We present the vision and architectural analysis of the second version of the fastai library1. They make extensive use of Jupyter notebooks, which in their case are a combination of Markdown documentation files, the programming language Python, and command-line operations. It is being developed by a non-profit research group called fast.ai2. Throughout this post, we will refer to the research group as fast.ai and the library as fastai. We will start with an introduction to fastai, then we will introduce the fastai stakeholders, thirdly we will discuss the main capabilities of the library, and finally, we will discuss the use cases of this library and its implications.
Mission
Currently, Deep learning is a tough subject to master because it requires a mathematical background and programming experience. This means Software Engineers with no mathematical background or Data science researchers with no programming experience are hardly capable to work with common deep learning tools like TensorFlow and PyTorch. These frameworks assume that the user has that experience. So there is a gap between programmers and researchers, which is not addressed properly by common frameworks and libraries.
Thus, fastai’s mission is to make deep learning more accessible by bridging the gap between researchers and programmers. fastai is a deep learning library that provides users with high-level components that deliver “state of the art” results in common deep learning domains, such as image processing and speech recognition. Also, it offers low-level components for researchers who wish to gain finer control. The library aims to achieve both of these goals without making substantial compromises in ease of use, flexibility, or performance. This is made possible by making use of a carefully layered architecture, allowing to swap parts as needed.
Stakeholders
The use-cases are varied, just like the users. Therefore, four different stakeholders are identified: the students, the researchers, the contributors, and the founders. There is often overlap between the groups.
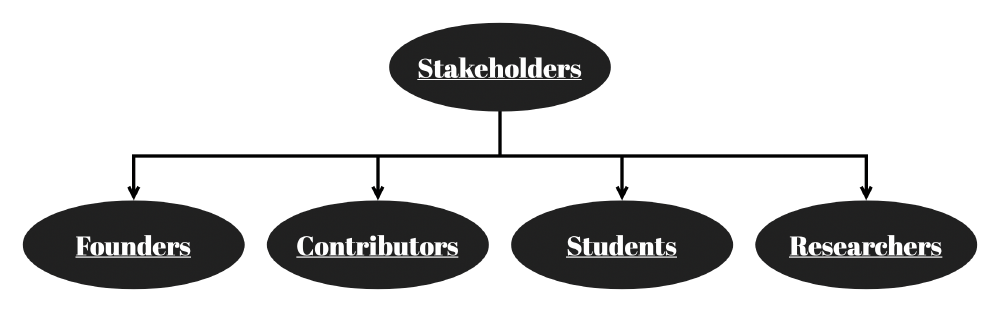
Figure: Stakeholder groups
Rachel Thomas and Jeremy Howard are the founders of the non-profit fast.ai2 and its library. They decided to create a MOOC in 2016 called “Practical Deep Learning for Coders”3 to make deep learning more accessible. fastai was the first open-source machine learning programming library designed to be accessible for any person with at least a one-year programming background. Jeremy Howard was president of Kaggle and founder of Enlitic. While Rachel Thomas has made significant contributions in the field of data ethics and is director of the USF Center for Applied Data Ethics. Jeremy Howard is the only contributor to the library that evaluates pull requests. These pull requests can cover bugs, enhancements and feature extensions. However, only changes approved by the founder are accepted, even though the community might not always agree4. Also, only the best practices empirically discovered by the founder are included. Given these two observations, means that we can conclude this library to be opinionated.
Next, contributors help in the development of the project by extending the code base, helping solve issues like bugs, adding or modifying the documentation. A contributor can fix an issue and report an issue that requires a fix. The contribution process can start at the fastai forum or at the GitHub repository directly. Every fix should adhere to the fastai coding standards and abbreviation guide5.
Moreover, students use the framework to quickly start experimenting and learning Deep learning, without necessarily having a strong mathematics background.
Lastly, researchers generally have a better understanding of deep learning and therefore are unlikely to use fastai to learn more about deep learning itself. However, they might choose fastai to quickly start prototyping or use it to set up a baseline for their research.
Use cases
The stakeholder analysis showed that there are four different groups. These groups all have other means of working with fastai. Fast.ai included their library in their freely available course material6 where a deep learning student can pick up a lot of good practices, that are common in the deep learning industry while using fastai. This is thus one such use case. Also, fastai is used in common deep learning algorithms, such as BERT for natural language processing7. Furthermore, fastai is used for prebuilt models. Fastai offers prebuilt models, such as resnet50, awd-lstm, and other transformer models, which are retrieved through PyTorch8. These prebuilt models can act as a baseline for research and are quickly deployed.
Domain and capabilities
Abstractions are made to facilitate the variety of use cases. These abstractions lead to the use of layered architecture. As such the library identifies four levels: the application use, high-level API (Application Programming Interface), mid-level API, and low-level API. Making use of such modular building blocks allows the user to “plug-and-play” any part it would need. The average user will mostly use the high-level API. Advanced users can go beyond that by parts of the lower layers and adding their custom code. Integrating fastai in a project means importing the library and calling these imported methods.
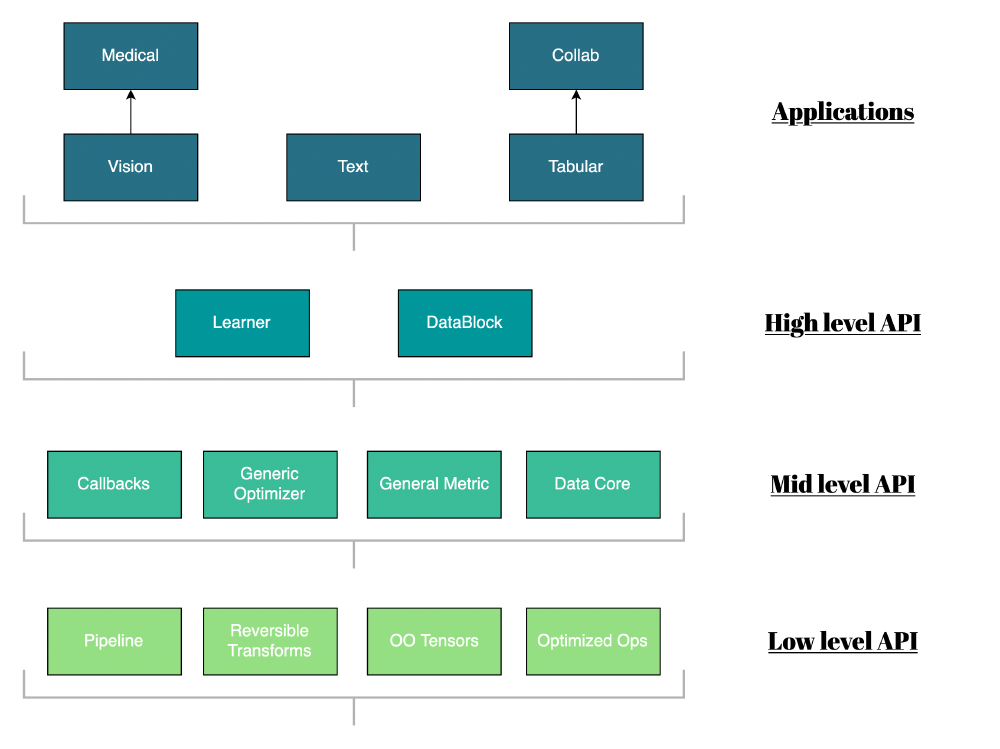
Figure: Architecture fastai
Domain applications
The high-level API interacts with three main types of use cases. The first application domain is dedicated to Vision, one can think of a PNG or JPEG image, which is then processed as a three-layered matrix. This can then be used for image classification. It is also further extended to the medical imaging domain. The second is tabular data, which is much like a one-layered matrix. It can be used when you have a shop and want to predict your sales based on your previous tabular data, like using regression. This format can also be used for Collaborative filtering 9, which code-wise is an extension of tabular, however, this extension makes use of variables with many unique categories. Collaborative filtering is the basis of a recommendation algorithm, like what Netflix employs for recommending people content on their platform. The last use case is the text domain in which you can perform Natural Language Processing (NLP) tasks like sentiment analysis. The format is a sequence, which you can interpret as a long list or a matrix with one row.
General setup
Whichever the domain, every application that makes use of fastai starts with the same basic setup. First, an appropriate DataLoader is chosen which is dependent on the application use case and thus contains the data formatted in an appropriate structure. The structure of the data also influences what kind of model can be applied to it. For example, when we choose to classify images, it means that we will use an ImageDataLoader and can use a predefined architecture model like Resnet34.
Next, a learner is chosen which is a class that groups together the model, DataLoader, and a loss function. This loss function is used to pinpoint if the training improves or not and thus is used as a way to optimize the Learner. Then a fit method that trains the model is called. Afterward, the model can be used to make predictions.
However, not always is the available data properly set up. As such one can make use of the Dataset or DataLoader class in combination with the DataBlock class. This allows users to define how the data should be processed and thus takes care of the process mostly automatically.
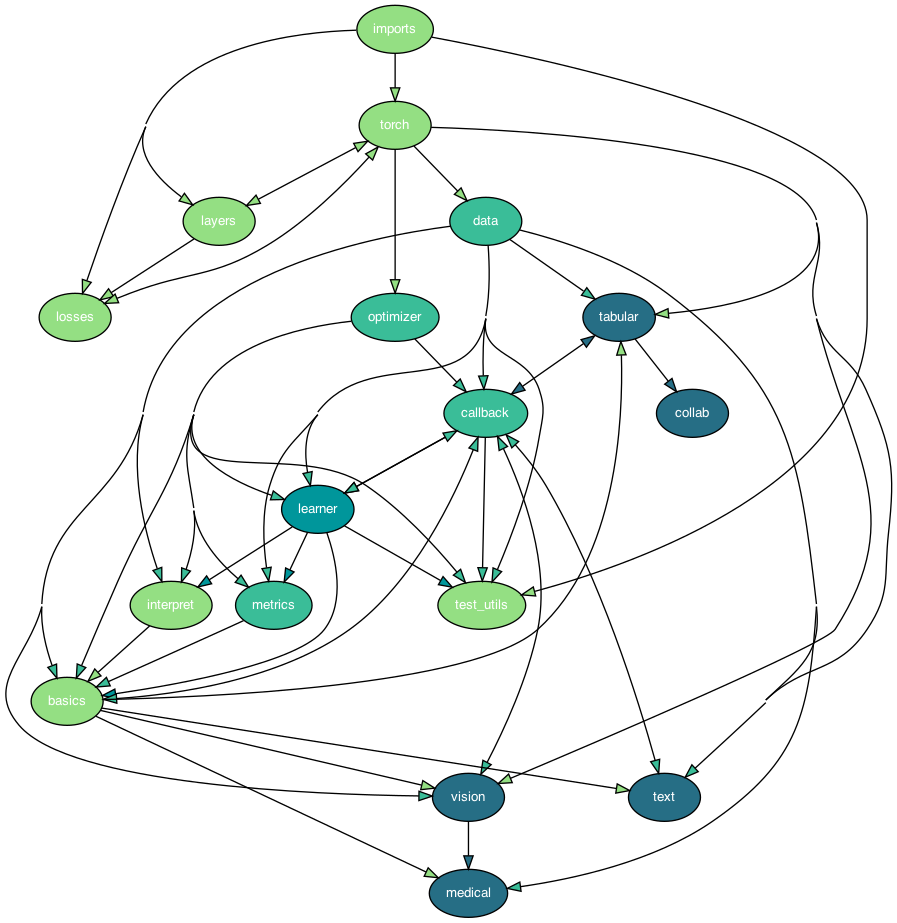
Figure: Dependency graph fastai
The actual dependency architecture does not exactly follow the Architectural view, since the Architectural view is about the concepts, while the dependency view is about the components found in the code. As shown above, the darkest color is the Applications layer, while cascadingly, the lightest color is the low-level API. Also, in the documentation low-level API is sometimes called mid-level API and as such, provides a distorted view of what is supposedly wherein the API levels. We think the intended architecture level means:
- Applications: The domain of the problem, whenever using fastai, choosing one module is required.
- High-level API: This level contains the basic modules that are required.
- Mid-level API: Use this API level if you want to optimize your results. Each module is optional but often used.
- Low-level API: Use this API level if you want to use fastai, but your specific use case is not properly covered by the framework. Thus you extend the framework by a custom addition. Using this layer is optional.
Thus the dependency graph coloring follows the intended API levels. Notice that data in the dependency graph is DataBlock and Data_core in the Architecture picture. Also, there are more packages shown in the graph, than mentioned in the Architecture picture. The graph excludes all the external packages and only mentions the packages contained in the fastai library.
Characterization of key qualities
The layered architecture reflects the main qualities of the library. Namely, flexibility, modularity, and simplicity. Keeping it simple by using only the high-level API caters to newcomers. The modularity allows the project to have a high level of customization which is useful for users with a variable level of skill. So it also caters to experienced users. Thus, having these key qualities assures that the power of even the most complex deep learning models can be implemented without losing their theoretical performance.
Competitors of fastai are libraries like PyTorch and Keras. However, these libraries assumes that the user is familiar with machine learning concepts, advanced math, and programming. While fastai only requires familiarity with programming and high school math.
Roadmap
Fastai provides easy access to deep learning. For this, it makes extensive use of PyTorch and other competitors by extending it. Since the field of Deep learning changes rapidly, fastai has had a major rewrite from version one to version two. Below we discuss the process of this rewrite and summarize the new features of version two10.
The main objective of the rewrite was to improve the further development of the library. The fastai team chose to develop the second version of the library entirely in Jupyter notebooks. Using these notebooks makes looking up the source code an interactive process, which enhances the learning experience.
In the migration, the biggest changes were made to the data block API, the callback system, the data augmentation pipeline, the NLP pipeline, and the way optimizers are created. The changes to those functionalities lead to an improved and smoother experience when working with the library, furthermore, the flexibility was greatly improved. It also decided to move from Keras to PyTorch.
Currently, on GitHub ideas for improvements are made11. The founder of the project asks for input from its users and shares their future plans12. One such improvement is to create tabular dataloaders that pull batches out of memory, which currently is not implemented for fastai.
Ethics
Ethics are important. To quote Rachel Thomas, the co-founder: “Data Ethics is essential for all working in tech”. To impact the tech world, fastai has released a free specialized course called Practical Data Ethics13. This course is designed to address misinformation, bias, the foundations of data ethics, and what tools exist to fight these issues. Considering the background of the founders and the mission of the fastai project, fastai has incorporated it into the fast.ai ecosystem. Unethical examples are shown extensively in their Jupyter notebooks and videos used for their courses and explained why they are unethical.
Their mission also reflects their ethical beliefs. Namely, to provide access to deep learning for anyone interested. This is a noble cause because previously access to this knowledge was hard to come by for the average person.
Takeaways
There exist a knowledge and expertise gap between researchers and programmers. fastai addresses it by providing an opinionated library that incorporates the best practices and standards empirically discovered by the founder. The fastai library incorporates the most common deep learning use cases. The key qualities of the library are reflected by the modularity and simplicity of its layered architecture.
-
GitHub fastai/fastai (n.d.). The fastai deep learning library. Retrieved March 19, 2021 from https://github.com/fastai/fastai ↩︎
-
fast.ai (n.d.). Making neural nets uncool again. Retrieved March 19, 2021 from https://www.fast.ai/ ↩︎
-
fast.ai course (n.d.). Practical Deep Learning for Coders. Retrieved March 19, 2021 from https://course.fast.ai/ ↩︎
-
GitHub fastai/fastai (February 17, 2018). Unclear variables #162 by imbolc. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/162 ↩︎
-
GitHub fastai/fastai (n.d.). How to contribute to fastai. Retrieved March 4, 2021 from https://github.com/fastai/fastai/blob/master/CONTRIBUTING.md ↩︎
-
fast.ai courses (n.d.). Topic: Courses. Retrieved March 4, 2021, from https://www.fast.ai/tag/courses/ ↩︎
-
Awesome Open Source (n.d.). The Top 40 Fastai Open Source Projects. Retrieved March 3, 2021 from https://awesomeopensource.com/projects/fastai ↩︎
-
Pytorch (n.d.). Torchvision Models. Retrieved March 19, 2021 from https://pytorch.org/vision/stable/models.html ↩︎
-
fast.ai docs (n.d.). Collaborative filtering. Retrieved March 19, 2021 from https://docs.fast.ai/collab.html ↩︎
-
fast.ai forums (May 19, 2019). Fastai v2 roadmap. Retrieved March 2, 2021 from https://forums.fast.ai/t/fastai-v2-roadmap/46661 ↩︎
-
GitHub fastai/fastai (Jan 19, 2021). Ideas for fastai 2.3 by jph00. Retrieved March 19, 2021 from https://github.com/fastai/fastai/issues/3175 ↩︎
-
GitHub fastai/fastai (n.d.). Roadmap fastai v2.3. Retrieved March 19, 2021 from https://github.com/fastai/fastai/projects/1 ↩︎
-
fast.ai ethics (n.d.). Practical Data Ethics. Retrieved March 19, 2021 from https://ethics.fast.ai/ ↩︎