In the previous blog post, we discussed Kubernetes' key attributes and where Kubernetes could head in the future. In this blog post, we go from Kubernetes' vision to its architecture. To find out how its properties are realised, we aim to answer questions such as: which architectural style is applied? What do the container, component, connector, and development views look like? Why has Kubernetes designed its architecture in such a way? Please read along to find out!
Architecture patterns
The architecture of Kubernetes spans four different major topics. The nodes, the Control Plane-Node communication, Controllers, and the Cloud Controller Manager1.
Firstly, Kubernetes will create nodes for its cluster, which may be either virtual or physical machines, and divide the workload from the user into pods that run on these nodes. Each of these nodes is controlled by the Control Plane, which orchestrates the creation, deployment and lifecycle of these nodes.
Kubernetes handles the communication path between the Control Plane and the Kubernetes clusters in two ways.
-
Node to Control Plane - In the communication from a Node to the Control Plane, Kubernetes follows a ‘hub-and-spoke’ API pattern2. In this analogy, this means that the ‘spokes’ are the nodes and the ‘hub’ is the API server where all node communication comes together. All API usage from the nodes terminates at the API server.
-
Control Plane to Node - The Control Plane can communicate with the nodes in two different ways, namely communication from the API server to the kubelet or from the API server directly to the nodes, pods, and services.
Once the cluster is up and running and communication is taken care of, the cluster must run as smoothly as possible with the resources it has available. This is where controllers come in. Kubernetes comes with a set of built-in controllers that watch the state of your cluster and make changes where needed3. These controllers track Kubernetes resource types and are responsible for making the current state of that specific resource come closer to the desired state. The controller will often communicate with the API server to start actions to make this happen.
If the cluster is running in the cloud, then this process is assisted by the Cloud Controller Manager. The Cloud Controller Manager allows any user to run Kubernetes on public, private, and hybrid cloud environments. The Cloud Controller Manager is a Kubernetes Control Plane component that embeds cloud-specific control logic and lets you link your cluster into the cloud provider’s API without any hassle.
Components view
In this section, we discuss the components of Kubernetes and try to answer the question “How are Kubernetes' components connected and what is their role?”. The following figure will give an overview of the components4:
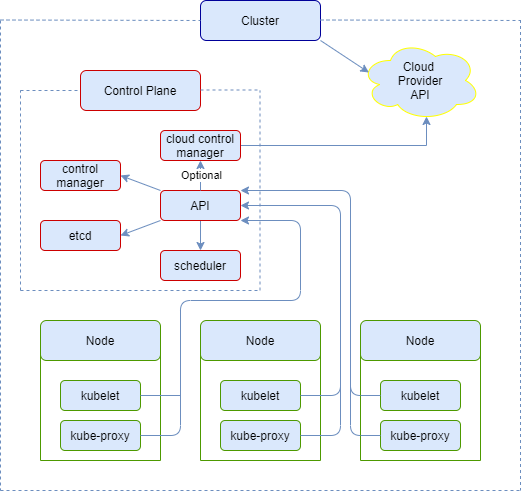
Figure: Components view (based on Kubernetes Components diagram)
As you can see from the diagram, the nodes and the control plane play an import role inside the cluster. The following three components exist inside the cluster created when Kubernetes is deployed:
Node
The node runs containerised applications. There can be multiple nodes in a cluster, but there needs to be at least one per cluster. Inside a node there are a couple of components that make sure the pods run correctly, namely:
-
Kubelet - This component watches over the running containers in a pod. Kubelets also act on every node.
-
Container runtime - The container runtime is software that runs the containers. Container runtime are elements that take applications from the host server and deploy them. It can be run from different locations and have the same behaviour5.
-
Kube-proxy - Kube-proxy is a network proxy that makes sure the rules of the networks not violated on each node.
Pod
Pods are contained in the nodes. They are the smallest deployable unit of Kubernetes. The pod can be seen as a group of containers that have common storage and network resources6. Pods contain a specification of how their containers work. Its containers are run with the same schedule and in the same context, which includes Linux namespaces and cgroups.
Control Plane
The Control Plane manages the nodes and the pods. Plus, it organises the cluster. Its components are as follow:
-
kube-apiserver - The kube-apiserver is the implementation of the Kubernetes API server. Additionally, it can run multiple kube-apiservers at the same time and still manage them.
-
etcd - etcd is the secondary storage of the cluster data.
-
kube-scheduler - The kube-scheduler identifies new pods and assigns them to a node. Furthermore, it optimises the assignment by considering different factors.
-
kube-controller-manager - The kube-controller-manager runs controller processes (e.g., running processes for nodes, job, and token controllers).
-
cloud-controller-manager - The cloud-controller-manager establishes the connection to the cloud API and correctly links the required components to the cloud.
Addons
Apart from the three components mentioned before, there are different types of addons that implement cluster features, such as:
-
Domain Name System (DNS) - Every Kubernetes cluster has a cluster DNS.
-
Dashboard - The dashboard is a webpage for managing the cluster and its running applications.
-
Container Resource Monitoring - Container Resource Monitoring measures the time usage of containers and stores them for viewing.
-
Cluster-Level Logging - Cluster-Level Logging saves container logs for viewing.
Connectors view
Having introduced the components in a cluster, we are going to discuss how the components are connected in the Connectors View.
The Control Plane manages the worker nodes and the Pods in the cluster7. The Control Plane runs over multiple computers and has multiple components that manage the state of the entire application. The control plane exposes the Kubernetes API server which is the front end for the cluster’s shared state8. This API server validates and configures data for API objects within the cluster, such as pods and services.
The Kubernetes network proxy runs on each node and is a component that allows interaction between pods inside a worker and both other parts of your cluster and the outside world. It can do TCP, UDP, and SCTP stream forwarding across a set of backends that are run in pods9.
Controller processes are control loops that regulate the state of a system. The kube-controller-manager runs multiple controller processes that regulate the internal state of the cluster7. The cloud-controller-manager runs controller processes that are specific to the cloud10 7. There are multiple types of controllers, some of which are cloud-specific, such as the node controller, the route controller, and the service controller. Other controllers managed by the kube-controller manager include job controller, endpoint controller, and service account and token controller.
Containers view
Kubernetes is a container orchestration platform. In other words, when deploying an application, Kubernetes will spin up groups of hosts running Linux containers and cluster them together and help to easily and efficiently manage those clusters11. Kubernetes can also be run locally, on any device, with Minikube12. It creates a Virtual Machine (VM) that has one cluster with one node in it, which can be used by beginners to understand how Kubernetes works. Similarly to Minikube, Kubernetes can also be set up using VMs, such as Docker, VMware, or Windows' Hyper-V. If you want to run your clusters in the cloud, you can use providers, such as Google, Amazon, and Microsoft13. This means they do this for you and you can access it via their API.
Development view
The source code of Kubernetes is mostly written in the Go language. Go has its standard project layout14. According to the layout, cmd is the module where the main application of the project is. In this module we can see folders like ‘kubectl’, ‘kubelet’, and ‘kube-controller-manager’. The pkg module is a section where you place library code for external applications. In the package module of Kubernetes, we see components, such as ‘kubectl’, ‘kubelet’, and ‘kubeapiserver’. The vendor module is used for the application’s dependencies. We see a lot of Go libraries (e.g., go.opencensus.io and go.uber.org). The api module contains OpenAPI specs, JSON schema files, and protocol definition files. The build module contains files about packaging and Continuous Integration (CI). The test module contains, you’ve guessed it, tests. It contains extra external test applications and data. The docs directory consists of user and design documents.
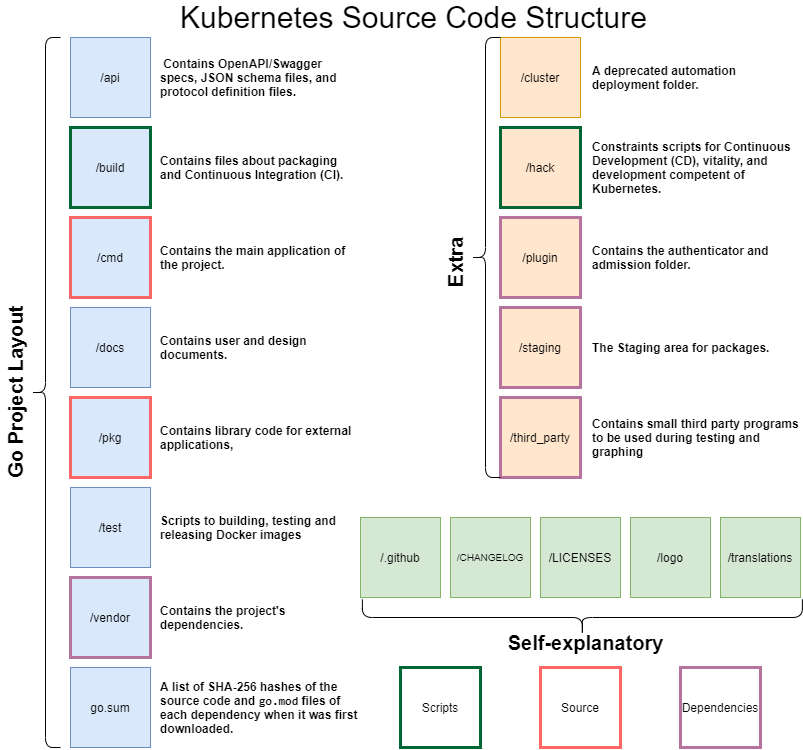
Figure: Development view of source code on GitHub
The following directories are self-explanatory: /.github, /CHANGELOG, /LICENSES, /logo, and /translations. The rest of the directories are different from the standard go language and explained in the following table:
| module | what is it for |
|---|---|
| cluster | This is a deprecated automation deployment folder (moved to https://github.com/kubernetes/kube-deploy) |
| hack | Constraints scripts for Continuous Development (CD), vitality, and development competent of Kubernetes. |
| plugin | Contains the authenticator and admission folder. |
| staging | Staging area for packages. |
| third_party | Small third party programs like qemu-user-static or protobuf. |
Run time view
The next section describes how the different components interact at run time15.
Everything starts with deploying an application on the Kubernetes cluster by creating a Deployment configuration. The deployment instructions are registered by the Control Plane, which finds available nodes for running the application containers (which are found in a pod). When such nodes are identified, the Control Plane schedules the containers on them. The Kubernetes API facilitates the communication between the control plane and the nodes. Users can also manage the cluster through the API16 17.
Whenever there is an error in one of the nodes or a node is deleted, the Deployment Controller (which is active during run time) replaces it with a newly available node, where it recreates the required pods. In Kubernetes, this replacement can be done without downtime by using Kubernetes' Services. Every pod has a unique IP address, which is shared outside a container through Services and hence can receive external instructions and pass its attributions during run time. Services define the relationships between related pods and can have different types of exposure18.
An important feature at run time is scalability. The user can create multiple replicas of their application in Deployment, which are then organised over different pods. Additionally, it is possible to update an application by using rolling updates. Downtime is avoided during pod updating since the pods are updated one by one, so that continuity can be supported by the other pods. Possible rolling updates are: changing the environment of an application, moving back to a previous version of the application, and CI19.
API design principles applied
The REST API is the main fundamental connector that is handled by the API Server. All components in the Kubernetes platform are treated as an API object. The API Server uses etcd as its persistent storage component, which stores states such as jobs being scheduled, pod states and namespace information. The API uses subsequent authentication, authorization and admission control20. These steps are taken by human users which access the service and pods that want to access other resources within the cluster. When a user, human or pod, is authenticated, the user is granted access to pods that are in namespaces to which this specific user has access. Resulting in these namespaces declaring boundaries around certain pods that can be accessed with a single namespace entry in the access policy for the specific user. Once authorized, a message is sent to the Admission Control modules, which can reject or modify requests.
The Kubernetes API has a complex structure, but the basic types of resources can be divided into 5 categories21:
- To handle and run the containers you use objects called Workloads.
- To join your Workloads in a load-balanced Service you use objects called Discovery & Load Balancing (LB).
- To initialise the application and add external data, you can use objects called Config & Storage.
- To know how the cluster is set up, use objects called Cluster resources.
- To configure certain resources in your cluster, use objects called Metadata resources.
References
-
https://kubernetes.io/docs/concepts/architecture/control-plane-node-communication/ ↩︎
-
https://kubernetes.io/docs/concepts/architecture/controller/ ↩︎
-
https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/ ↩︎
-
https://kubernetes.io/docs/reference/command-line-tools-reference/kube-proxy/ ↩︎
-
https://kubernetes.io/docs/concepts/architecture/cloud-controller/ ↩︎
-
https://www.redhat.com/en/topics/containers/what-is-kubernetes. ↩︎
-
https://kubernetes.io/docs/tutorials/kubernetes-basics/deploy-app/deploy-intro/ ↩︎
-
https://kubernetes.io/docs/tutorials/kubernetes-basics/update/update-intro/ ↩︎
-
https://kubernetes.io/docs/tutorials/kubernetes-basics/expose/expose-intro/ ↩︎
-
https://kubernetes.io/docs/tutorials/kubernetes-basics/update/update-intro/ ↩︎
-
https://kubernetes.io/docs/concepts/security/controlling-access/ ↩︎
-
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.19/ ↩︎