Apache Kafka is a event streaming service that works as a distributed log. Before diving into how Kafka is distributed, we will look at a high level overview of Kafka’s workflow and its architecture.
Distributed Components of Kafka
Kafka offers a way for systems to read and write data in real-time. It has a few important components you should be aware of. To transfer events as information, in real-time and without forcing a consumer to read all data, topics are used. These are containers for data, which consumers may subscribe to, and producers may write to. These topics are stored on brokers, where topic data is split up across partitions1. Multiple brokers exist, to replicate data, and to process data in parallel. A cluster of brokers can be queried with API calls, both by producers and consumers. For them, the implementation (replication count) is hidden.
The following image2 shows the Kafka Streams components.
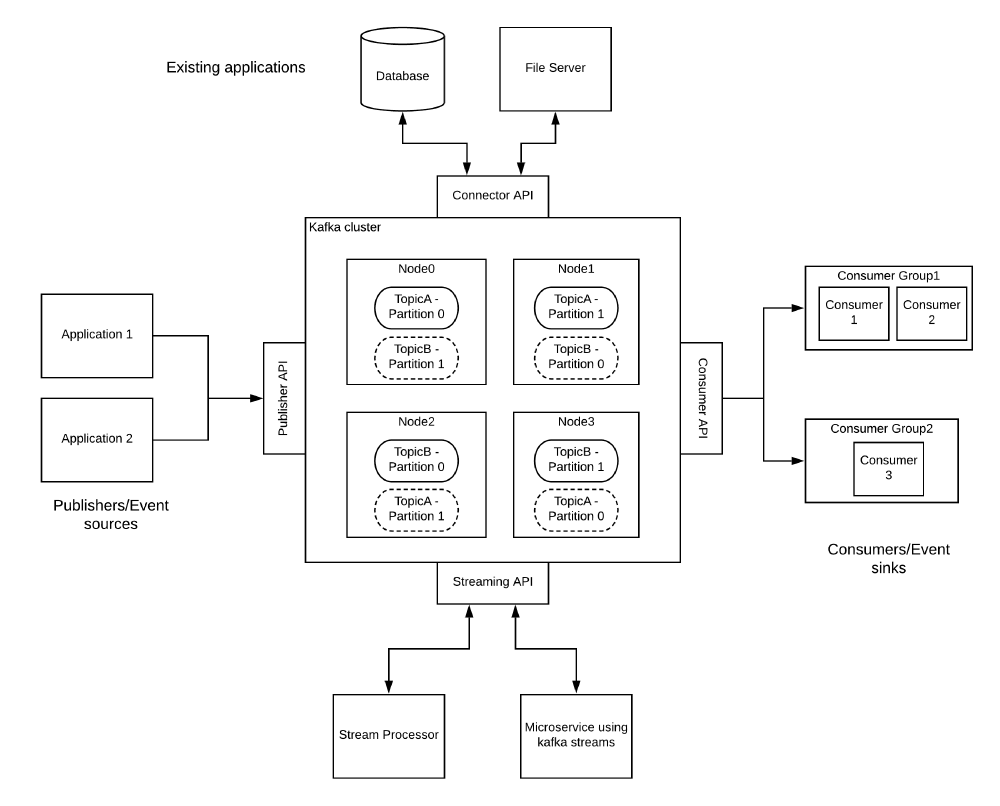
Figure: The distributed Kafka components
It is also possible to aggregate clusters, however, this always concerns mirroring of clusters3. Multiple topics cannot be spanned across two separate clusters, two clusters are always mirrored. Combining, or rather mirroring clusters has two main use cases. One is geographical, mirroring in different locations offers considerable speed up, because latency is eliminated. The second is to reduce load on a cluster.
Data Exchange Between Brokers
Managing multiple brokers during runtime is non-trivial. Kafka solves this issue by using ZooKeeper as an overview application. ZooKeeper will maintain contact with all brokers and handle the internal addressing. Brokers will ask ZooKeeper for the ip of the other brokers in order for them to directly talk to each other. ZooKeeper will also notify other brokers when a broker loses connection or is no longer available due to other reasons.
Before a consumer can read from a topic, a producer has to write to it. It can do so by starting to connect to a bootstrap broker4 and identify what topic it wants to write to. Some metadata is returned with the partitioning info. Based on that info, the producer can write to a chosen partition. That partition exists on a leader broker, where the producer connects to and sends the message he wanted to write. All other brokers (followers) send requests to the leader to see if there are new messages they need to copy. When the followers have done this, the consumer can read the messages from any broker.
Kafka Fault Tolerance
Partition Replication
The way Kafka handles fault tolerance is by replicating partition data among different brokers, in this case also called replicas5 6. Kafka brokers store data in partitions, and each of the partitions is replicated on several other partitions, depending on the configuration for how many replicas there should be, such that in case one fails, another can take over. With all the different replicas, there is one that is assigned the leader, which is responsible for ordering writes from producers, and propagating the writes to the replicas such that they can then replicate the leader’s partition. In order for maintaining information on leaders, replicas, electing leaders, and knowing when a leader or replica fails, each Kafka cluster has one controller Broker. This broker is like any other, in that it will store data from producers, and supply to consumers, however it has some additional responsibility. It additionally keeps track of all brokers that are leaving/joining the cluster, using ZooKeeper (Note that ZooKeeper will be replaced by a Kafka implementation7, however it is still being used as default at the time so we will explain its setup). ZooKeeper is an additional cluster for maintaining metadata for the Kafka cluster, and it ensures which brokers are live, by requiring constant pulse messages.
When a leader fails, ZooKeeper will know, inform the controller Broker, which then selects one of the
in-sync replicas (a replica that is up to date with the leader of that partition), and makes it the new leader.
A common fault in clusters are transient faults (the faulty server returns after some time), in which case when the failed leader
returns, it will inform ZooKeeper and go back to becoming the leader by catching up on missed messages from its most recent
high watermark (HW), which is just the offset of the latest message in the partition it knows of. In the case that the
controller Broker fails, ZooKeeper will inform all brokers about the failure and all will apply to become the new controller Broker.
The first one to apply will then actually become the controller. ZooKeeper relies on the ZAB (ZooKeeper Atomic Broadcast) protocol for
consensus, which requires ceil(N/2) number of non-faulty servers. Once ZooKeeper is replaced with Kafka’s
own Raft8 based implementation, it will be able to handle f faulty servers such that n=2f+1, for n total number of servers.
Modes of Operation
What happens when a broker fails before it can acknowledge a message? Is the data duplicated in the partition, or not in the partition at all? For solving this, Kafka has different semantics on the state of a partition when a broker fails. There are three different semantic modes, at-least-once where data is at least once in the partition, at-most-once, where data is no more than one time in the partition, and exactly-once where there is exactly a single instance of the data in the partition 9. Exactly-once is the most optimal, as whenever a broker fails, you know the data will be there without having a duplicate when the next broker receives a re-transmission (since there was no acknowledgment from the previous broker that failed). Failing is not limited to just the broker, clients or consumers can also fail in the same way. Kafka achieves exactly-once semantics with idempotence and atomicity. Idempotence is where operations can be performed multiple times but the result will always be the same. Resending of messages if a broker fails will then result in the same state, and maintaining an additional sequence number for each batch allows for identifying if the sent data is a duplicate (it is already in the log). Atomicity ensures that writes to multiple partitions either all succeed or not at all through the use of transactions. With these, Kafka can ensure that data is not duplicated inside partitions, and can identify when it is written exactly once, all without much additional overhead.
Trade-offs: CAP Theorem
To analyze the trade-offs of the distributed design of Kafka we would like to look at the CAP theorem10. The CAP theorem implies that a system has to pick two of three desired characteristics: consistency, availability, and partition tolerance. In a 2013 article11 LinkedIn engineers mention “Our goal was to support replication in a Kafka cluster within a single datacenter, where network partitioning is rare, so our design focuses on maintaining highly available and strongly consistent replicas” So, they mention that they are focusing on maintaining high availability and strong consistency. But what do these terms mean and how do they achieve this?
Consistency implies that every read receives the most recent write or an error.
With Kafka this data can come from N partitions. If data is written on an
arbitrary partition A and later data is read from partition B before the data is
replicated from A to B, it is inconsistent.
Availability implies that every request receives a (non-error) response, without the guarantee that it contains the most recent write.
Consistency - Availability
Knowing these terms, we can look at how they do this. An option is to wait for all partitions to be done copying before returning, but this causes delays. But what if you choose to return data if 5 out of 10 partitions have finished replicating, so in-sync replicas should be 5. This means that receiving data is possible from 10 partitions, where 5 of them won’t return the most recent one, keeping an availability of 5. So, how do we get strong consistency as well? We just read from 6 partitions, meaning at least 1 of them has the most recent data. These settings are all tunable on Kafka, Cloudera has their own docs12 on Kafka about getting strong consistency and high availability. For instance, modifying the number to 2 out of 10 increases the availability but decreases the consistency.
Throughput - Latency
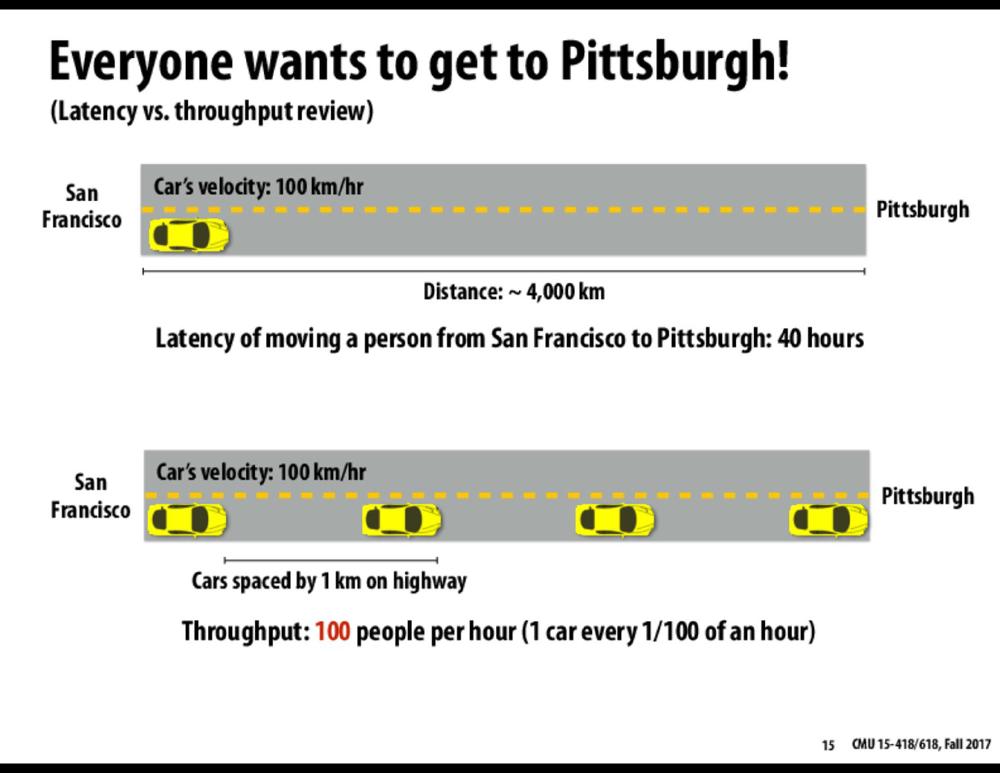
Figure: A overview of latency vs throughput. A single car arrives in 40 hours while grouping the cars makes it so that after a certain period 1 car arrives every 1/100 hour. This is not request driven like Kafka, but does show a nice example of latency vs throughput
One of their core capabilities is high throughput. Throughput is a measurement for how many events arrive within a specific amount of time. Kafka is balanced around high throughput and low latency. Directly processing small messages as they occur leads to small network and disk operations which in turn severely limit throughput. This trade-off between latency and throughput is well known13. The image14 shown above shows the general idea of grouping items together. Kafka uses a segmented, append-only log, largely limiting itself to sequential I/O for both reads and writes, which is fast across a wide variety of storage media. Sequential I/O is fast on most media types, it will keep up with the network traffic. Quite often the bottleneck with Kafka is the network. So the fundamental technique Kafka uses is to incur a small amount of latency to group small messages together and improve throughput. This grouping is tunable at the application level. Doing these batches increases the throughput at the cost of latency
Network Partitioning
While Kafka does not focus on network partitioning, they do consider it. Network partitions in Kafka are breaks in communications between servers. These are rare because Kafka was architected to support replication in a Kafka cluster within a single datacenter, which provides consistency. But network partitions can still happen, and Kafka is well prepared for them. To showcase this we describe two scenarios15 of network partitioning and how Kafka handles them.
Let’s take a scenario where one or more follower partitions lose connection to the leader, these partitions will simply be removed from the in-sync replicas list, and stop receiving messages. Once the connection gets resolved and the partitions are caught up with the leader, they will once again be added to the in-sync replicas list.
Another scenario Kafka can handle is when a leader loses connection to Zookeeper7, its follower and the controller. In this scenario the isolated broker will keep thinking its a leader and keep accepting messages for a few seconds. Since Zookeeper has lost connection to this isolated broker it will mark it as dead and elect a new leader amongst the followers. Once the network partition is resolved, and the original leader get notified it is not longer the leader via Zookeeper. It will truncate its log to the high watermark of the new leader and continue operating as a follower.
References
-
L. Johansson. Part 1: Apache Kafka for beginners - What is Apache Kafka? (2020) https://www.cloudkarafka.com/blog/part1-kafka-for-beginners-what-is-apache-kafka.html ↩︎
-
Fernando, C. Understanding Apache Kafka — The messaging technology for modern applications (2019) https://blog.usejournal.com/understanding-apache-kafka-the-messaging-technology-for-modern-applications-4fbc18f220d3 ↩︎
-
Cloudera Managing Topics across Multiple Kafka Clusters (accessed March 2021) https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/kafka_multiple_clusters.html ↩︎
-
Jacek Laskowski broker property (2020) https://jaceklaskowski.gitbooks.io/apache-kafka/content/kafka-properties-bootstrap-servers.html ↩︎
-
Ashwitha B G. (2020). Fault Tolerance In Apache Kafka. https://medium.com/@anchan.ashwithabg95/fault-tolerance-in-apache-kafka-d1f0444260cf ↩︎
-
Stanislav Kozlovski. (2018). Keeping chaos at bay in the distributed world, one cluster at a time. https://hackernoon.com/apache-kafkas-distributed-system-firefighter-the-controller-broker-1afca1eae302 ↩︎
-
Colin McCabe. (2020). Apache Kafka Needs No Keeper: Removing the Apache ZooKeeper Dependency. https://www.confluent.io/blog/removing-zookeeper-dependency-in-kafka/ ↩︎
-
Diego Ongaro and John Ousterhout. (2014). In search of an understandable consensus algorithm. In Proceedings of the 2014 USENIX conference on USENIX Annual Technical Conference (USENIX ATC'14). USENIX Association, USA, 305–320. ↩︎
-
Neha Narkhede. (2017). Exactly-Once Semantics Are Possible: Here’s How Kafka Does It. https://www.confluent.io/blog/enabling-exactly-once-kafka-streams/ ↩︎
-
What is the CAP Theorem ? IBM, https://www.ibm.com/cloud/learn/cap-theorem ↩︎
-
Intra-cluster Replication in Apache Kafka, https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka ↩︎
-
Configuring High Availability and Consistency for Apache Kafka https://docs.cloudera.com/documentation/kafka/latest/topics/kafka_ha.html ↩︎
-
Latency lags bandwith, David A. Patterson https://dl.acm.org/doi/10.1145/1022594.1022596 ↩︎
-
Latency vs Throughput, Bosco Noronha, July 23 2018 https://medium.com/@nbosco/latency-vs-throughput-d7a4459b5cdb ↩︎
-
Vanlightly, J. (2019, April 1). RabbitMQ vs Kafka Part 6 - Fault Tolerance and High Availability with Kafka. Jack Vanlightly. https://jack-vanlightly.com/blog/2018/9/2/rabbitmq-vs-kafka-part-6-fault-tolerance-and-high-availability-with-kafka ↩︎