Deep Learning libraries like PyTorch, Keras, and Tensorflow help us in creating Deep Learning solutions. However, none of them cater to its users as fastai. fastai is made with ease of use in mind. This is achieved by incorporating parts of other libraries and then adding (abstraction) layers on top of that, such that the user can start quickly, without having to write elaborate code and familiarize itself with too many deep learning details.
In this post, we present an architectural overview, where we look at how stakeholders interact with the system at Architectural style. Afterward, we look at the environment of the system in the section Containers view. Next, we take a look at the structural components of the system its connections between these components in the Components view and Connectors view. Then the decomposition of the system of the found modules and their dependencies in the Development view. Moreover, we look at the interactions of components at run time in run time view. Lastly, we look at the trade-offs for chosen implementation and how the API design principles are applied.
Architectural style
Fastai at its core tries to be user-friendly, where its user can pick and choose components and extend where necessary. Thus a three-layered, modular architecture was chosen as is shown in the image System context.
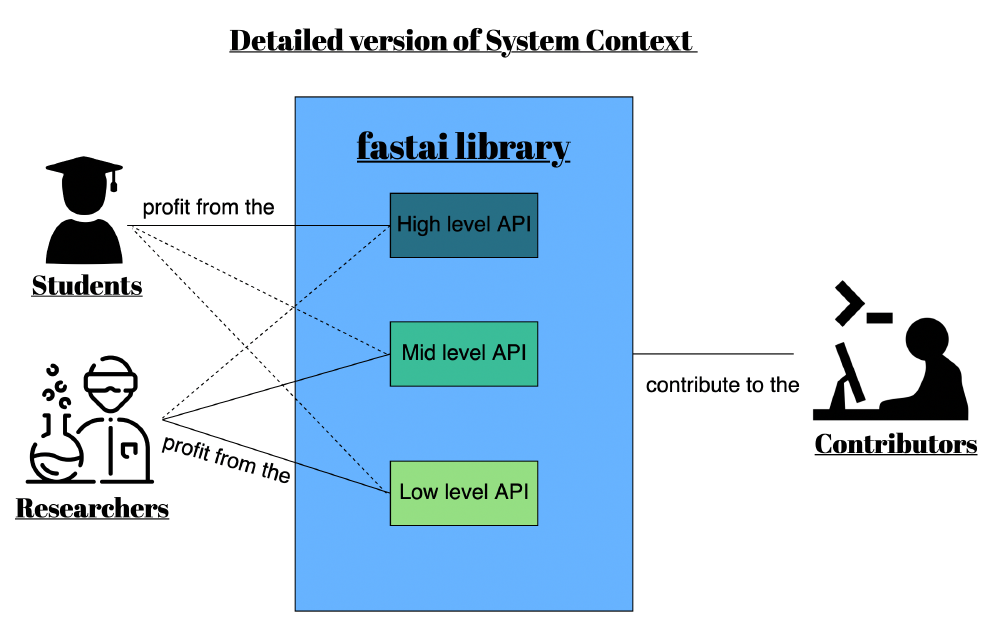
Figure: System context
The high-level API is catered to beginners and professionals that want to apply and/or repurpose pre-defined deep learning architecture and models. This API level uses, where possible, default values, which allows the user not to worry about many implementation details.
The mid-level API contains the core deep learning and data-processing methods and models for the five chosen applications. The main purpose of this level is to add abstractions for common low-level API use-cases.
The low-level API is basically connecting together many data science and machine learning packages such as Numpy, Pandas, Spacy, Scikit, Scipy, and Torch.
This architecture allows a completely different level of use to different types of users. “A user can create and train a state-of-the-art vision model using transfer learning with four understandable lines of code."1. Moreover, users can quickly set up a baseline or extend the library using their custom implementation.
Container view
The main execution environment is mixed. All the code is written in Jupyter Notebooks and converted by nbdev (an open-source library made by fast.ai) into a Python package. When executing such a Notebook, the Python package is imported such that we can make use of the whole library.
Component view
Fastai tries to apply industry standards and common best practices. Therefore individual components adhere to standards like naming conventions. Thus a user that comes from a different library will be able to quickly get used to the fastai library, furthermore Huffman encoding principles are applied to keep short and recognizable variable names, such as lm for language model and tfm for transform 2.
As mentioned in the previous section, fastai makes use of nbdev. Nbdev can convert Jupyter notebooks into raw Python code, furthermore can to stitch multiple notebooks together thereby making a package of python files that can be deployed as a library. Fastai is thus a composition of different Jupyter notebooks building upon each other, which allows for expository programming, while not loosing the benefits of the Python language. Expository programming is a programming style where a user can delve into the code just like a scientist’s journal and observe all the experiments that a developer has tried 3. Every notebook contains rich documentation accompanied which simple tests and examples in order to illustrate how to use each module of the library.
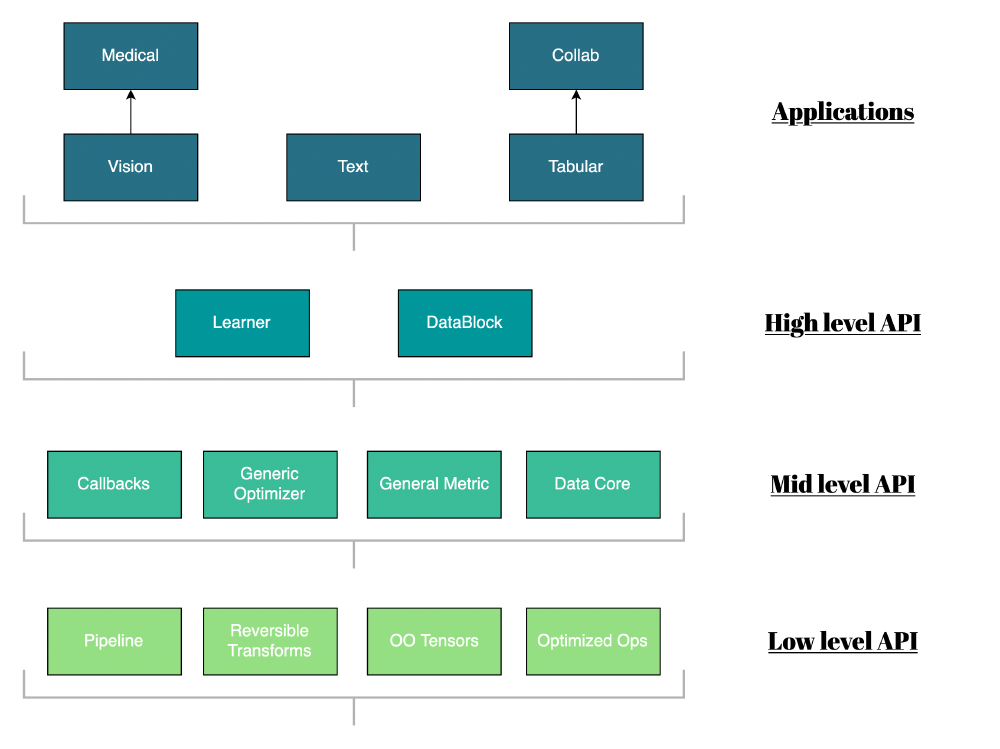
Figure: Component view
In every application dependencies between components can be found, we have depicted the most important ones in the image Component view.
One of the more interesting dependencies is the dependency between the data component and all other model components such as vision, text, and tabular. This dependency has a effect on how each model’s data is processed and is defined in the data component as such this component needs to have a well-defined API such that it can be used by a variety of models. The data component is namely responsible for keeping track of the input data, applying transformation and generating train, validation and test sets.
Connectors view
As stated in section Container view, the library makes use of Python files, Jupyter notebooks and incorporates other material found online. In the image Connectors view, we can observe the main types of connections used by this project.
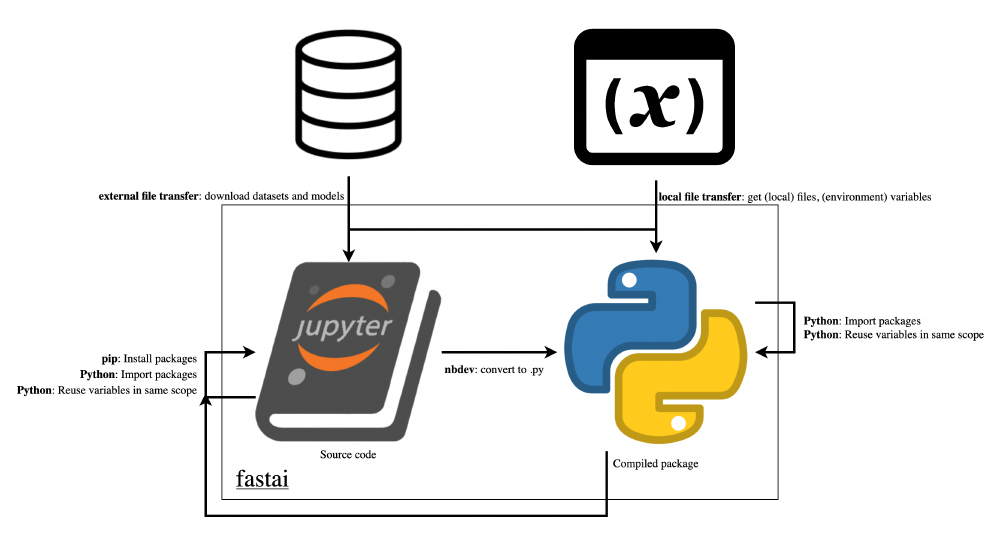
Figure: Connectors view
Firstly, we have the Nbdev connector, that converts the Jupyter notebooks to Python files with documentation.
Next, for the second connector, fastai makes use of readily available datasets and models, which are retrieved through external file transfer.
Additionally, fastai imports other packages on which fastai depends on. This is the third connector. It works by making local calls when the package is already locally installed. Otherwise, it is a remote file transfer call, whereby we make use of Pip.
Local files, variables, and environment variables can also be identified what the fourth type of connector helps with, namely local file transfer. Examples of environment variables are when the user has an NVidia GPU or AMD one, is on Windows or MacOS. This can make a difference and is therefore reflected in the code.
Development view
The modular construction of the application allows scalability and rapid prototyping for users and developers. However, it is not always easy to understand dependencies and how they relate to each other.
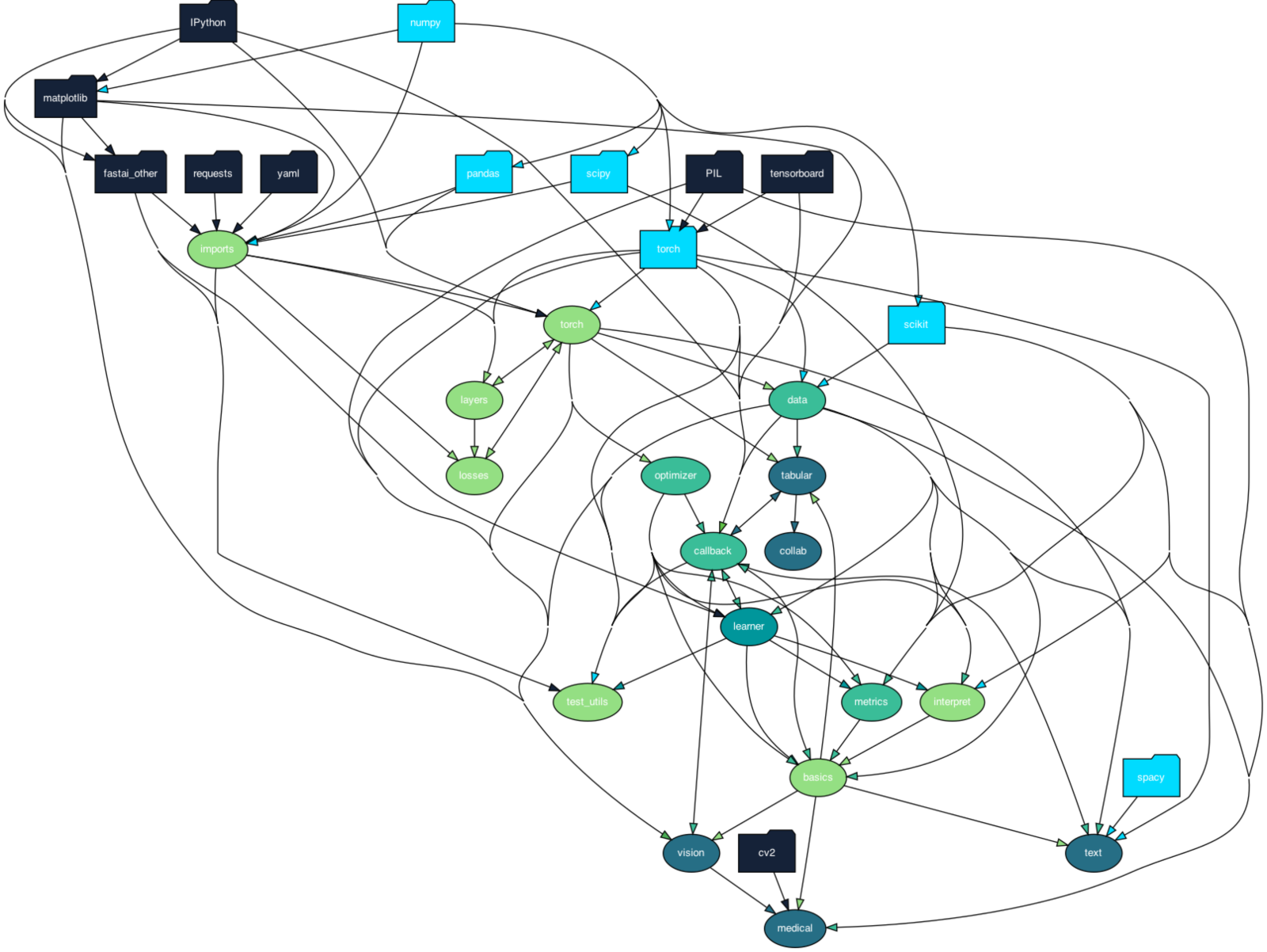
Figure: Development view
In the image Development view the following structure is applied:
- Folders are external packages which are imported
- light-blue color it means the external package is a math or machine learning package,
- dark-blue is a utility package,
- Oval shapes indicate internal packages, lighter color means lower API layer.
As mentioned in Architectural style, there are four layers, the darkest color layer are its use-cases, the second-darkest is the layer that is required to be used, whereas the last two lightest color oval shapes are more optional.
The github repository exists of four important folders of which one is used for active development. The folders are ‘dev_nbs’, ‘doc_src’, ‘fastai’ and ‘nbs’. The ‘nbs’ folder is used for development of the various features of fastai. The fastai course lives in the ‘dev_nbs’ folder and uses components from the ‘nbs’ folder. The documentation is compiled and stored in the ‘doc_src’ folder. Finally the in the ‘fastai’ the deployed python code lives.
Runtime view
In this section, we will look at the library from a process point of view. We use Philippe Kruchten’s Process View perspective4. This view looks at the dynamic aspects of the system. Thus we will show a runtime view, followed by a summary of the hardware interactions.
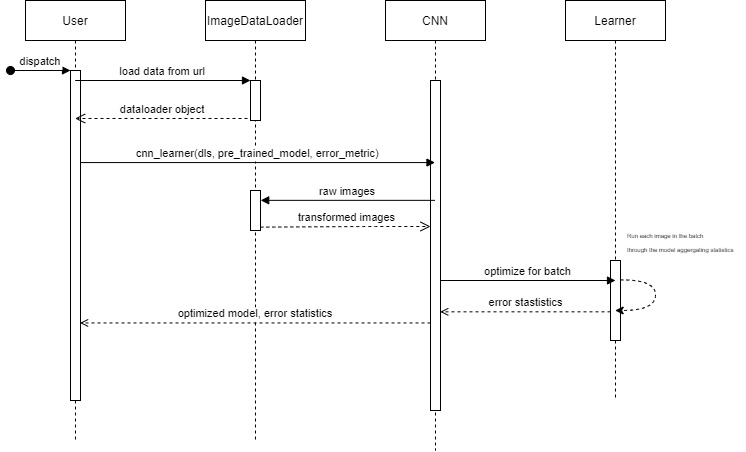
Figure: Runtime view
In the image Runtime view, we show the runtime diagram of the first example of the vision library5. The diagram allows us to see the interactions between the different components of the library, such as the data component and the model component. In the learner component, the model is optimized according to the error criteria that the model was given by the user based on the specified data.
To deploy a trained model, fastai supplies a native way to interact with the file system. Similar to other artificial intelligence libraries fastai offers a simple way to create checkpoints from where the training process of a model can be restarted. This training can be done on both the GPU and the CPU, of which the GPU is the preferred manner as it allows for faster computations.
Key quality attribute trade-offs
Flexibility and modularity are the key quality attributes of fastai. Since Python is a dynamically, strong typed language, the packages that it uses are also affected by these design decisions. As such PyTorch and other math-related packages that are integrated by fastai are easily used to interact within the different layers of the architecture without the necessity of changing complex structures 1. This setup provides a simple composition of functions that allows the users to pick and choose different objects in any sequence to develop different sorts of complex models.
But there is a trade-off, and in this case, the simplicity that fastai provides can lead to a decreased performance of the implemented machine learning model. This is because out of the box, best practices and abstractions have been incorporated. This means inherent design choices are abstracted away in the library. Beginners and even advanced users will have a difficult time uncovering all these default design choices that are implemented by the library. It would be helpful if these design choices were (exhaustively) documented. However, this has been done insufficiently. So, using this library for the average use-case should most of the time lead to sufficient performance, however, specialized use-cases will have to consider if they want all these default choices and thus extend fastai or if they want to implement it without fastai.
API design principles
As the authors mention, the design principles are accessibility and ease of use for high productivity, while also being “deeply hackable” and configurable 1. This goal inspired them to build the layered architecture mentioned above. Each of the implemented levels has different applications and varying levels of complexity to meet the needs of a variety of users (from beginner to advanced) this way they target the approachability of the API.
When referring to the flexibility of the API, fastai tries to offer a friendly high-level layer that works as an interface for different kinds of users who may have similar needs when implementing the most popular machine learning models available but who also have different approaches on the subject.
The documentation of the API can be seen as a small flaw of the library, given that not everything is extensively documented as expected (like the design implementation choices). Nevertheless, they offer many tutorials and courses that aim to help new users to begin working with their library. But, as a result, caters less to advanced users.
Takeaways
fastai’s architectural choices are dictated by the mission and its mission is to help students understand, regardless of how adversely this might affect the architecture. This is explicitly shown by the creator of this project since using Jupyter Notebooks is currently a new and therefore challenging way of creating a new library. However, it shows much potential.
fastai is an opinionated library that incorporates best practices and abstractions such to reduce boilerplate code and make it easier for the user to make a model quickly. This leads to a trade-off, the simplicity that fastai provides can lead to a decreased performance of the implemented machine learning model. Inherent design choices are abstracted away in the library. Uncovering these default design choices can make customization difficult. Thus for specialized use cases, this might not be ideal.
-
Howard, Jeremy & Sylvain Gugger. “fastai: A Layered API for Deep Learning”. Information, vol. 11, no. 2, Feb. 2020, p. 108. arXiv.org, doi:10.3390/info11020108. ↩︎
-
fast.ai docs (n.d.). Fastai Abbreviation Guide. Retrieved March 10, 2021, from https://docs.fast.ai/dev/abbr.html ↩︎
-
fast.ai (December 2, 2019). nbdev: use Jupyter Notebooks for everything. Retrieved March 10, 2021, from https://www.fast.ai/2019/12/02/nbdev/ ↩︎
-
Kruchten, Philippe. “Architectural Blueprints–The 4+ 1 View Model of Software Architecture, Software, Vol. 12, Number 6.” (1995). ↩︎
-
GitHub fastai/fastai (n.d.). Retrieved March 10, 2021, from https://github.com/fastai/fastai ↩︎