This article has been divided into 8 sections, where we, four Embedded System master students from Delft University of Technology, will analyze this open-source project named PaddleOCR developed by Baidu Company. The first two sections will give a general view of it. Following that, it will analyze the main capabilities and usage of the product. Then, the stakeholders and the key attributes will be presented. Besides, it will explore the roadmap of this application. Finally, it will show the probable ethical issues of this current work. The structure of this article has been shown below:
- Introduction
- Domain Concepts
- Main Capabilities
- Context
- Stakeholders and Demands
- Key Quality Attributes
- Product Roadmap
- Ethical Analysis
- Conclusion
- Reference
Introduction and Goal of PaddleOCR
OCR(Optical Character Recognition) techniques have been developed to covert text-based documents into digital documents, whose application has skyrocketed recently. According to different recognition scenarios, OCR tools can be divided into general OCR tools and domain-specific OCR tools.
PaddleOCR is an open-source general OCR tool, which can use the original “Paddle” algorithm to support character recognition with light weight and multilingual features. It can position text in static and dynamic pictures regardless of their orientation and languages. The small-volume program could extract texts in the pictures with response time shortened to a microsecond.
For developers who are interested in OCR and deep learning, this project also provides a platform on which they can train and develop their ultra-lightweight model with the pre-trained model in PaddleOCR, making it an excellent tool for understanding the technology of deep learning and optical character recognition.
In the field of OCR, there exists a trade-off between effect and efficiency. The former refers to the accuracy of recognition, and the latter refers to reaction time. PaddleOCR apparently pursues a shorter response time and smaller size, which is not suitable for high-accuracy demand.
Domain Concepts
As a general OCR tool, PaddleOCR can be embedded into enormous applications, which is an excellent example of utilizing AI technology to create a paradigm shift in almost every field of technology industry.
PaddleOCR has three deployments - inference, serving and mobile Paddle Lite, which provides users and developers with flexible choices for different application scenarios. More specifically, inference and serving deployment are designed for local offline applications and the cloud, respectively. Mobile deployment can be implemented by compiling in Paddle Lite, which provides inference capabilities for mobile phones and IoTs, and integrates cross-platform hardware widely, providing lightweight deployment solutions for end-side deployment problems.
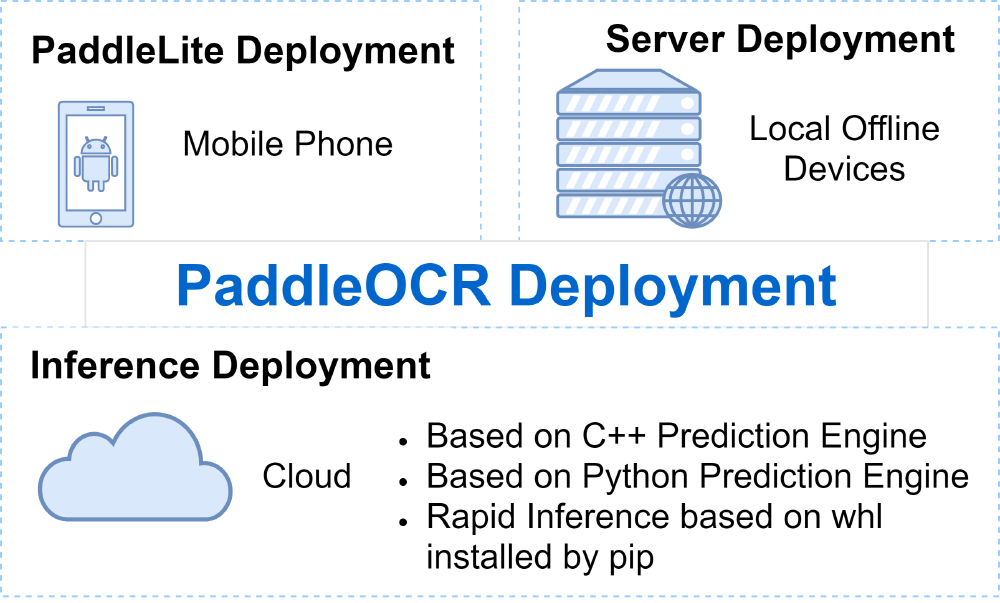
Figure: The Deployment of PaddleOCR
Considering its small size and response time, PaddleOCR is mainly designed for scenarios requiring high speed instead of precision. More specifically, it provides OCR support for IoT devices with limited computing power and storage space.
Currently, the demand of deploying artificial intelligence models on mobile and embedded devices is growing, mainly for two main reasons. Firstly, the enterprise may succumb to high cost brought by setting up a cloud server for the AI model. Secondly, users benefit from effective privacy protection because their pictures would be calculated in the local mobile terminals rather than servers in the cloud.
IoT devices are characteristic with embedded and mobility, which brings the challenge to the efficient deployment of the Neural Network model on devices with limited computing power, low power demand and small memory. So developers could optimize the trained models by compressing model size and reducing computation during the deployment process to adapt to the limitations of computation power, energy and space, which leads to the compromise among accuracy, efficiency and flexibility of the model.
Main Capabilities
OCR systems have been used widely in variously different application scenarios. It is widely used both in factory automation, financial business, government business, and so on. There are several examples of the application scenarios of OCR. Firstly in the financial business, the OCR system can be used in the information extraction of business documents, like cheque, invoice, personal statement and receipt. Also, it can be used in automatic insurance documents and digital images of printed documents or books to make the documents searchable, e.g. Google Books. It also contributes a lot to the assistive technology for visually impaired users 1. Secondly, in factory automation, the OCR system is used in stamping and reading engraved parts with serial numbers to avoid mistakes in the production line. For example, at food factories to track the date codes, lot code and batch verification, and expiration dates to ensure food safety. Besides, in government business, it plays an important role in customs which is used to scan passports. Regarding infrastructures, in airports, it is used for passport recognition and information extraction. OCR is also can be used in traffic sign recognition. 2

Figure: Example of PaddleOCR Capabilities
Here the Paddle OCR is an ultra-lightweight OCR system designed to compensate for the computational cost. The overall model size is only 3.5M for recognizing 6622 Chinese characters and 2.8M for recognizing 63 alphanumeric symbols respectively. The PP OCR system can fit in a much smaller size embedded and mobile system. The low resource consumption determines the versatility of the applications, e.g. hand-held small devices.
Context
As we mentioned above, Paddle OCR can be applied in many contexts currently. As for now, the OCR follows some basic steps, including image pre-processing, character recognition and post-processing in OCR.

Figure: The framework of PaddleOCR
Paddle OCR follows the basic steps: The first step is image pre-processing in OCR, after pre-processing Paddle OCR will detect text. After text detection, it will rectify the detection boxes horizontally. Then it will recognize the text content and output the recognized image which is also called image post-processing.
As for the future context, it has been proposed in recent years that OCR systems deal more efficiently with specific types of input. Except for the specific lexicon, to achieve a higher-level performance, current OCR systems may take business rules, standard expression, or rich information contained in color images into account, which is called “Application-Oriented OCR” or “Customized OCR”, and has been applied to OCR of license plates, invoices, screenshots, ID cards, driver licenses, and automobile manufacturing. 4
Stakeholders and Demands
The stakeholders involved in this project covers industry, education, and independent developers.
Enterprises that need to develop embedded products with OCR can utilize this open-source project. Enterprises can obtain economic benefits. The lightweight feature of the system makes the hardware cost lower and eliminates the main process of OCR function development which saves software development costs. Software development and manufacturing costs reducing make it more competitive and profitable.
For universities and research institutions, they can use it for educational purposes. This project provides feasible solutions in the field of lightweight OCR. What’s more, PaddleOCR offers a research foundation and new thinking directions, which will nurture more innovative projects.
Independent developers can also benefit from this project by not only training their models but expanding development based on PaddleOCR. This project provides a lightweight OCR solution for independent developers, saving a huge amount of development time.

Figure: Skateholders
Key Quality Attributes
Although PaddleOCR faces a lot of challenges like other ORC implementations, its technical innovations endow itself with splendid key features.
PaddleOCR supports up to 27 languages, but also different font types can be recognized. Only 9.4M of storage space is required for deployment on mobile devices. The system also supports a variety of mainstream platforms, which provides unlimited possibilities for the deployment of OCR technology. Whether it’s low-brightness pictures, vague pictures, curved text and small fonts. PaddleORC can accept the test of various usage scenarios.
PaddleOCR is also support for user-defined. For the user who wants directly implement the system. No training figures need to be provided to the system, there is already a pre-trained model. For the user who wants to apply this to special scenarios, to recognize a set of similar characters in a specific environment, PaddleOCR gives user-defined training access.
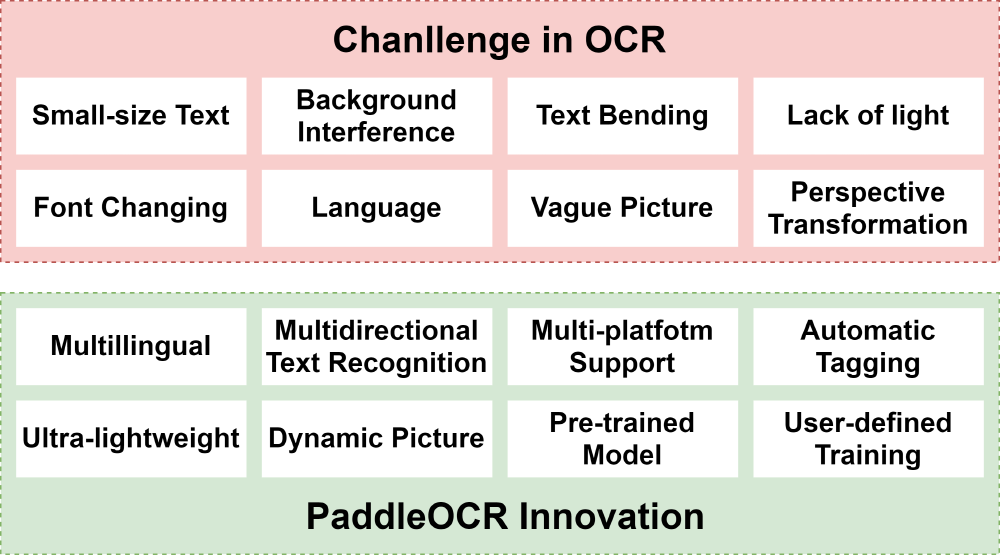
Figure: Innovation of PaddleOCR and Current Challenges
Product Roadmap
The developing log of the product starts from May 2020 which mainly records two developing directions. One of the directions is tuning the model shown in the right-hand of the below figure, and another one is developing the inference for different platforms shown in the left-hand of the figure.
In terms of improving the model, the developing team keeps 1) training and updating the parameters to achieve higher accuracy; 2) improving and adding algorithms to increase the flexibility of the model; 3) shrinking the size of the model; 4) providing different language’s supports.
Turning to multiple platforms supporting development, the designers provide 1) various inference for PCs and mobile devices; 2) professional and non-professional documents for different users; 3) untrained model, pre-trained models and trained models for different usages.
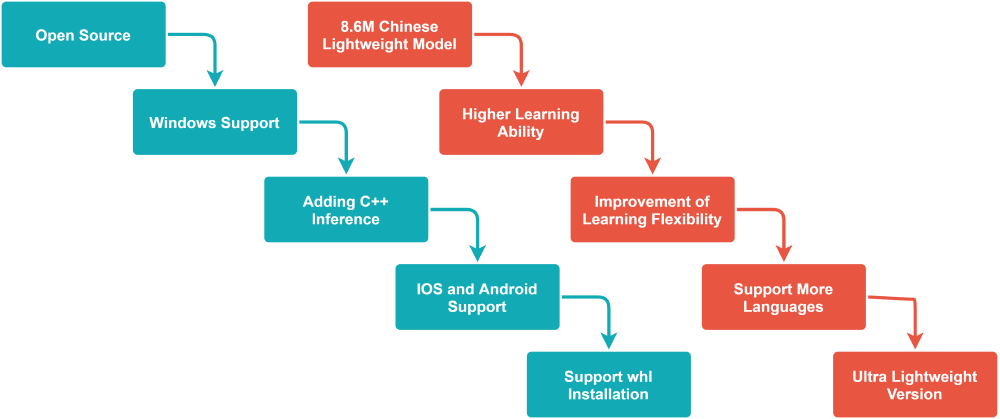
Figure: Product Roadmap
The former direction promotes the qualities of the product, such as accuracy, flexibility and installation size. For a learning-and-predicting model which is mainly applied to limited-memory devices, a tolerated accuracy, comparable compatibility and reasonable memory occupation are the main attributes to attract potential customers. The higher qualities a product owns, the easier customers will be fascinated by it. In addition, when the quality of a product meets the expectations of customers, it will win unshakeable customer loyalty. Currently, the model occupies merely 2.8M for recognizing 63 alphanumeric symbols with a fast responding speed (less than 3ms for an image).
The latter one extends its market. Different customers apply it for different purposes. It supports Linux, Windows, macOS as well as other mobile systems (IOS and Andriod). Not only can the algorithms and model be trained to extract the word script, but also it can be used for many other feature extractions. For instance, Chuang Ying Time uses it for garbage classification which achieves more than 97% accuracy. Multiple applicable fields guarantee a sufficient number of customers and reduce the risk of failure in one domain where it may fail when it competes with other products.
When it comes to future developments, PaddleOCR should mainly focus on the following aspects. Firstly, it should improve the current image enhancement technology. In so far, it can extract the features accurately from a high-quality image but when the input image’s quality is low, it cannot performs well. Secondly, the number of languages that it supports is still limited if PaddleOCR aims at the global market. Thirdly, it will continue to develop a server version that can be used in devices with higher computing power. Currently, it has a 143.4M server version. The Internet of Things is a trend. All devices without strong computing power tend to connect to the network in order to obtain computing power from the cloud servers, so a server version is necessary. Finally, the team is also trying to extend the paddle algorithm to many other fields, like medicine, manufacturing, agriculture and so on.
Ethical Analysis
We find that this product mainly fronts the following ethical problems. Firstly, it does not have a proper encryption scheme for the server version - people may leak their privacy when using it to scan the images. Suppose that we are scanning our daily diary to convert it to an electronic version, of course, we do not prefer someone else can see the content. However, using the unencrypted transmitting and translating scheme will reveal the content. Furthermore, one can extract the text from the paper publications protected by the copyrights. Thirdly, it may lead to unemployment for the people who originally work on the manufacturing pipelines. Although the PaddleOCR itself may not impact significantly on it, the algorithm “Paddle” behind it, similar to AI, has been applied in many fields such as public transportation, medicine, education where the algorithm shows an exceeding performance compared to a human. Besides, it will generate another problem when it is used in some field with high-demanding. For instance, arbitrarily using the prediction will cause misdiagnosis. In conclusion, we realize that the algorithm with its applications should be restricted by moral standards and legal laws.
Conclusion
OCR has been widely used in various applications nowadays, however, Paddle OCR is an ultra-lightweight system that addressed the problem of a variety of text appearances and high computational efficiency demand. In this essay, we discussed the promising prospects of the new Paddle OCR and we hope we can make contributions to the newly-proposed light-weighted OCR.