As mentioned in our previous articles, NVDA screen reader is an open source project with the primary goal of making computers accessible for blind and visually impaired people. In this article, we will look at the steps that the NVDA community takes to ensure the system quality, so that NVDA can achieve its primary goal and be stable and reliable for users.
Overview of System Quality Processes
In this section, we give an overview of how NVDA maintains the system quality throughout the development processes.
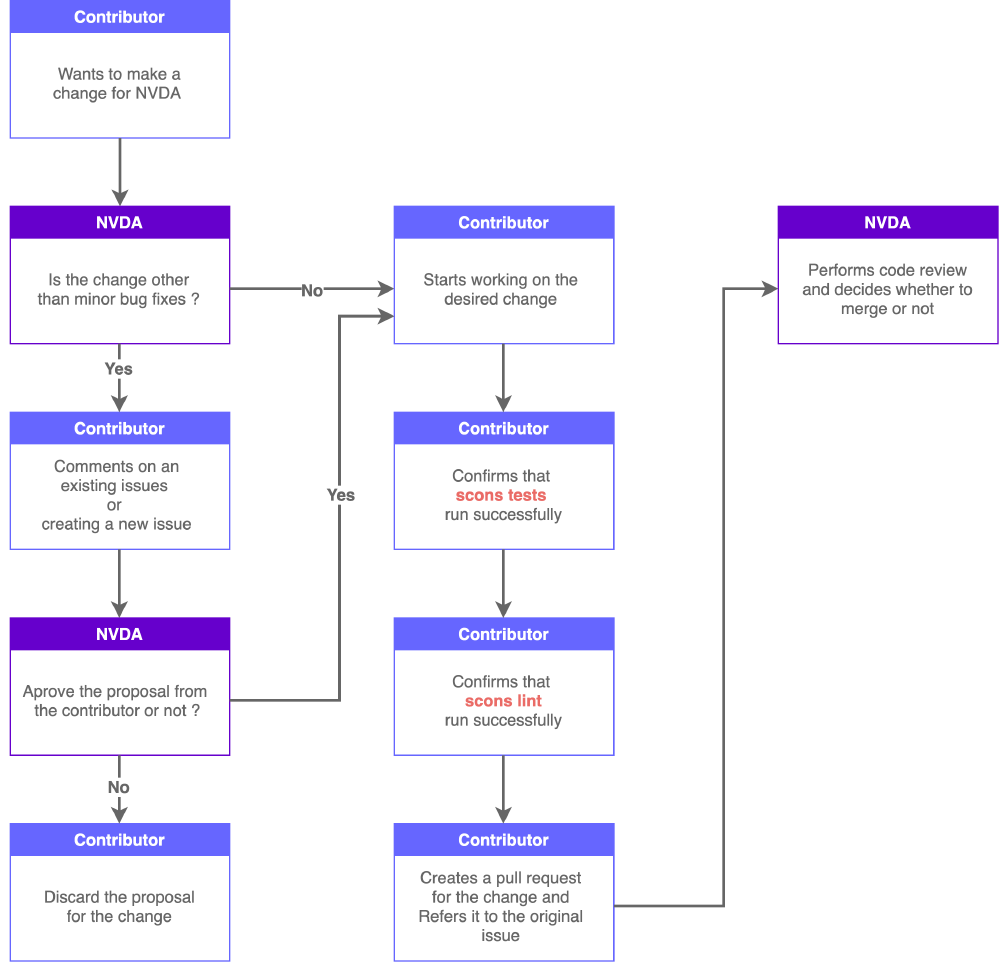
Figure: System Quality Processes
Since NVDA is an open source project, a large number of contributors come from GitHub. Thus, NVDA community provides contributing guidelines for potential contributors. The image above illustrates how those guidelines ensure the system quality between contributors and the NVDA community. The NVDA community makes use of the issue feature on GitHub to discuss contributors' proposals. Unless it is a minor bug fix, contributors need to make an issue to propose any changes and wait for approval from the main developers. The contributors also need to make sure that the code after their change passes all the tests before they open their pull request. Then, main developers decide whether to merge the pull request. Furthermore, if the change is noticeable to users, the contributors should update the User Guide accordingly. The NVDA community also provides an issue template and pull request template for contributors.
If we look into the source code of NVDA, we see that the NVDA project automatically creates a Python virtual environment and installs all the required dependencies in the environment, by utilizing the open source software construction tool SCons1 in the building process for developers.
This serves to improve the development efficiency and assure the development quality of contributors.
Integrating changes
We will now discuss how the NVDA project handles the integration of code changes with continuous integration. Let’s start with a definition; continuous integration is defined as2:
… The practice of automating the integration of code changes from multiple contributors into a single software project. Automated tools are used to assert the new code’s correctness before integration.
So how does the NVDA project handle this?
Well, to start with, the project lives on GitHub, which uses the familiar git system for version control.
To contribute code changes to the master branch, the developer makes a pull request.
Then, NVDA makes use of AppVeyor to perform automatic code quality checks.
This tool is integrated with GitHub in the form of an AppVeyorBot, which automatically builds and tests the code in pull requests by running all (system and unit) tests and code style checks.
If a test fails, the AppVeyorBot will notify the developer with a comment on the pull request, as we show below:

Figure: A failing build
If no comment is posted, then the build has passed and the code is ready to be integrated.
Test Process
Testing plays an important role in software development and serves as a guide for achieving a good design3. Thus, in this section, we will look into NVDA’s test process. NVDA provides alpha/beta4 and release versions for both developers and users to test.
NVDA advocates for developers and users to take three approaches5 for tests, which cover:
- unfocused usage
- recent change focused testing
- regression testing
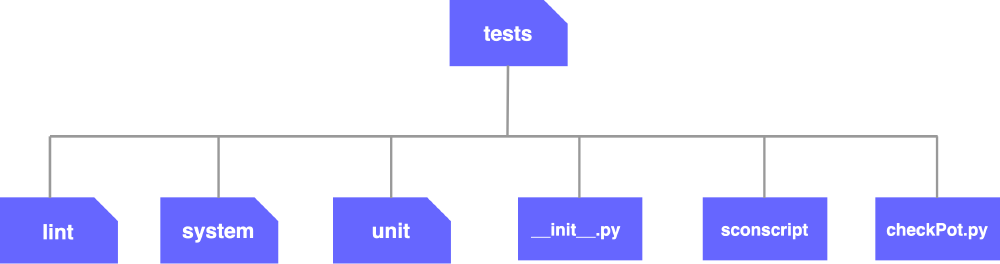
Figure:
tests folder
The picture above shows the structure of the tests folder, which contains tests for developers to execute.
Here is a brief analysis of this folder:
- Unit tests: the
unitfolder provides different tests for individual features of NVDA, for example, tests for braille display. Developers are able to test different methods in the matched unit test by specifying the method name in the testing command. - System tests: the
systemfolder provides NVDA setting files for system tests. NVDA utilizes the Robot test framework to execute system tests and make it easier for developers to write test logic and test arguments for system tests.
After analyzing the test processes and test coverage of NVDA, we will now look into the test culture of NVDA.
The tests folder consists of 4833 lines of code, while the source folder (the main production code) consists of 69483 lines of code and is around 14 times larger than test code.
In pull requests on the GitHub repository, developers often explain the testing strategy they used for their work.
However, the details of the test cases are not discussed in depth.
Thus, although the NVDA community encourages contributors to think of good tests, it seems that they still have much room for improvement.
The hotspots of NVDA
In this section we will take a closer look at the hotspots of changes in NVDA. We will not only identify which files were modified the most6, but also analyse those changes and understand why they were needed.
The hotspots
- The file which was changed the most, by far, is
user_docs/en/changes.t2t. While changes to this file don’t tell us much about code quality, it does provide a detailed log (over 3,000 lines!) of all changes to the application since its inception in 2009. - Many of the other files with a high amount of changes are either translations in
user_docs/of documentation and changes, or insource/locale/of UI elements and dictionaries. Again, good to see these are being kept up to date, but they don’t provide much insight. - Next up we have
source/gui/settingsDialogs.pyandsource/globalCommands.py. These files are responsible for handling all the different options and preferences, and handling all commands that are available at all times respectively. Most of the changes to these files were either changes in how certain settings/commands work, or the addition of new commands/settings for new features. source/NVDAObjects/UIA/__init__.pyis probably the most interesting hotspot. This file is responsible for support for Windows' UI Automation (UIA) controls. The file has been changed 89 times in the last 1,500 days, which is fairly often. Many of the changes have been bug fixes, which indicates that the file could perhaps benefit from a thorough inspection. The file is also just under 2,000 lines while containing multiple classes, so it would probably be better to break it up into smaller files. This would also help locate which part of the code specifically requires constant changes.- Finally, we take a look at
source/braille.py, which contains almost all the logic for converting information to braille. This is another monolithic file which would probably benefit from being broken up. Clocking in at over 2,600 lines and containing over 30 classes and functions, it makes sense that this file is a hotspot. This file was changed 88 times over the last 1,500 days, with a fair amount of those changes constituting bug fixes.
These are the most prominent hotspots of NVDA. Overall, most hotspots deal with translations and locale. However, there are a couple monolithic files which should probably be broken up. We will look at code quality and the surrounding culture more in-depth in the following sections.
The quality culture
We will now give an overview of the quality culture of NVDA. To do this, we scoured through numerous issues and pull requests, such as the introduction of the add-on system or the migration to Python 3.
In our first essay, we identified multiple quality attributes of NVDA which will come back when discussing the quality culture. The first thing to realize is that not only developers browse the NVDA repository, but also end-users. Before any changes, either of these two parties needs to make an issue5 so that the community members can discuss it. Thus, we will divide contributions into an issue stage and a pull request stage and discuss the most important questions that the community asks itself when discussing changes.
The issue stage
The issue stage is mainly used to discuss the design, user experience and implementation of each change.
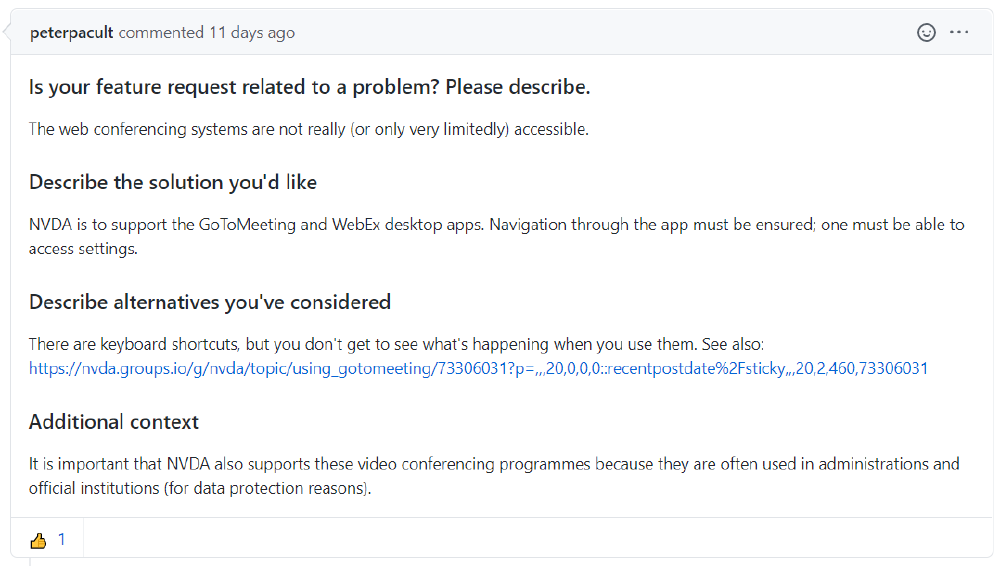
Figure: An issue posted by an end-user
Whenever a change is introduced, the first question to ask is: do we really need this?
Configurability: should we make this configurable? How configurable should we make it?
Accessibility: should this be configurable from the GUI? What kind of layout should we use to do this? Should we introduce shortcuts for this feature? Are these shortcuts practical for all languages' keyboards?
Internationalization: NVDA is available in over 55 languages7, so how do we make this work for all locales?
Performance: can we use multiple threads to implement this? What are the size, memory, battery and speed impacts of this implementation?
Backwards compatibility: will this change affect or break add-ons? Blind people tend to hold onto older software longer, so how does this change affect legacy software or operating systems?
The pull request stage
In the pull request stage, the discussions mostly relate to testing and documentation.
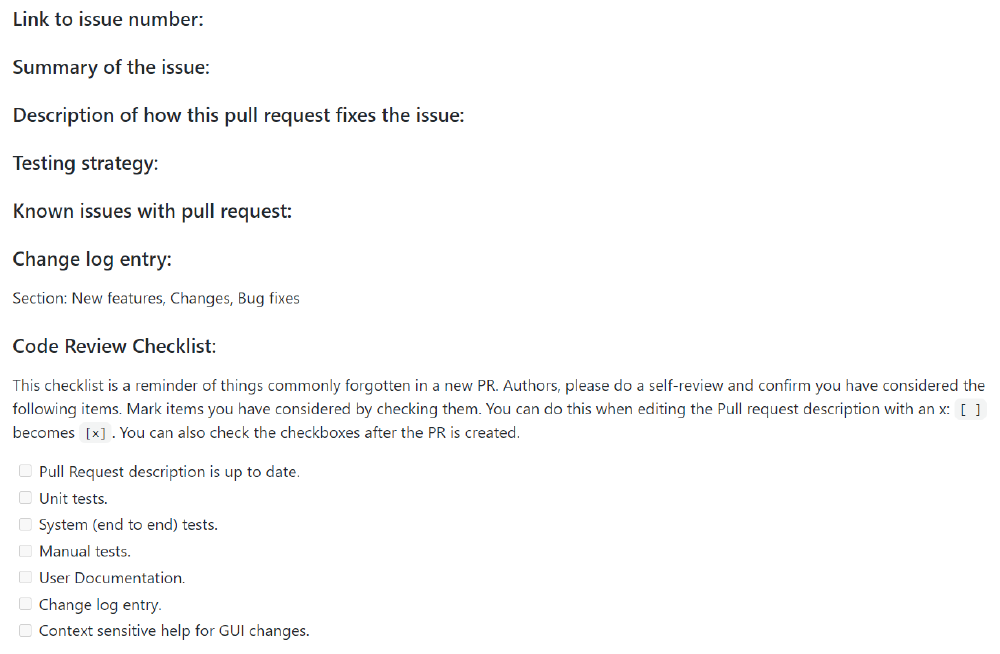
Figure: The template used for pull requests
Documentation: are the design and approach documented in the developer guide8? Is an entry for this change in the changelog provided? Is the code documented, and is this documentation understandable?
Testing: developers need to describe how they tested each change either manually or automatically. Each change is extensively tested by other developers, who then post bugs that they encounter so that they can be fixed.
After everything checks out, the change is finally ready to be merged!
This quality culture tries to ensure the system retains its quality through changes, but sometimes less than perfect changes make it through, leading to a so-called technical debt.
Technical debt
Technical debt refers to the state of the code and how much extra effort you need to go through to add new features9. After looking at how the code evolves in practice, we now examine the state of the code and what this means for future changes.
First, let’s see what static analysis tools think of NVDAs code quality. Their own setup uses the tool Flake8 to check most code quality aspects. Usually, the developers only check the changed lines with this. We ran Flake8 on the entire source folder10. You can find the output at the end of this essay, we will now have a look at what the output means. The total number of warnings is 136,346. We can discard 125,346 warnings related to whitespace placements and such. Those do not constitute technical debt, because it does not delay the addition of new features. This leaves us with 11,000 warnings that do point to technical debt. 2,060 errors are about indentation, which is often not an issue either, but in Python especially, indentation is important for understanding the code. 6,042 errors refer to imports, which may be unused or unclear. Most other warnings point to minor bugs or code that is less readable.
Pydocstyle finds 6,393 issues with the documentation formatting10. Pydocstyle does not provide numbers per error, but many are about missing docstrings for public classes and methods. This is a big issue, as this documentation is the first point of contact with the code for new developers.
We also ran SonarQube on the repository10 to see how many code smells turn up in the automatic assessment. SonarQube finds 8,559 code smells and estimates 69 days worth of technical debt. Almost 88% of the code smells refer to not following python naming conventions, the rest still leaves an estimated 20 days of debt. Notable code smells that were found are 261 cases of too high cognitive complexity in a function, 98 unused local variables or private attributes and 12 cases where method overrides change the method contract. All those smells make the code less readable and more error-prone.
To finish up, some observations from looking at the code as a new developer. The clearest point of improvement is naming and folder structure. Many python files do not have a name that immediately tells you what it does. The current folder structure is inconsistent (two similar components where one gets a folder and one does not) and many files and folders could be organised into more general folders too, to improve the overview.
Looking at these tools and our own observations, NVDA still has some work to do to improve readability and usability of the code. Code structure, naming conventions, documentation and readability are important in keeping the code maintainable and extendable. NVDA is focusing their quality checks on parts of the code that actually change. This makes sense, as technical debt is not an issue in places where you do not change the code. This way, they are slowly fixing the debt in the places where it matters most.
Conclusions
In conclusion, NVDA ensures quality by checking if changes are desired and how the key attributes are met, and by testing changes using continuous integration. Some of the hotspots could be split for more clarity and some technical debt is still present.
Appendix
Output of Flake810.
53 E101 indentation contains mixed spaces and tabs
2 E111 indentation is not a multiple of four
5 E114 indentation is not a multiple of four (comment)
5 E115 expected an indented block (comment)
20 E117 over-indented
103 E122 continuation line missing indentation or outdented
13 E124 closing bracket does not match visual indentation
100 E125 continuation line with same indent as next logical line
1697 E128 continuation line under-indented for visual indent
62 E131 continuation line unaligned for hanging indent
3405 E201 whitespace after '('
3396 E202 whitespace before ')'
477 E203 whitespace before ','
12 E211 whitespace before '('
22 E221 multiple spaces before operator
12 E222 multiple spaces after operator
1 E224 tab after operator
9812 E225 missing whitespace around operator
242 E227 missing whitespace around bitwise or shift operator
350 E228 missing whitespace around modulo operator
9452 E231 missing whitespace after ','
221 E251 unexpected spaces around keyword / parameter equals
1 E252 missing whitespace around parameter equals
1040 E261 at least two spaces before inline comment
124 E262 inline comment should start with '# '
1494 E265 block comment should start with '# '
6042 E266 too many leading '#' for block comment
33 E271 multiple spaces after keyword
6 E272 multiple spaces before keyword
1 E273 tab after keyword
64 E301 expected 1 blank line, found 0
1762 E302 expected 2 blank lines, found 1
35 E303 too many blank lines (2)
1 E304 blank lines found after function decorator
391 E305 expected 2 blank lines after class or function definition, found 0
16 E306 expected 1 blank line before a nested definition, found 0
1 E401 multiple imports on one line
234 E402 module level import not at top of file
9727 E501 line too long (80 > 79 characters)
197 E701 multiple statements on one line (colon)
10 E702 multiple statements on one line (semicolon)
5 E703 statement ends with a semicolon
11 E711 comparison to None should be 'if cond is None:'
3 E712 comparison to True should be 'if cond is True:' or 'if cond:'
2 E713 test for membership should be 'not in'
245 E722 do not use bare 'except'
10 E731 do not assign a lambda expression, use a def
9 E741 ambiguous variable name 'l'
255 F401 'time' imported but unused
73 F403 'from ctypes import *' used; unable to detect undefined names
5714 F405 '_' may be undefined, or defined from star imports: comInterfaces.Accessibility, comInterfaces.IAccessible2Lib, ctypes
22 F811 redefinition of unused 'globalVars' from line 29
2554 F821 undefined name 'sys'
31 F841 local variable 'rgb' is assigned to but never used
74573 W191 indentation contains tabs
1032 W291 trailing whitespace
11 W292 no newline at end of file
77 W293 blank line contains whitespace
9 W391 blank line at end of file
11 W605 invalid escape sequence '\w'
1032 WT291 (flake8-tabs) trailing whitespace
26 WT293 (flake8-tabs) blank line contains unaligned whitespace
-
https://www.atlassian.com/continuous-delivery/continuous-integration ↩︎
-
https://se.ewi.tudelft.nl/delftswa/2021/slides/architecting-for-change.pdf ↩︎
-
Identifying files with high churn rates was done using this tool ↩︎
-
https://www.nvaccess.org/files/nvda/documentation/developerGuide.html ↩︎