Spark - Distribution Analysis
Introduction of distributed components of Spark
This essay mainly talks about the distribution components of Spark. Unlike traditional distribution Internet service, distributed computing has a quite different architecture.
Spark is well known for its powerful distributed calculation ability. The three main components that are critical to the distributed calculation of Spark are Spark cluster manager, Resilient Distributed Dataset(RDD) and Directed Acyclic Graph(DAG).
Cluster manager
The cluster manager is another important part of the distributed calculation of Spark. The cluster manager is a centralized component of the system which is responsible for coordinating computation.1 The computation includes two parts. The following figure shows the working principle of the Spark cluster manager.
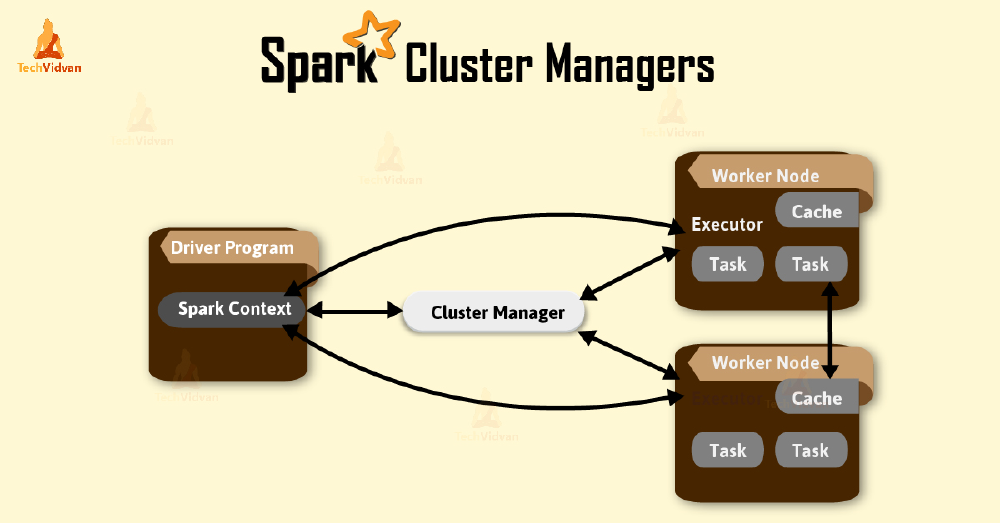
Figure: broadcast
Resilient Distributed Dataset (RDD)
Resilient Distributed Dataset (RDD) is a fault-tolerant and parallel data structure, which is a critical concept of Spark. RDD is read-only, flexible, memory-based, fault-tolerated and distributed. As a read-only component, it is impossible to edit an RDD, but users can create a new RDD through a modification process.
While working, every RDD can be divided into several logical partitions, and each part is a data segment. Different partitions of one RDD can be stored in different nodes in the cluster, and then do parallel computation on these separated nodes.2 Thanks to this function, data can be stored in memory rather than discs. This enables Spark to take data out directly from memory while computing, rather than reading discs through the IO port, which significantly saves the data transmission time. Hadoop reads all data from disk IO, so it’s much slower than Spark.
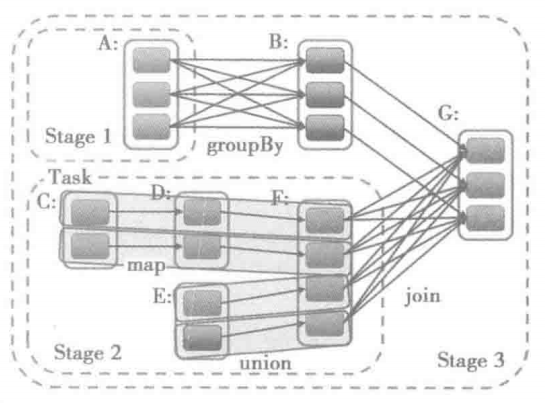
Figure: broadcast
Directed Acyclic Graph (DAG)
Directed Acyclic Graph(DAG) is a sequence of computations performed on data where each node is an RDD partition, and the edge is a transformation on top of data. As its name indicates, DAG flows in one direction from early to late in the sequence. When users call an action, DAG is submitted to DAG Scheduler. Then it is further divides the graph into the stages of the jobs. In Spark, the DAG logical flow of operations is automatically created, which helps to minimize the data shuffling all around. This reduces the duration of computations with less data volume. It also increases the efficiency of the process with time.3
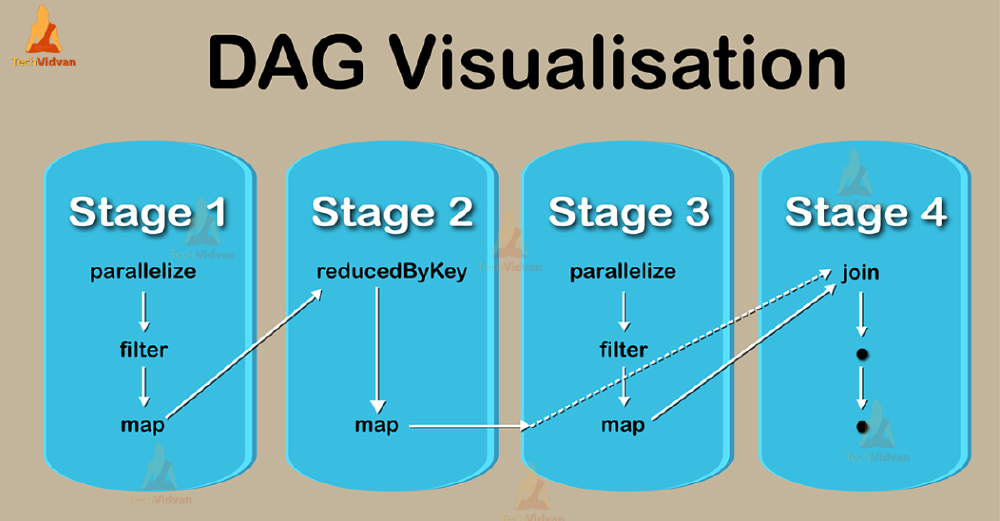
Figure: broadcast
Distributed Computing in Spark
Beginning with a resource in Spark, the data can be read from the source included in the resource. Loading data into Spark contains the following steps: load-transform-write DAG(directed-acyclic-computational-graph). Specifically, DAG in Apache Spark contains vertices and edges, where vertices mean RDDs and edges mean the operations for RDD.
RDD in Spark is partitioned into logical partitions, which means that each partition can operate parallelly. For an Apache Kafka topic with 32 partitions, Apache Spark could automatically transform the read stream from the resource into an RDD that contains 32 partitions to remain the original Kafka partitioning scheme. As a result, Spark Executors could distribute to process jobs.
When the distributed data collection represented by RDD needs to be re-distributed, shuffling happens for it. The most common situation that we need to re-distribute data can be found as follows:
Loosely, Shuffling is the procedure of data transfer between stages, in other words, it is a process where the reallocation of data between multiple Spark stages. Also, the data dependencies from node to node is the communication way in RDD shuffle.
Shuffle write and Shuffle read are operations in the stages of Spark. Both of them are executed independently for each of the shuffled partitions.
Shuffle write
Shuffle write is the sum of all written serialized data on all executors before transmitting, which always happens at the end of the stage. The amount of data records as well as the sum of bytes written to disk can be done during a shuffle write operation.
Shuffle read
Shuffle read is the sum of reading serialized data on all executors at the beginning of a stage.
Spark provides two types of variables for parallel operations: Broadcast variables and Accumulators. The broadcast variables are read-only and are shared between all computations by the cluster. Also, accumulators work well as data aggregators5.
Broadcast variables
In Spark RDD and DataFrame, Broadcast variables are read-only shared variables cached in a serialized manner on all available nodes in a cluster for accessing and using in the tasks. Instead of sending this data along with every task, Spark distributes broadcast variables to the machine using efficient broadcast algorithms to decrease communication costs. For example, the broadcast variables are already cached. They will not be shipped whenever a task computes them, which reduces the network I/O included in the spark job. The whole process can be found the following figure that is referred from 6:
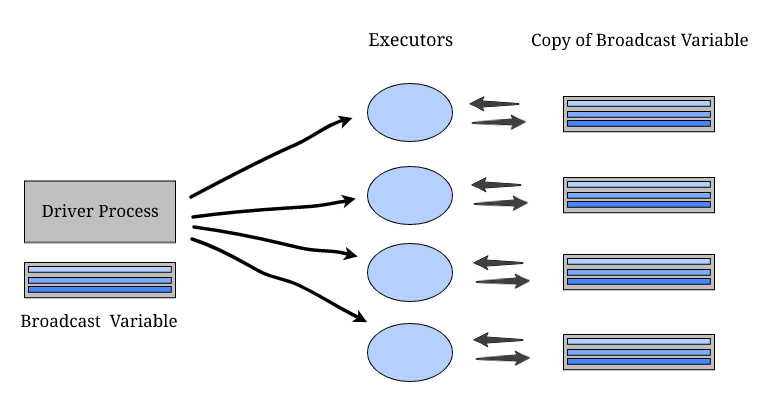
Figure: broadcast
- Firstly, Spark breaks the job into stages that contain distributed shuffling and operations that are executed within the stage.
- The stages are broken into tasks.
- Spark broadcasts the commonly reusable data t for tasks within each stage.
- The broadcasted data is cached in the serialized format. Before executing each task, it will be deserialized.
Accumulators
Another worth mentioned shared variables in Spark is Accumulator. Unlike a read-only manner, Accumulators work in a read-write manner. Generally, it is a variable that Spark uses to update data points through executors. In most cases, the data point updating actions happen for associated or commutative operations. For the scenario that we want to find out the count of the number of lines containing “ _,” using an accumulator is a good choice. After reading the file and creating an RDD, After distributing the file in multiple partitions through all available executors, creating an accumulator in the driver, we could easily get the results. The full process can also be found in the following figure that is referred from 6:
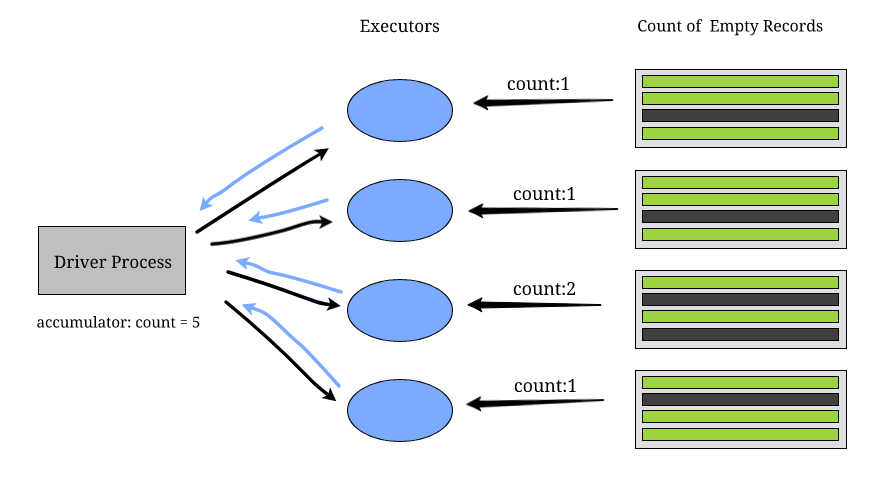
Figure: acc
Fault tolerance analysis
There are two types of faults in Spark: executer node failure and cluster manager failure. In this section, failures usually mean a node lost connection, encounter an error during computation and unexpected shutdown. Connection loss and unexpected shutdown are usually hardware failures. Encountering an error is usually caused by exhausted memory or disk space.
Executors node failure
As mentioned in the RDD introduction, RDD is immutable and the computation only creates new RDDs. If an executor node fails to compute the result, the cluster manager will allocate the same task to another executor node to re-calculate the result. Because the old RDDs are always available, the new executor node can fetch the input again and start computing.
If all executor nodes fail to process a task, the Spark application will stop and throw an exception. This situation occurs when there is a logic error in the Spark application, or the Spark application requires too many resources that the cluster cannot meet.
Cluster manager failure
The single point failure problem lies in the Spark cluster manager because only the cluster manager has the DAG and RDD context data. However, another system called Apache Mesos7 can solve this problem by providing auxiliary cluster managers8. But Apache Mesos is out of the current scope, so we treat Spark cannot tolerate any cluster manager failures.
Fault tolerance summary
Above all, Spark can tolerate most kinds of executor node failures but cannot tolerate cluster manager failure. This fault-tolerance feature is not only a safety consideration but also a price advantage. There are a lot more things to know before introducing the price advantages. These details can be found in Appendix: Hotspot instance.
Trade-offs of Spark
Spark’s overall performance is influenced mainly by unreasonable partition size and storage level. This section will introduce the main reasons for the decrease in performance and the trade-offs solution based on that problem.
RDD partition size
Partition is an important approach to increase the overall performance of spark. In Apache Spark, most of the collected data would be divided into multiple chunks. However, It would not be reasonable to have RDDs with too large partition size or too few. If the RDD partition size is too large, then it will take a longer time to complete the task scheduling9. On the other hand, small RDD partition size would not be helpful for improving performance and the extent of parallelism. Moreover, data skewing and improper resource utilization would happen when setting small RDD partition size. Therefore, there would be a trade-off when setting the parameter for RDD partition size. In general, it would be better to set the RDD partition size at the range between 100 and 10k, and make sure two times of the cores in the number are available.
RDD storage level
To improve the performance, it would be better to enable Spark to store the intermediate result so that it would be easier to import those results for computation the next time. The solution for implementing the idea mentioned above is to use the RDD storage level. RDD storage level assigns the position and the form of RDD storage. RDD would be transformed as the form of structuralize data when stored in the memory, which means RDD could be directly addressed. On the other hand, in the disk, RDD would be stored in serialized data. Although it can save more memory space, the time for serialization and deserialization between the disk and memory would be much longer, which leads to more CPU load. The following table indicates the different categories of storage level and the corresponding pros and cons.
As the above table mentioned, when storing RDD on memory, the I/O time would be shorter than storing the RDD on disk. However, CPU load would increase significantly due to serialization and deserialization. The size of the memory is smaller than that of the disk. Therefore, there would be trade-offs for developers to consider when allocating the storage for RDDs. A safe method is putting RDDs that will be used in memory and put RDDs that will never be used in the disk. If the RDD to be used is larger than memory, then put it in memory_and_disk.
Appendix: Hotspot instance
This section is auxiliary and does not focus on technical content. We put it here just as a reference.
For Spark, a fault is not a defect; on the contrary, it is a feature.
Hotspot instance
Cloud computing service providers such as Amazon usually provide virtualized instances to consumers. Virtual instance only contains a virtual core. Many virtual instances can share one physical core. This way can significantly reduce the price, make hardware resizable and achieve better resource utilization. This virtual instance is also called Elastic Computing10 .EC allows service providers can switch hardware to other users frequently. This leads to an auction of the instance - who pays higher who gets the instance. This kind of auction leads to the hotspot instance. Users can set up a price to join auctions and automatically get the instance when the price gets low. The following figure shows the hotspot instance purchase page.
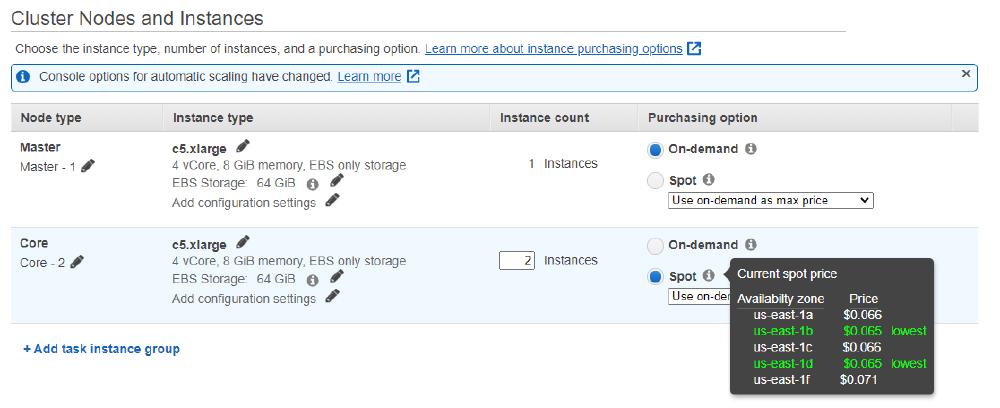
Figure: hotspot price
The on-demand price is for a normal instance, where users can always use the instance. The price for an on-demand instance is 0.192$/h, while the hotspot instance is only 0.069$/h. The risk of using hotspot instances is you will lose your instance if someone pays higher. Many companies choose an on-demand instance as Spark cluster manager and hotspot instances as Spark executors, which can even cut supercomputing costs to 10%11. We can imagine, without well-formed fault tolerance, Spark might never take the advantages of hotspot instance.
Reference
-
Spark cluster manager. https://techvidvan.com/tutorials/spark-cluster-manager-yarn-mesos-and-standalone/. ↩︎
-
DAG. https://techvidvan.com/tutorials/apache-spark-dag-directed-acyclic-graph/. ↩︎
-
Ajay Gupta. Revealing Apache Spark Shuffling Magic. https://medium.com/swlh/revealing-apache-spark-shuffling-magic-b2c304306142 ↩︎
-
DataFairTeam. Explain shared variable in Spark. https://data-flair.training/forums/topic/explain-shared-variable-in-spark/#:~:text=Shared%20variables%20are%20the%20variables,variables%20of%20the%20Spark%20job. ↩︎
-
Swantika Gupta. Shared Variables in Distributed Computing. https://blog.knoldus.com/shared-variables-in-distributed-computing/ ↩︎
-
Apache Mesos http://mesos.apache.org/ ↩︎
-
Fault tolerance in Spark https://data-flair.training/blogs/fault-tolerance-in-apache-spark ↩︎
-
Veejayendraa. Understanding Spark Partitioning. https://techmagie.wordpress.com/2015/12/19/understanding-spark-partitioning/ ↩︎
-
Amazon Elastic Computing: https://aws.amazon.com/ec2 ↩︎
-
Amazon Spot Instance: https://aws.amazon.com/ec2/spot ↩︎