In this essay we explore Kafka’s architectural elements and relationships, and the principles of its design and evolution.
Streaming as an Architecture
Before we talk about Kafka’s architecture, we would first like to define streaming systems. Streaming systems are processing engines that are designed to process data, that is generated continuously by one or more data sources.
These generated data records could be a variety of things, changes in the stock market, geo-location of a user, sensor outputs, user activity on a website and so on. These data records are often time based events.
These data records could be translated into meaningful information, such as using a user’s view history to make recommendations. The sensor outputs could be used to detect a malfunction. These types of information is very valuable, and it’s important that these calculations happen in real-time, since you want up-to-date information. To realize this, one needs a system that can serve huge amounts of data, which can be consumed and used for performing different calculations on. This is where Kafka, an event streaming platform fits in. As a message broker it enables people to handle big loads of data in real-time.
What enables Kafka to handle high volumes of data, is the efficient usage of distributed, partitioned and replicated commit logs. Kafka has multiple components that utilize this log to receive, store and send data. Kafka can also be used for building Lambda or Kappa architectures.
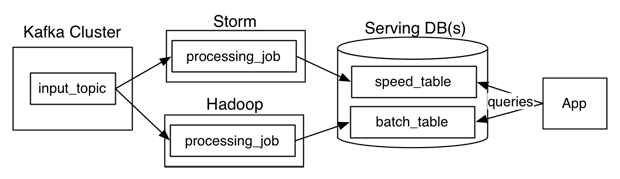
Figure: An example Lambda architecture, using a Kafka Cluster as its data source
A Lambda architecture, pictured1 above, has a data source which feeds data into a batch system and a stream processing system in parallel. The transformation logic is implemented twice, once for each of these systems. This means that two separate code bases have to be maintained which makes developing and debugging rather difficult.
This complexity was one of the reasons why Jay Kreps1, who is a co-creator of Kafka, proposed an alternative to the Lambda architecture called the Kappa architecture, pictured1 below. The Kappa architecture uses the same system for stream and batch processing.
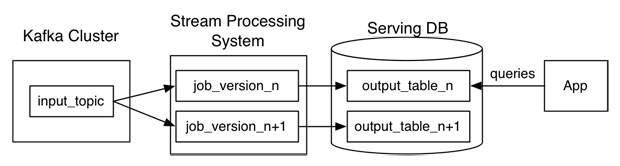
Figure: An example Kappa architecture, using a Kafka Cluster as its data source, unlike the Lambda architecture the Kappa architecture has just 1 system for streaming and batch processing
A major advantage of the single processing system in the Kappa architecture is the reprocessing of data. When the code that transforms the data changes, you can simply batch reprocess these inputs. In the Lambda architecture this would only be possible after also updating the code in the batch processing system. Another difference is the fact that the jobs in the Kappa architecture run an improved version of the same code and are executed on the same framework and have the same input. These architectures are not required to be able to run Kafka, Kafka can be run as a standalone application. The necessary pieces are explained in the following sections.
Container View
The container composition2 of Kafka is relatively simple. Kafka uses one separate container to operate: Zookeeper3. This is shown in the image4 below. Zookeeper is a load balancing application that manages the service discovery for the Kafka brokers. It decides which brokers to cluster and keeps Kafka brokers up to date with the latest topology.
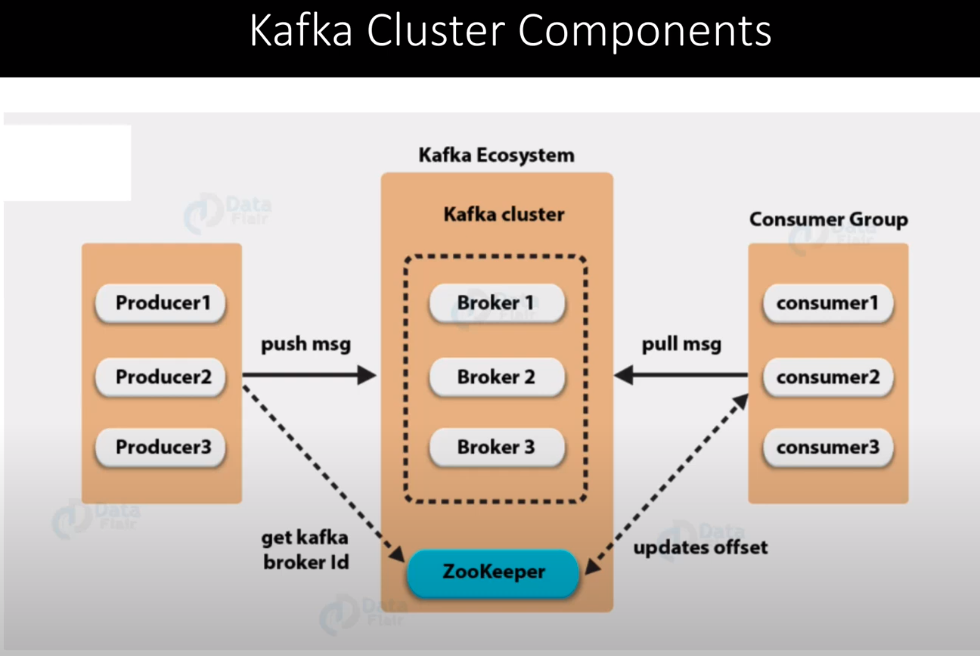
Figure: Overview of kafka context
The current goal of Apache Kafka is to not rely on any dependencies. This in turn means that they want to replace Zookeeper with an own solution that can be integrated in Kafka. Kafka will be truly independent when they replace Zookeeper. The removal of Zookeeper will greatly improve the usability of Kafka. It results in an application that only requires one executable to run.
Components View
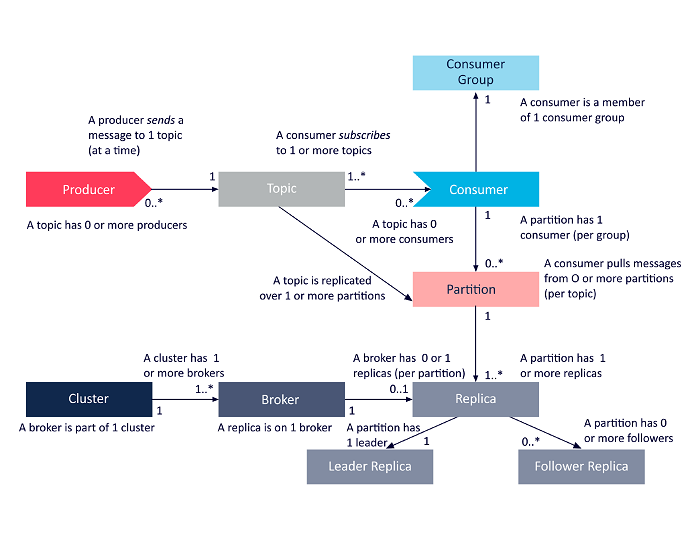
Figure: Overview of the main components that make up kafka and the relationships between them.
Kafka’s architectures is made up of topics, producers, consumers, clusters, brokers, partitions, replicas, leaders, and followers. Kafka also has other components like logging, consumers groups, offset managers, etc. but we decided to focus on the main ones.
The image5 shown above, gives us an overview of these components and their relationship with each other.
But what are these components and how do they work together? Let’s start with the broker, a broker is a server running in a Kafka cluster. Generally, multiple brokers work together inside a Kafka cluster to maintain load balancing, reliable redundancy and failover. Kafka brokers utilize Apache ZooKeeper to achieve these things, this means that Kafka has a dependency on ZooKeeper. In addition, brokers use ZooKeeper to perform leader election, which is important for data replication.
A Kafka producer is a data source that publishes messages to one or more Kafka topics. A Kafka topic is a stream of records, these topics are stored in logs which is broken up into partitions, and the partitions are replicated across brokers, where the followers replicate what the leader has. Producers publish messages to these topics, and consumers have the ability to read the messages from topics they are subscribed to. Topics are identifiable within a Kafka cluster by their unique names, and there is no limit on the number of topics that can be created.
Within the Kafka cluster, topics are divided into partitions, and the partitions are replicated across brokers. This Topic replication is essential to having resilient and highly available data. When a broker goes down, topic replicas on other brokers will remain available to ensure that data remains available. When a leader fails the system will automatically elect a new leader out of the cluster.
Connectors View
To use these components, Apache Kafka offers five key APIs: the Producer API, Consumer API, Streams API, Connect API and Admin API6.
- The Producer API allows applications to send streams of data to topics in the Kafka cluster.
- The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
- The Streams API allows transforming streams of data from input topics to output topics.
- The Connect API allows implementing connectors that continually pull from some source data system into Kafka or push from Kafka into some sink data system.
- The Admin API supports managing and inspecting topics, brokers, acls, and other Kafka objects.
The image in the components segment already sheds some light on the type of relationship between the components. But how they communicate is of course more specific; Kafka is written in Java, so most of the communication between the components is done through function calls. For example the KafkaProducer.java7 class has a send method, which sends a record to a topic. Similarly there is NewTopic.java8 class whose constructors can be used to create a new topic.
Development View
Valipour et al. have presented that complex software systems and especially service oriented systems shall utilize modular decomposability, breaking the system into smaller modules, in order to ease maintainability, understandability, and construction9. Kafka is no exception to this. Internally, Kafka is split into several modules, which can be coupled to other modules, building on top of each other, as well as being dependent on multiple external modules and tools. It relies on several external tools, such as Zookeeper for distributed synchronization, ducktape for distributed testing, JUnit for internal code testing, Yammer for collection of metrics, Vagrant as a development environment and Docker as a testing environment. Moreover it also relies on several usability tools including checkstyle for code style checking, Gradle for building Kafka, and Log4j-appender for logging executions of the program.
An overview of the complete Kafka source code and its modules, with their dependencies and additional libraries for building applications, is presented in the figure below.
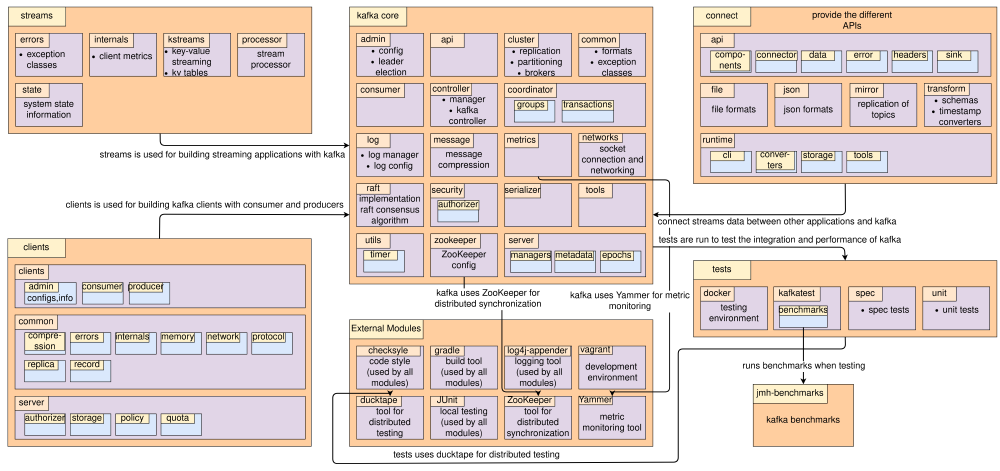
Figure: Overview of the main modules in the Kafka source code, providing many different APIs for building distributed streaming applications.
All modules and interfaces extend the core module, as it implements all basic functionality for running Kafka. The additional modules in Kafka have the following implementations, that implement the previously mentioned APIs,
streams: Streams implements the Streams API, and is the library for building applications and microservices for distributed streaming. It is built on top of the core module, and gives developers the tools for building the client side of their application in Scala and Java. Kafka Streams is used by many companies, such as The New York Times and Rabobank10.clients: The Clients module implements the Consumer, the Producer, and the Admin API. IT provides the tools for accessing data on a Kafka cluster using the said producer and consumer APIs. It implements all internal requirements for connection setup, security, and all additional management required for building applications. It is also built on top of the core module.connect: The Connect module implements the Connect API, allowing to connect any external system, such as file systems or other databases, to the Kafka cluster. It utilizes existing connectors, which are also extensible if needed, and can connect with stream based or batch based systems, to deliver simple integration from sources outside the Kafka domain to be incorporated. Again, it is also built on top of the core module.
The test module, alongside the jmh-benchmark, are meant for testing the performance and integrity of the system and assure it is
running as intended. The benchmark module includes micro- and macro- benchmarks, which are also executed when the Kafka
tests are run.
Run Time View
At a high level, the run time of a Kafka application can be viewed as the exchange of data between producers and consumers over the Kafka cluster. Producers will generate the data and consumers are individual instances, which process the data in their topic. As an example run time execution, the figure below presents the running of an application with Kafka Streams 11, which is running 5 instances, 1 producer, and 2 brokers in the Kafka cluster. Data (depicted as the differently colored boxes) comes from the producer, initially white as it does not belong to certain topic yet, and is sent to a broker in the Kafka cluster. The broker then decides on the topic for the data, using hashing, round robin, or other algorithms, and the consumer pulls the data from the broker. It pulls the data specific to the topic it is subscribed to (hence the different colors for the messages and topics in the figure). Each instance, also a consumer, then processes the data from the broker. The Kafka Streams module is used for this application for stream processing at each consumer. As previously mentioned, the Kafka Streams module is built on top of the Kafka core module and enables building of distributed streaming applications with Kafka.
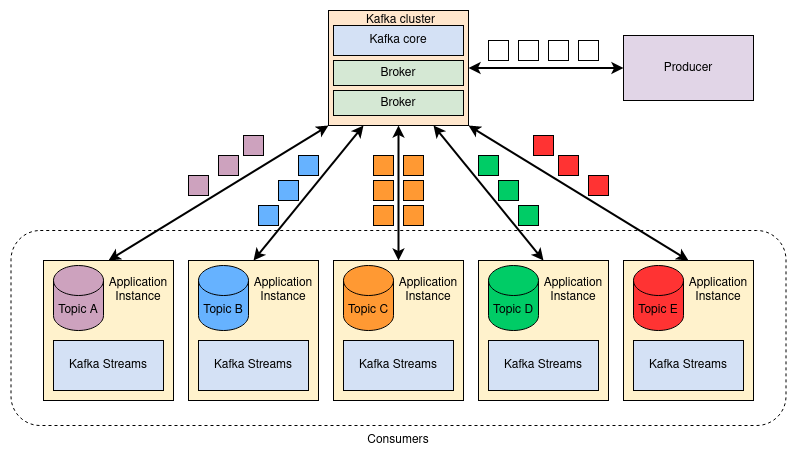
Figure: A scenario of running several instances of applications with Kafka Streams.
Realisation of Key Quality Attributes and Trade-offs
Kafka can achieve very high messaging throughput, this is done by sending a set of messages instead of a single message at a time. These messages can be compressed into a single message and can happen both when writing from producers to consumers and the other way around. This batching process can be configured to improve throughput, either increasing the minimum message size in bytes or maximum wait time (in milliseconds). This results in a trade-off between latency and throughput being configurable as the user sees fit.
Application of API Design Principles
For this section, we take a look at the implementation of Kafka, with relation to the principles explained in Software Architecture by Cesare Pautasso12. The components mentioned earlier in this post all have APIs that can be used while implemented Kafka in a system. These APIs help reduce the amount of replicated code. Kafka even uses these APIs internally. For instance, the Streams API uses both the Producer and the Consumer APIs13.
Small Interfaces Principle
Apache Kafka’s infrastructure is built from many smaller components. Again, most of these are mentioned in the components view section of this post. For each of these streams, the architecture has been focused on creating a single-responsibility endpoint for the user’s needs. The Producer API only writes into the Kafka topics, while the Consumer reads from topics. The APIs do not try to provide access to the whole project and all features. Some parts of the APIs do offer custom class injection by the user, this extends the features of a single component, while remaining small.
Uniform Access Principle (UAP)
One of the biggest features of Kafka is that it offers at least once consumption on messages. Clients can request a stream of messages which have been written by the producer to partitions in a topic. The messages will be read from the point the consumer last read them (consumer position). By storing a history of messages, based on a retention period, the user may request earlier messages, which have already been read. Most streaming services do not offer this, and are exactly-once systems instead. This exemplifies the UAP, since the user does not know, nor care, where the message came from, a real-time pipeline, or the storage. The output from Kafka will be the same either way.
Few Interfaces Principle
To reduce complexity and programming overhead, Kafka tries to loosely couple their code. This is an inherent feature of Kafka’s main operation due to the pub/sub design. Where a broker is a central point in the architecture, reducing communication between different layers.
Clear Interfaces Principle
This principle states we should only implement APIs which are necessary. Having only 5 APIs, it shows Kafka does follow this to a degree, since there are many more components. Kafka Connect API documentation states “Many users of Connect won’t need to use this API directly”14 and most may not. However, this does not mean this API is not useful. Each connector written by the community is one that can be heavily reused by users who want to connect the same system to Kafka. This saves many developers a lot of time and can be seen as DRY (don’t repeat yourself) on a larger scale. Since Kafka does not have the resources to write a lot of connectors and end-users most times do not want to write their own implementations of connectors.
References
-
Questioning the Lambda Architecture by Jay Kreps (accessed april 2021). https://www.oreilly.com/radar/questioning-the-lambda-architecture/ ↩︎
-
Simon Brown. c4model(accessed april 2021). https://c4model.com/ ↩︎
-
Zookeeper. https://zookeeper.apache.org/ ↩︎
-
Kafka Architecture and Its Fundamental Concepts (accessed april 2021). https://data-flair.training/blogs/kafka-architecture/ ↩︎
-
Developing a Deeper Understanding of Apache Kafka Architecture, https://insidebigdata.com/2018/04/12/developing-deeper-understanding-apache-kafka-architecture/ ↩︎
-
Apache Kafka. Kafka API’s https://kafka.apache.org/documentation/#api ↩︎
-
Apache Kafka JavaDocs, KafkaProducer https://kafka.apache.org/20/javadoc/org/apache/kafka/clients/producer/KafkaProducer.html ↩︎
-
Apache Kafka JavaDocs, NewTopic https://kafka.apache.org/20/javadoc/org/apache/kafka/clients/admin/NewTopic.html ↩︎
-
M. H. Valipour, B. Amirzafari, K. N. Maleki and N. Daneshpour. “A brief survey of software architecture concepts and service oriented architecture,” 2009 2nd IEEE International Conference on Computer Science and Information Technology. Beijing, China. (2009). pp. 34-38. doi: 10.1109/ICCSIT.2009.5235004. ↩︎
-
Apache Kafka. Kafka Streams. (accessed march 2021). https://kafka.apache.org/documentation/streams/ ↩︎
-
Apache Kafka. Running Streams Applications. (accessed march 2021). https://kafka.apache.org/10/documentation/streams/developer-guide/running-app.html ↩︎
-
Pautasso, C. (2020) Software Architecture. pp. 331-348 https://leanpub.com/software-architecture ↩︎
-
KafkaStreams class. Kafka Documentation (accessed march 2021). https://kafka.apache.org/27/javadoc/index.html?org/apache/kafka/streams/KafkaStreams.html ↩︎
-
Apache Kafka. Kafka docs (accessed march 2021). https://kafka.apache.org/documentation/#connectapi ↩︎