This is the fourth article of the series relevant to PaddleCOR. This essay will mainly analyze the variability of PaddleOCR. If you are interested in this content, you can also visit our former ones.
Variability Modeling
In this section, we will identify the variabilities/functionalities offered by PaddleOCR and introduce the benefits for stakeholders as well as the incompatibilities between these variabilities.
Variable Features Benefit Stakeholders
The features of an application include its special characteristics, functionalities, etc. This section will select the 12 most noteworthy features which make PaddleOCR different from other similar products and analyze how they benefit the stakeholders and contribute to the user experience. Most of the selected features reveal the variability of the application.
- Variable Implementation Size
“Ultralight” is the most significant feature for PaddleOCR and it is also used as the slogan for this application. The whole OCR model consists of three submodels, a 3 MB detector, a 1.4 MB direction classifier, and a 5 MB recognition processor, so the total size of the model is 9.4 MB. Besides, the ultralight size does not much adversely influence the processing speed and accuracy. This feature means that the model can be implemented using fewer resources and computational power. The enterprises which apply this application to make products can cut down their hardware costs and energy consumption, as it does not require devices with large memory. In addition, this kind of reduction also obeys the concept of sustainable design, contributing to environmental protection. In addition, it also provides a general size model(143.4M) which can achieve a higher accuracy but the trade-off is the implementing size.
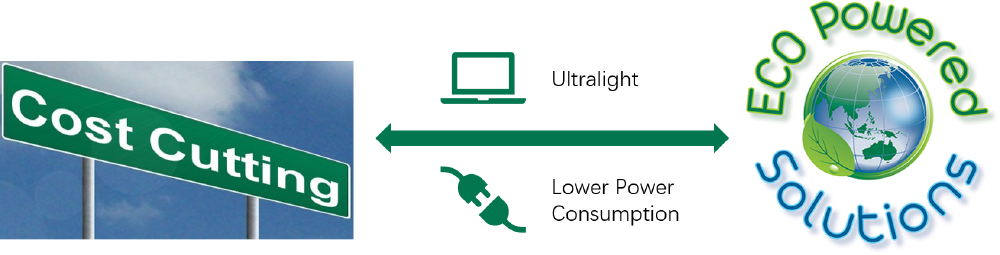
Figure: Ultralight Implementation Benefits
- Sufficient Document Support
A deep learning project sometimes is tough for a beginner to learn, but PaddleOCR provides a large number of documents to support a beginner to start her/his journey. The documents are offered either from the official organization or non-official individuals. Since PaddleOCR is also widely used for educational purposes, adequate guideline better supports students. In return, more developers can involve in this project and contribute to it. Some parts of the documents can be found in Quick Start Doc, Paddle Community and online lectures.
Figure: A Screenshot from YouTube
- Recognition Flexibility The PaddlOCR can also be used for recognizing the texts with the artistic formats or written on a special texture, which makes PaddleOCR surpass the traditional OCR tools. The applicable range will be much wider, which benefits the commercial users.

Figure: Recognition Testing
-
Data Format Compatibility The application can read various formats of images. For instance, the input can be jpg, bmp, png, rgb and tif. Not limited to static inputs, starting from release 2.0, PaddleOCR can also accept dynamic inputs such as gif.
-
Platform Transplantability Paddle provides the implementation for different platforms including Windows, Linux, macOS, Andriod, IOS. It also benefits the commercial users and enterprises who want to use the application to build the products on different platforms.
-
Programming Language Variability The application provides different language inferences, including Python, CPP and GO. It benefits both the developers and learners since a user has her/his own preferable programming languages.
Figure: Feature Model
- Modular Separability The design follows modularization which simplifies the module management and extends the scope of application. Thus, some modules in PaddleOCR can be applied in other Paddle applications and other fields such as medicine and agriculture as well. It is not necessary to develop another similar application from nothing. This feature benefits both \s.
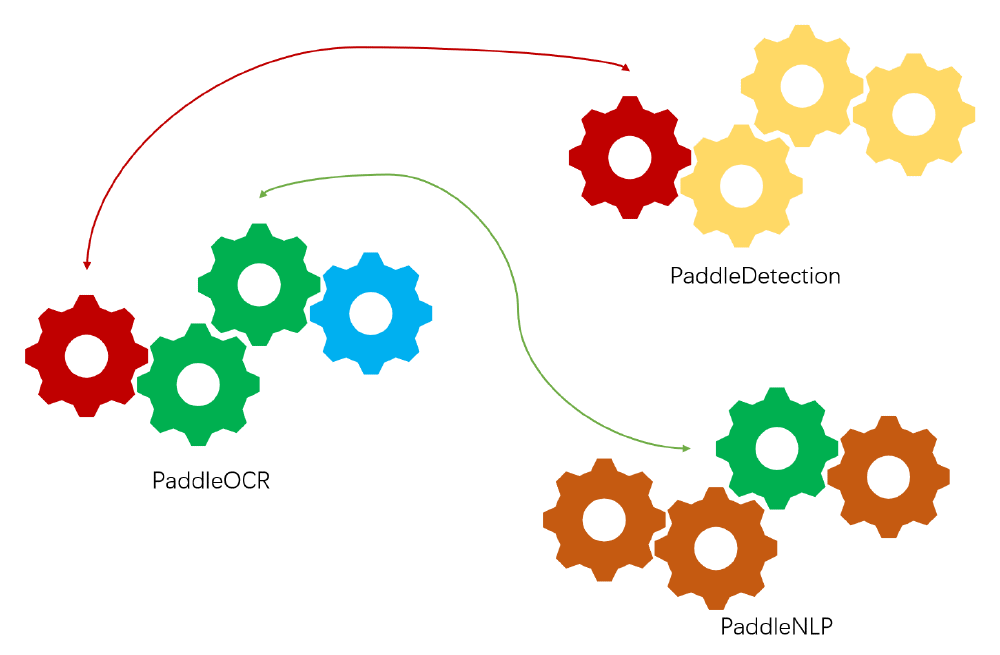
Figure: Modular Separability Diagram
-
Processing Speed For a single image, it merely spends less than 1 second to obtain the result and the accuracy is approximately 70%. These data are retrieved from their paper published in 2020. This benefits the enterprises which require the high reaction speed of their product.
-
Algorithm Versatility Some developers also apply the core algorithm, “PaddlePaddle”, into other relative image/video processing algorithms like segmentation (PaddleSeg). This feature benefits some other developers who want to employ a mature algorithm to develop their products rather than building a brand new algorithm from scratch.
-
Customized Model Despite that some pre-trained/trained models have been already provided by the Paddle official team, people can still train their models using their own dataset easily. For instance, people can rebuild the model for recognizing any other languages rather than the English alphabets or Chinese words.
-
Simple Operation The simplicity of the operations promotes the user experience. For the people who do not have much preknowledge with regard to OCR, they can play with it using the online version or using the mobile demo version like the figure shown below.

Figure: Online & Mobile Demo
- Continue Updating To cater to the trend of IoT, the Paddle team also creates a hub server version that supports remote data reading and processing. It can benefit users without powerful local computational devices. More features are still under development according to the current feedback, they will benefit the educational, commercial users, and developers in the future.
FeatureIDE Model
The following figure shows the feature variability model6 of PaddleOCR. Before installation, users can select which platform PaddleOCR will be applied. The modules are all necessary to be included except “Data”, as it is only useful when training. Furthermore, the model has different versions that users can select, including various model sizes, predicting&training algorithms, target languages, and etc. Besides the original application, the developers of PaddleOCR also offer some training tools for users to make their own datasets and model.
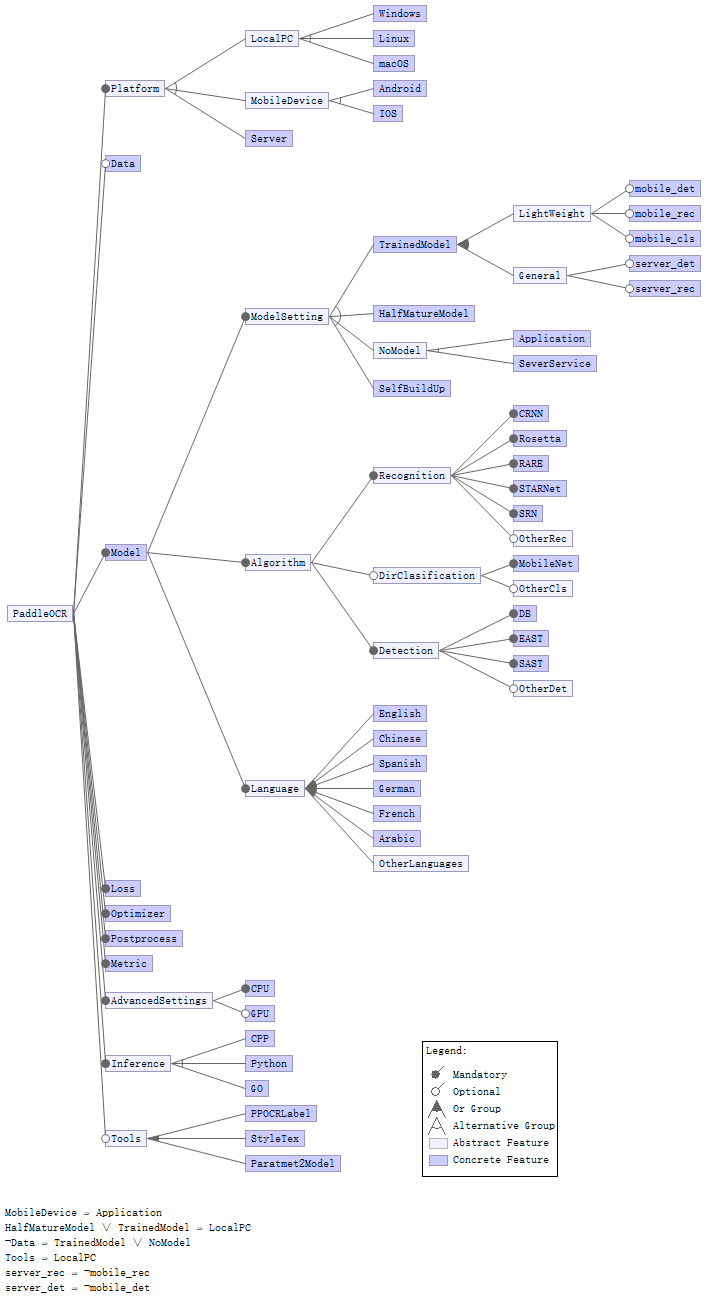
Figure: Feature Model
Incompatibilities between The Variable Features
The incompatibility between features refers to the conflict of applying multiple features simultaneously. In other words, users may not employ some features when another feature has been applied. Here we list four main incompatibilities in PaddleOCR.
The platform where PaddleOCR is implemented causes the main conflicts. The incompatibilities brought by the platform include application, model setting, and tools. Firstly, users can only use the PaddleOCR App on mobile devices, different from inputting command lines on PCs. Secondly, building half-mature and self-trained models can only be realized on PCs. The third restriction is the useful tools in model training - PaddleLabel, Style-Text, annotation, and synthesis tools can only be used on PCs too. The fourth point is that self-trained and half-mature models require users to input the dataset manually, otherwise, the model module cannot be successfully built.
Variability Management
Variability Management (VM) in software systems requires adequate supports to deal with the ever-increasing complexity7. Variability Management encompasses the activities of explicitly representing variability in software artifacts throughout the lifecycle, managing dependencies among different variabilities, and supporting the instantiations of those variabilities. Since one of PaddleOCR’s main goals is to extend the diverse applications, the development team has to propose a variable plan to deal with the different development directions and user requirements.
The stakeholders involved in PaddleOCR cover industry, education, and independent developers. PaddleOCR maintains highly customizable, expandable, and changeable for the industry. Enterprises can transform this system according to their requirements. In addition, an open-source system and an open attitude of the development team are also in the interest of education and independent developers. They have enough information to study this system and can study this system without restrictions. The PaddleOCR team manages the variability mainly in the following three aspects. They care about user experience and future development.
Users Make Their Own Choices
The main sources that users refer to when deploying different implementations are PaddleOCR’s open-source website and open courses. PaddleOCR provides a variety of different deployment methods, and also supports users to change and extend the system. Users can learn about the applicable hardware and platform of the system from these resources, and thus choose the suitable deployment plan. For example, PaddleOCR supports Windows, IOS, and Android systems. Users can easily find deployment tutorials for different platforms.
Feedback Helps
PaddleOCR uses documentation to manage variability. PaddleOCR has detailed management plans and future plans for resource sharing and document maintenance. The development team provides detailed tutorials and open source projects by holding open class, committed to helping everyone that wants to implement this system. For different deployment scenarios, such as service-based deployment and end-side deployment, the development team provides targeted usage tutorials.
In addition, there is a weekly updated FAQ document. The user feedback thus obtained is a ‘huge treasure’. When more comments and suggestions are adopted and added to existing documents, the team can find more potential system features, user requirements, and document defects. The PaddleOCR development team has always maintained an open attitude to changes, and that feedback gives developers directions and opportunities to expand and optimize the entire system.
Design for Future
For the development process of PaddleOCR, it has been using a multi-directional parallel development mechanism to deal with the variability issues. Due to the sophisticated modular design of the system, multi-directional parallel development can handle the expansion and change of different functions of the system at the same time.
In the second half of 2020, PaddleOCR carried out these updates at the same time - adding a multilingual recognition model, providing additional deployment plans, updating annotation tools, etc. For most system changes, this general mechanism can make a certain directed update without the need for the overall system to participate in testing, which can drastically shorten the development cycle.
Variability Implementation Mechanism
To describe how various features can be realized on the design and code level, researchers in the software product line community addressed the notion of variability mechanism 10 years ago1. In the figure below we simply show the software product line of PaddleOCR. This figure reflects that the variability implementation mechanism bridge the gap between domain analysis and product derivation, which plays an indispensable role in software design and development.
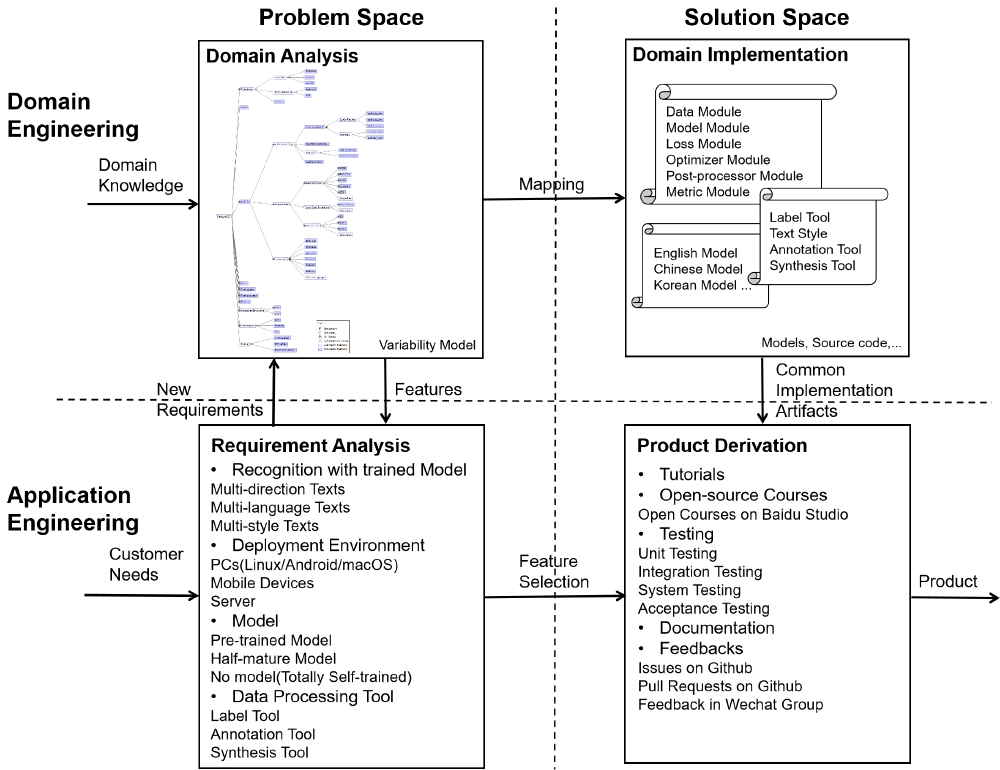
Figure: Software Product Line for PaddleOCR
Variability implementation mechanism serves as the key to deal with variability design and system complexity. This section analyzes two variability mechanisms applied in PaddleOCR along with its binding-time analysis. Binding time2 in mechanism reflects when the variable features are realized in the source code, including construction time, compile time, and run-time.
As aforementioned, the variability of PaddleOCR lies in its various choices of deployments, platforms, model configurations, and so on. To realize the variability, different implementation mechanisms have been applied. The diversity and separability of models is a typical example of framework, component and services2 and conditional execution1 plays an indispensable role in customized model training. According to the characterization1 of the variability mechanism, the benefits, and challenges brought by the variability mechanism of PaddleOCR will be discussed below.
Model Diversity & Separability - Framework, Component and Services
As we analyzed in the essay2, PaddleOCR’s modular architecture style not only divides the steps of extracting texts from pictures into six modules but also contains diverse algorithms in one module to get an optimal result. Moreover, each module in PaddleOCR - data, model, loss, optimizer, postprocessor, or metrics - could be applied in other Paddle applications. All these are the representation of the diversity and separability of PaddleOCR’s model, which is realized by the variability mechanism - framework, component, and services.
Framework refers to an incomplete set of collaborating classes to be extended for specific use cases, just like that each module in PaddleOCR could be further trained and modified by other developers who use PaddleOCR as their deep learning project. Components and services are units of composition with well-defined interfaces which can be composed to build a specific product, which corresponds to the feature - model separability.
The binding time of framework, components, and services is in the software’s early phase, always the construction time2. This mechanism enables any user to separate code from one to another appropriately if feature functionality can be modularized clearly, which endows PaddleOCR with portability, reusability, and flexibility. However, this seemingly fantastic feature could pose great challenges to developers as all these approaches require certain know-how and discipline of the software. What’s more, modular architecture always causes overhead at run-time.
Customized Model Training - Conditional Execution
The customized model training in PaddleOCR aims at guiding deep-learning developers to train their own model, along with in-depth documention on Github. By allowing modification of the configuration parameters in each module, PaddleOCR apparently utilizes a conditional execution mechanism to implement customized model training. To be more specific, all these variabilities are configured after compilation.
Conditional execution is known as an easy implementation without too much commitment to learning. Moreover, this mechanism’s binding-time is run-time1. In other words, variabilities realized by conditional execution are instantiated in a very late phase, bringing high flexibility and supporting dynamic adaptations.
Future Extension - Challenges and Benefits from Mechanism
As a modular architecture project, PaddleOCR tends to offer various choices for users with different requirements including platforms, application domains, model types. And most of these variabilities are implemented during the initial period - before compilation. We can also see from the roadmap that updates mainly focus on the extension of new language recognition, new tools, and superior models, which can be added or upgraded according to users' personal needs.
The profit of variability mechanisms with early binding time resolves the variability configuration space early. Meanwhile, the liability of the modular architecture is the overhead of implementing undesired modules and data transformation among modules. Early binding time can potentially optimize the running efficiency based on the appropriate design of code and explicit documentation.
Reference
[1] Bo Zhang, Slawomir Duszynski, and Martin Becker. “Variability Mechanisms and Lessons Learned in Practice”. 1st International Workshop on Variability and Complexity in Software Design. 2016.
[2] J. Meinicke et al. “Mastering Software Variability with FeatureIDE”. Springer International Publishing. AG 2017.
[3] Jan Bosch, Rafael Capilla, Rich Hilliard.“Trends in Systems and Software Variability”. IEEE Software. May 2015.
[4] Eric Norman Eide.“Software Variability Mechanisms For Improving Run-time Performance”. Doctor of Philosophy in Computer Science. School of Computing, The University of Utah. December 2012.
[5] Lengyel, László Levendovszky, Tihamer Charaf, Hassan. (2004). Constraint handling in feature models.
[6] T. Thum, C. Kastner, S. Erdweg and N. Siegmund, “Abstract Features in Feature Modeling,” 2011 15th International Software Product Line Conference, Munich, Germany, 2011, pp. 191-200, doi: 10.1109/SPLC.2011.53.
[7] Danilo Beuche, Holger Papajewski, Wolfgang Schröder-Preikschat, Variability management with feature models, Science of Computer Programming, 2004, ISSN 0167-6423.
[8] David Hutchison, Takeo Kanade, Josef Kittler, et al. “Software Architecture”. 5th European Conference, ECSA 2011. Sep. 2011.
[9] Juliana Freire. Emanuele Santos, et al. “The Architecture of Open Source Applications”. Jan. 2011.