolves around writing a full Python-3 environment entirely in Rust, meaning that eventually there would be no need for CPython bindings. Many changes are still required for the vm which will most likely remain a hotspot because of this. A newcomer as hotspot component could be threading which is in need of quite a bit of optimization, most likely through restructuring. In addition a garbage collecting gc is not yet implemented and will likely take up a large number of commits.
So what does having all these hotspots mean for a codebase? The more convoluted and harder to understand a project becomes, the more it increases technical debt. In the next section, we’ll discuss some of the more pressing debts that RustPython is gaining and how these can be approached.
Technical Debt
“Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live.” ― John Woods
Technical debt is, in its essence, the answer to the question ‘how hard is it to add a new feature to my codebase?’ As code becomes more complicated and less well documented and just generally less well understood, this difficulty increases, till eventually you reach the state shown below.

For RustPython we have three key debts that we can look at: documentation, code quality, and test debt.
Documentation Debt
There is very little documentation at the moment, with a documentation coverage of less than 10%. Recently we opened an issue about this with more detailed statistics. On top of that there is a separate need to expand the manual for using RustPython, which only has one brief page at the moment. On a shorter timescale, an architecture.md file could help potential contributors understand the project and get started. We’ll talk about that more in our next essay. 😉
Code Quality Debt
As we mentioned before, there are some very large files in the project which is a detriment to quality in general. However, due to the code quality checks and the inherent code style associated with Rust the codebase is mostly free of code smells and of good quality.
Test Debt
As we mentioned at the start of the blog, the current code coverage of RustPython is 64%, which, while not bad, is certainly not up to standard.
Recap
Through this blog, we hope that we explained the code quality culture of the RustPython package, what processes it uses to maintain quality, and what technical debt it has piled on over its development. We have outlined what steps can be taken to decrease technical debt and how to help future contributors in understanding and maintaining the code base.
If you have any remaining questions, feel free to contact us!