This is the final blog posts in a series where we analyzed different aspects of IntelliJ IDEA. If you find yourself lost when reading this essay, please check our previous posts1,2,3 for more context.
Overview
In this post we’ll discuss various aspects of variability management around the IntelliJ IDEA. We’ll start with a model of the variability, then we’ll discuss the variability management. Finally, we’ll touch upon how this variability management is implemented in code.
Variability modeling
IntelliJ IDEA Community Edition (CE) is incredibly complex in terms of variability when you include the plugins that are available, both from JetBrains and third-party. However, for this analysis, we will only be looking at features that are officially part of IntelliJ IDEA CE4, because this covers the most important variability. Do note that some of the features mentioned in this section can be expanded even further with plugins.
Identify the main features
While IntelliJ IDEA CE is mainly a Java IDE, it also allows developers to program in other languages such as Groovy, Kotlin, Scala. Additionally, different SDKs can be used, should the user choose to. This can be especially useful when making applications for Linux, Mac and Android, because the most up-to-date version of Java for these platforms is not always the same as for windows.
IntelliJ IDEA CE also has many configuration options, including the JVM options and the platform properties. The JVM options allow the developer to specify the amount of memory that gets allocated for the application4, while the platform properties allow the developer to change file size thresholds for loading and intellisense as well as the maximum console buffer size5.
Version control is a crucial tool for many software projects, to accommodate for as many projects as possible, IntelliJ IDEA CE supports multiple version control tools. While Git is currently the most popular, having the option to use other types of version control is nice for developers and allows IntelliJ IDEA CE to keep up with developments in version control tools.
Different Test Runners can be used in IntelliJ IDEA CE, giving developers the option to test their application in different ways to make sure it works as intended, or run just run the types of tests that are most appropriate for their project.
Many application servers are supported by IntelliJ IDEA CE, such as Tomcat, JBoss, WebSphere, WebLogic, and Glassfish. Developers can use whichever application server best suits their project.
Build automatization can be very useful for developers, so IntelliJ IDEA CE supports many different build tools so developers can use different kinds of automatization.
Identify incompatibilities
Certain combinations of features are not possible:
- The choice of SDK is limited by the choice of language, for instance, using the Scala SDK would not be very effective when programming in Java.
- The choice of JDK in particular is limited by the most up-to-date JDK for the platform that the application is being developed for.
- While you might expect ScalaTest to not be compatible with Java, it in fact is6, while specs2 appears to be the only test runner that exclusively works for Scala7.
- Groovy only appears to be compatible with the JUnit and Spock test runners8.
- Kotlin does not appear to be compatible with the ScalaTest framework6.
Build a feature model synthesizing the information above
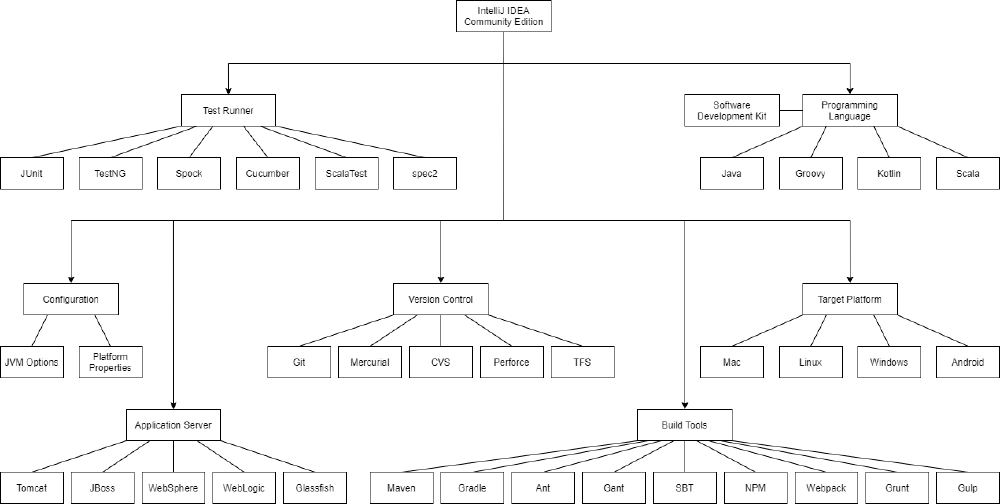
Figure: 1: The Feature Model for IntelliJ IDEA Community Edition.
Variability management
As mentioned Previously, there are a lot of options available in IntelliJ IDEA. These need to be managed, as variability management is vital in any large-scale software project. Without it, architecting for different platforms can become quite the headache.
Our first essay described the various stakeholders in the project: Contributors, End users, JetBrains and Analysts. For a more detailed analysis, please refer to our first essay1. Moreover, IntelliJ IDEA is cross-platform, supporting Windows, MacOS and linux9. Because of this, it needs to support any reasonable hardware configuration that’s able to run on these OS’s. This introduces many kinds of variability: hardware, platform, plugins and libraries.
Contributors
The Contributors (developers) deal with the bulk of the variability management. IntelliJ is developed in Java, which runs in the JVM and makes it generally OS independent. However, the libraries IntelliJ uses might still be OS-dependent. For example, every platform (Mac/Windows/Linux) has their own native launcher and restarter10. Furthermore, 10 also contains code to add functionality to the Apple Touch Bar, present on recent MacBook pro’s.
Since IntelliJ is developed in Java, managing variability is not a significant priority. This means that there is no documentation in terms of different support based on certain hardware or software. However, past PR’s do show that there is still some variability management needed. For example, in this PR, the search for the Java Home Directory was adjusted to check for WSL explicitly. Since it needed to search for a Linux directory, even though it was running on Windows.
End users, JetBrains & Analysts
These stakeholders typically use, profit from or analyze the application. For users, the developers are responsible for variability management on a OS, platform and hardware level. However, the user is responsible for providing (an up-to-date version of) the Java environment. If the user fails to do so, it will be prompted with a guide on how to do it on startup (Figure 2). Moreover, the user has a considerable amount of configurability options due to the 548311 plugins available to them. This does not even consider any configuration options in these plugins themself. Ultimately, this variability is managed by the user, since they have the freedom to add and remove any plugin as they see fit - changing the look and feel of IntelliJ IDEA completely.
Since the user has so many different options available to them, they need a way to know what they’re configuring. This is done by adding an optional ‘?’ icon after a setting in the settings menu. When the user hovers their cursor above this icon, they will get a short summary of what this setting does. However, since this function is optional, not all options in the option menu offer it, which limits the usability.
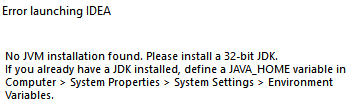
Figure: 2: Error prompt when the user does not provide a Java environment.
JetBrains, as the owner of the project, does not need to manage variability. Instead its developers do this, under the role Contributor. Moreover, Analysts don’t need to manage variability, either. Instead, they might analyze it for their essay.
Variability implementation mechanism and binding time
Previously, we discussed in what format variability takes place in IntelliJ. In this section we will look into how this variability is translate to code, how its implemented and bound at runtime.
Identify and discuss the variability implementation mechanism(s) and biding time(s) used in your application.
IntelliJ comes loaded with a significant number of default settings. These settings include (but are not limited to) theme, programming code style settings, language and programming language settings. Most of these settings are stored .xml or .properties files in the package of the respective component. A nice example is the PythonDefault.xml file. This xml file contains a list of options and values which are used by default by the python code editor for syntax highlighting. These files will be loaded at runtime.
The settings which are described above will be loaded into classes which implement the PersistentStateComponent<T> interface. This interface allows components to persist a state across IDE restarts. When starting up the IDE the loadState method will be called after the component has been created and after the xml file with the persistent state has changed. The getState method is called whenever the settings are saved, i.e. when the IDE is closed or the settings window is closed. 12 IntelliJ recommends that the state provided by the loadState method is used directly and defensive copying is not required13.

Figure:
3: Simple implementation of PersistentStateComponent interface
The implementations of the PersistentStateComponents also need to be annotated with the @State annotation. Using this annotation, the developers can specify which xml file to save the settings to14. This allows several implementations, within the same component, to share one settings file, as is recommended by IntelliJ15.
Lastly, the implementation of the PersistentStateComponent interface used by each component/plugin needs to be defined in the xml configuration of the plugin as an applicationService such that it can be loaded on demand.
Discuss the design choice made by the developer to handle variability in their application w.r.t. potential future developments and extensions
In order to further extend the variability of the IntelliJ, a developer (of a plugin) must create an implementation of the Configurable interface. This interface provides a swing form to configure settings via the Settings dialog. In order to then store these settings, the developer must provide an implementation of the PersistentStateComponent which can be modified through the swing form.
This approach has proven to be very successful for the IntelliJ platform as every plugin is developed using this method of editing and viewing their configuration. This means that there are plenty of examples on how these settings are implemented in the code base. Furthermore, being able to create a single state per component/plugin which can then be written to their own file allows them to be independent of each other. Also, given that each component has their own settings file(s) it becomes easier to find a specific setting in case of a bug or failure.
On the other hand, having more configuration files to load at startup may contribute to the slower startup and greater memory usage of IntelliJ compared to some other IDEs such as Eclipse. However, computers are starting to have an increased amount of memory, given that most computers are shipping with more and more memory, memory usage becomes less of a problem. Nonetheless, the slow startup times can be annoying for users and could therefore be regarded as a downside of this approach to variability.
Figure: 4: Ram in computers over the years[^9].
-
https://2021.desosa.nl/projects/intellij/posts/product-vision/ ↩︎
-
https://www.jetbrains.com/help/idea/tuning-the-ide.html#configure-jvm-options ↩︎
-
https://etorreborre.github.io/specs2/guide/SPECS2-4.10.0/org.specs2.guide.UserGuide.html ↩︎
-
https://github.com/JetBrains/intellij-community/tree/master/native ↩︎
-
https://plugins.jetbrains.com/docs/intellij/persisting-state-of-components.html?from=jetbrains.org#migrating-persisted-values ↩︎
-
https://upsource.jetbrains.com/idea-ce/file/idea-ce-ba0c8fc9ab9bf23a71a6a963cd84fc89b09b9fc8/platform/projectModel-api/src/com/intellij/openapi/components/PersistentStateComponent.java ↩︎
-
https://plugins.jetbrains.com/docs/intellij/settings-tutorial.html#the-appsettingscomponent-class ↩︎
-
https://upsource.jetbrains.com/idea-ce/file/idea-ce-f626e9b206c6980531d0a7d65b9311fded72166f/platform/projectModel-api/src/com/intellij/openapi/components/Storage.java?nav=614:639:focused&line=15&preview=false ↩︎