Kafka is a big open source application which is trusted by 80% of all Fortune 100 companies1. The software quality processes of Kafka play a large role in generating this trust.
Distributed Systems Test
Testing a distributed data system with only unit tests and integration tests is hard. The issues that plague the application in production cannot be simulated well on this level of testing. This is why the Kafka community created a tool called ducktape2. Ducktape is used to run distributed system tests which are maintainable, repeatable and debuggable3. This framework allows Kafka to be stress tested, performance tested, fault tested and compatibility tested automatically. It is used to run testing scenarios every night of which the results can be found at this site.
The Power of Community
However, the code will not be run in production when the review is complete and approved. Many individuals of the Kafka community will run the pre-production branch with mirrored production loads to test the branch in their own setup. This ensures that the merged requests don’t break any existing Kafka setups which could hinder compatibility. The Kafka trunk branch is always up to date with all merged requests. As Colin Mccabe states in 3:“The philosophy (…) is that more frequent upgrades mean lower risk and a smaller set of changes in which to look for any problems”.
In-dept Kafka Tests
Now that we have established (automated) testing is very important for Kafka’s continuous performance and stability, we can dive deeper into the way Kafka is tested.
Rigor of Testing
Jenkins, an automation server for building, testing and deploying code4, is used for automated building and testing. Particularly after each commit and pull request which causes both the reviewer and the developer that made the PR to look into the results of the tests. However, due to some flaky tests in the project, often times the Kafka committers are forced to re-run tests manually (section 10d5). Jenkins also displays the amount of passed and failed tests over time, see the image below (captured from the Kafka Jenkins environment). Since the number of failing and skipped tests is quite low in relation to the number of tests, it is quite safe to say Kafka tests their product rigorously.
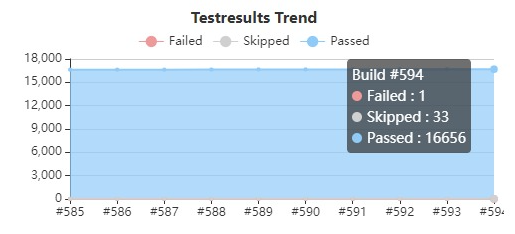
Figure: Failures and passes of Kafka tests.
Types of Tests
The following six types of tests are taken from the book: Software Architecture by Cesare Pautasso6.
Unit Tests
Kafka has 6332 unit tests (found by runnning ./gradlew unitTest) at the time
of writing. Each test tries to validate a single class method or function of the
system.
Integration Tests
Kafka has 816 integration tests (./gradlew integrationTest) at the time of
writing. Many features are tested this way, for example, creating topics,
testing connections and graceful shutdowns of parts of the system.
User Tests
User test are mostly irrelevant in Kafka in terms of GUI end-user tests. However, there are other ways that users make use of Kafka that has to be tested. Users can start setting up their own tests using Kafka Testcontainers7.
Capacity Tests
Capacity tests are important for end users, since they need to know how many brokers and servers they will need for their traffic. The performance is tested by ducktape, the aforementioned tool. Stress tests are performed to test the load it can handle, and test correctness under load. Since ducktape runs nightly (http://testing.confluent.io/), this offers a good performance test, as it is not a one-off measurement. Simultaneously, disk errors (reliability checks) and compatibility errors are checked in this setup.
Acceptance Tests
Since there is no single environment that Kafka will be running in, the ducktape runner tests the overall state of the system. Acceptance on the final implementation is done by end users, as they build Kafka into their application.
Smoke Tests
Some smoke tests exist in Kafka’s testing ecosystem. This serves to quickly validate modules of the whole project, like Kafka Streams. In this issue about smoke tests it is clear Kafka tries to test their system using smoke tests. However, there seem to be multiple implementations for smoke testing the system. This urges the developers to combine the smoke test implementation styles into a single mechanism for faster and more consistent test development.
Code Coverage
There is a tool for analysing code coverage built into the system as a task, that anyone can run. A report is made containing the results of the coverage. These results are not reviewed on a regular basis, nor are they reviewed periodically. Developers do watch the coverage while developing. When using a filter on “improve test coverage” in JIRA, 118 issues are found, most of which are dedicated to improving coverage of a module (issues: https://issues.apache.org/jira/browse/KAFKA-4657?jql=project%20%3D%20KAFKA%20AND%20text%20~%20%22improve%20test%20coverage%22).
Past and Future Hotspots in the Kafka Code
With Kafka being a large application, there are continuously changes in its code. Due to the architecture of Kafka most of these changes happen within the Kafka core module. Looking at the changes within this module over the past 1000 days, a high frequency of the changes appear in the APIs, adding functionality and improving existing functionality. An example of such an improvement is KIP-412 for extending the Admin API. As was previously mentioned, Kafka requires rigorous testing of new features or code changes. Hence, the testing module is also a major hotspot. Additionally, all of the Kafka modules are constantly changing to improve performance and usability, with a majority of all changes happening in the APIs of the different modules.
Future hotspots in the Kafka code base will likely stay the same with all modules continuously being improved, also resulting in many additions in the testing module. Many such examples can be found in the currently active improvement proposals, such as KIP-580 for improving brokers handling heavy incoming traffic by clients using exponential backoff, or KIP-584 to add versions for features. Both of said improvement proposals will be mainly causing changes in the clients and the core module, along with the test module with new tests for these improvements.
Code Quality of Kafka Hotspot Components
As previously mentioned, Kafka continuously undergoes changes, and maintaining consistent code quality can become very challenging. Solving this is partially achieved due to the previously mentioned complexities to contributing code, and since code changes have to be approved by committers, they maintain a certain level of code quality. Any contribution has to follow Kafka’s coding guidelines8. Code that is not up to the standards will not be accepted and will need to be improved before being merged into Kafka. Additionally, Kafka uses code style checking to maintain consistency across all the code and enforce the previously mentioned coding guidelines. These solve the issues of having clean code for future maintainability, however with frequent changes in the code, documentation also needs to be kept up to date. While developers try to maintain documentation as much as possible, and when adding new features documentation has to be updated alongside them, frequently pull requests are made by contributors to improve documentation. With all of said rules and guidelines, and with the help of its contributors, Kafka continuously maintains high code quality.
Quality Culture
Kafka encourages users to help build the software, for this purpose they have created guides on how to contribute to the project910. While many people contributing to the existing code base is a positive thing, you want to keep a high code quality. Consistency is a big part of code quality, thus Kafka also provided coding guidelines8. Which also mention clear and correct documentation since they want people to use Kafka. A coding standard ensures that all developers working on the project are adhering to the same specified guidelines. The newly added code will be easier to understand and proper consistency across the code base is maintained.
The guidelines provided by kafka do not contain all rules they would like to see, but they do make it easier for the commiters to review the code. For additional communication with the commiters Kafka supplies multiple channels through which communication is possible: JIRA11, Github12 or mailing list13.
Mailing List Discussions
Major code changes need to be proposed in a KIP14, KIPs are used to capture the thought process that lead to a decision or design to avoid flip-flopping needlessly. These decision or designs need to be discussed and approved, the dev mailing list15 is often used for this additional purpose.
These discussions, KIP-618, KIP-715 cover a lot of subjects, like: typos, missing motivation, questions about certain use cases, javadoc (in)consistency, questions about the approach suggested, suggestions/improvements, clarification on unclear parts, general comments and more.
The KIPs mentioned in the previous section also all have discussion threads KIP-412, KIP-580-1, KIP-580-2 and KIP-584
In the same fashion, Kafka also votes on first candidates for releases, on the vote for Apache Kafka 2.7.1.a developer mentions an issue that blocks the release so they have to solve it first.
Github Discussions
The discussion subjects mention above are not unique to the mailing list. Similar discussions regularly happen on Github and JIRA.
We will first focus on the discussions the reviewers have on Github. Besides asking questions about the implementation, suggesting improvements and making sure the code follows the guidelines, which they do comprehensively, we would like to focus on the additional things the reviewers do on Github. Like on PR #6592 the reviewer mentions that the change is a major one and needs a KIP, that he should add unit tests and update the docs. The reviewer also found an issue while playing around with the code locally. Similary PR #7898 also was a major change without a KIP, these modifications require a lot of tests to be refactored before it could be accepted. In PR #9549 the user implements a change specified in a earlier KIP that was forgotten. The reviewer had good additional suggestions about efficiency and caching. Another interesting one is PR #6329, this PR solves a bug that is a blocker for some windows users, which they really need merged, but the reviewer notices an unsafe operation and request a change by proposes an abstraction in the code. In PR #4871 a reviewer observes exceptions while running the code and provides additional info to contributor through the mail, which he can use to further improve the code.
In PR #4994 a reviewer mentions they use @InterfaceStability.Evolving annotation on brand new interfaces and change them into @InterfaceStability.Stable in the following release. They do this so they have the flexibility to make changes to the interface if required for older releases since incompatible changes to stable interfaces can be made only in major releases. In PR #5527 changes made by another contributor, who happens to be a reviewer, in another PR breaks something in PR #5527. the reviewer offers help to figure out how to best remedy the consequences of his changes.
JIRA Discussions
Because major changes need KIPs and these are mainly discussed in mailing list the JIRA issues are mostly used for bug and minor fixes. For the bugs the discussions are mainly about reproducibility like issue KAFKA-12323, what may have caused the bug like issues KAFKA-10049, KAFKA-7870, KAFKA-7114, KAFKA-10134 and how damaging a bug is like the blocker issue KAFKA-12508. For normal issues the discussions could be about potential workarounds while acknowledging that the ticket is valid, for example issue KAFKA-6840. In issue KAFKA-12478 they suggest a modification to see if the behaviour is working as intended and recommending follow up steps if that’s not the case.
Conclusion
Based on what we’ve seen Kafka has a great quality culture, where they are actively trying to help contributors through multiple channels. The strict rules before a PR gets approved ensures that the quality in the codebase stays high. While reviewing they are also making sure that guides, tests, javadocs and other supplementary material that support the code are up to date.
Technical Debt
Every shortcut you take during development will have to be resolved one time or another. A well established application like Kafka knows this as no other. An application accumulates technical debt when an implementation uses a limited solution that will have to be reworked eventually. The aim for every application in general is to minimize technical debt in order to continue the development of new features. However, technical debt is not always easy to prevent and often discovered afterwards.
Open Issues
Kafka has its own fair share of technical debt. The first kind of technical debt is bugs. Every bug encounter requires updating existing code to fix the bug. The Kafka repository currently contains 1455 open issues that are labeled as bug. The total amount of open issues at the time of writing is 3170. That means that almost half of the issues of Kafka is about bugs. Another issue label that can be seen as reworking old code is the improvement label. There are currently 1172 of these issues opened at the time of writing. Issues with the improvement or bug label can be considered as technical debt issues. This means that 2627 out of 3170 issues are addressing technical debt.
Zookeeper
Another point of technical debt can be found in design decisions. One of Kafka’s goals is independence of other modules. The last module that Kafka uses at the time of writing is Zookeeper. Zookeeper is a load balancing module that oversees the connections between clusters, clients and producers. The Kafka community is currently working on an in-house replacement that will eventually cement Kafka as an independent application16. There was a consensus early on in development that the shortcut of using external tools was necessary to create a functioning product on time. This resulted in the long development roadmap that is necessary to remove these external tools from the application.
References
-
McCabe, C. “How Apache Kafka is Tested” (2017) https://www.confluent.io/blog/apache-kafka-tested/ ↩︎
-
Jenkins Website. https://www.jenkins.io/ ↩︎
-
ASF, Juma, I. “Contributing Code Changes” (2020), https://cwiki.apache.org/confluence/display/KAFKA/Contributing+Code+Changes ↩︎
-
Pautasso, C. (2020) Software Architecture. pp. 331-348 https://leanpub.com/software-architecture ↩︎
-
Testcontainers Website. https://www.testcontainers.org/modules/kafka/ ↩︎
-
Kafka. Coding Guidelines (accessed march 2021). https://kafka.apache.org/coding-guide ↩︎
-
Apache Kafka, Contributing simple https://kafka.apache.org/contributing.html ↩︎
-
Apache Kafka, Contributing in depth https://cwiki.apache.org/confluence/display/KAFKA/Contributing+Code+Changes ↩︎
-
Apache Kafka JIRA Open Issues https://issues.apache.org/jira/projects/KAFKA/issues/KAFKA-12514?filter=allopenissues ↩︎
-
Github Apache Kafka https://github.com/apache/kafka ↩︎
-
Apache, Kafka, Contact methods https://kafka.apache.org/contact ↩︎
-
Apache, Kafka Improvement Proposals, https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Improvement+Proposals ↩︎
-
Apache, Kafka Archive Dev Mailing List. https://lists.apache.org/list.html?dev@kafka.apache.org ↩︎
-
C. McCabe (2020) KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum. https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum ↩︎