Spark - Product Vision and Problem Analysis
Introduction to Spark
Spark is an open-source general-purpose computing engine for processing large-scale distributed data. It was initially developed at the University of California, Berkeley’s AMP lab in 2012 by Matei Zaharia and then donated to Apache Software Foundation, which has maintained it till now.
Since the widespread use of the Internet, the data collected by service providers become incredibly large. Google, as the search engine market leader and biggest cloud system provider, processes over 20 petabytes of data per day 1. Such an amount of data is impossible to be processed on a single computer, and solutions to this problem are called supercomputing solutions, also called big data solutions.
There are two genres in the supercomputing area. The first one is building a large centralized processing system just like a supercomputer. The other one is distributed computing, which splits data into different nodes. Usually, the first method is much more expensive because of customized hardware. The second method gets popular because even regular computers equipped with Internet connection are capable. Spark is one of the software for the second method - distributed supercomputing system.
Distributed supercomputing system
Spark is designed as a big data processing framework. Its main function is distributed computing.
The distributed system is defined as a system with components located on several networked computers, which pass messages to another component from any system for communication and coordination. The components interact with other components in order to achieve a common goal. Distributed computing also refers to solving computational problems by using distributed systems. In distributed computing, a problem is divided into many tasks, each of which is solved by one or more computers, which communicate with each other via message passing 2.
Hadoop - The ancestor of Spark
Before the existence of Spark, the most popular supercomputing tool is Hadoop. Hadoop was originally a Yahoo project which was released in 2006. It is a general-purpose form of distributed processing. The key components of Hadoop are the Hadoop Distributed File System (HDFS), whose function is storing files in a Hadoop-native format and parallelizing them across a cluster; MapReduce, which actually processes the data in parallel; and YARN, which coordinates runtimes of application. Hadoop was initially built in JAVA, but it can also be accessed through many other languages, including Python.
Unlike Hadoop, which reads and writes files to HDFS, Spark uses RAM to process data by applying a concept called RDD (Resilient Distributed Data set). Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine, which enable Spark to run 100 times faster than Hadoop.3
Spark user context
Developers who would like to write Spark applications should have a Java software development kit installed because Spark needs Java Virtual Machine (JVM). A build tool called “sbt” is also necessary if Scala language is applied. Developers can write their big data application locally and generate a Java package. This package can include Spark source code so the Java package can run on a machine without Spark installed. For big commercial data processing clusters such as AWS, developers can even submit this package via web page without caring command lines. Spark also supports streaming so that the results can be directly streamed to the market manager and end-users.
Spark stakeholder
Some famous high-tech companies release their successful distributed computing services based on spark. Amazon EMR is one of the interfaces that enable the user to run Apache spark. It includes various libraries that integrated initially in the Spark ecosystem, such as the machine learning library, graph processing library. Specifically, Amazon EMR4 provides an IDE, which is easy for data scientists to develop programs by using Python or R language. Moreover, Amazon EMR is famous for its high performance. Its EMR runtime environment could optimize the executing time of running on the Spark and shorten the computing process by 3 times, and can flexibly provide any number of computing instances based on the user’s choice.
Google dataproc is another successful distributed computing service, which was developed by the Google cloud platform 5. Google dataproc is a cloud service that could enable the user to run Apache Spark remotely on the Google cloud platform. With Google dataproc service, users do not need to create clusters manually. Instead, Google dataproc service could automatically create clusters and allocate the task to every computing node.
Besides, Apache spark has many cooperation relationships with high-tech companies or universities such as Apple, Facebook, Databricks, UC Berkeley, etc. They are still making the code contribution to the spark project.
Current roadmap
Nowadays, Spark is the most active open-source project in the bigdata field and because of the essence of machine learning popularity, Spark also developed a library for machine learning which is ML lib. ML lib is consists of various kinds of tools and pipelines, which are algorithm tools, feature tools, the pipeline used for establishing or tuning machine learning workflow, and utility tools. For algorithm tools, Spark ML lib encapsulated common learning algorithms such as classification, regression, clustering. For feature tools, Spark ML lib could complete tasks of feature selection, feature transformation, PCA, etc.
With the evolution of big data technology, Apache Spark will become more and more popular and provide a reliable high-performance computing platform for big data analysis. Recently, Microsoft released their new “.Net” bigdata analysis and development platform based on Apache Spark, which allows the developer to use any kind of programming language to develop their own big data analysis task. In the future, “.NET for Apache Spark” will make contributions to adding the interop layer to Apache Spark and performance optimization such as the improvements of the Arrow.NET library, the Micro-benchmarking framework for interop, etc.
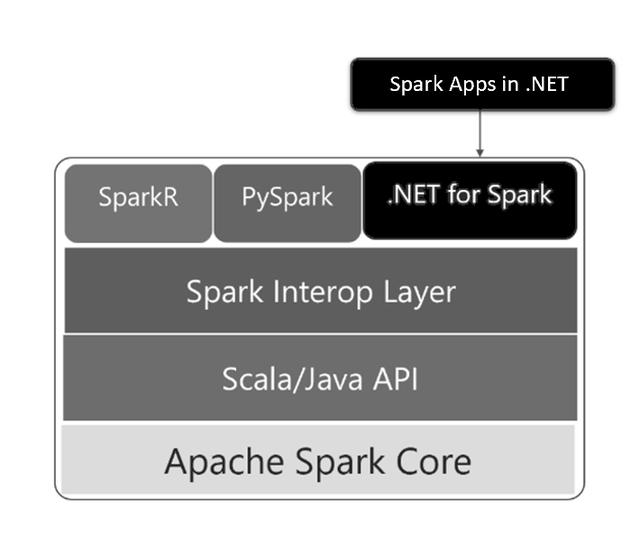
Figure: Spark layer
Spark application area
For developers, Spark is a top choice since it enables them to write applications in Java, Scala, Python, and even R. The packaged libraries, including support for SQL queries, streaming data, Graph processing, increase developers' productivity. Spark has gained high popularity in the global market since it was released.
Remarkably, Spark is giving birth to varied Spark applications because of a steady increase in adoption of it across industries. As the following figure shows, the Spark applications have been implemented successfully and used in different scenarios.

Figure: Spark Application
The most significant feature of Spark is its wonderful ability to process streaming data. Generally, processing the huge size of data tasks quickly in real-time is the first advantage of Spark. In addition, it can distribute data processing tasks through multiple computers. Specifically, the storage system is to house the data processed with Spark, and the cluster manages to orchestrate the distribution of Spark applications across the cluster. Processing real-time data and analyzing them are the essential part for most companies, and Apache Spark has outstanding ability to handle this huge workload. Several applications are using Apache Spark in the business field.
The first use case of Apache Spark Streaming ETL-Spark enables us to process and relocate the data in real-time from a certain place to another place, during which time the database format is also converted to a compatible format. Finally, it will be formed a target database 6.
Besides, trigger event detection can not be ignored in spark use cases. Responding quickly to the unusual events or behaviors in the system allows the application more stable and avoid serious problems. In most cases, the rare events are also called “trigger events”; for instance, financial organizations like banks should avoid and track fraudulent transactions. As for the medical service system, hospitals can also use the “trigger event detection” function to monitor the patient’s condition, especially for potentially dangerous health condition changes. After monitoring that situation, the system could alert the doctors, who can then take appropriate and reasonable actions quickly.
Spark is also well suited to the Machine Learning field. Machine learning library(MLlib) 7 in Spark is a key component of Spark. It can be used for different Big Data functions such as recommendation systems, sentiment analysis, predictive intelligence, search engines, among other things. ML Algorithms build the critical components of MLlib.
The quality attributes of Spark
As the leading big data computing framework, Spark must meet certain quality requirements and have some certain properties. Usually, the requirements are critical, and properties are optional. In other words, having nice properties would be better while the system still can work without it. The requirements are listed below.
-
Result correctness: unlike normal computing, there might be errors in big data computing. For example, a cluster node suddenly lost connection, and all data on that node become inaccessible. It is quite a usual case, but it will cause an error for cluster computing. Spark uses Resilient Distributed Datasets (RDD), which is fault-tolerant, to make sure correctness.
-
Performance: as we have mentioned before, big data computing is usually impossible for a single computer to perform because of low performance. So, Spark must be able to exploit the cluster performance as much as possible. Compared with Hadoop, Spark uses in-memory computing, which is already much faster.
-
Scalability: In the Spark design phase, the cluster information and the big data application are unknown for Spark designers. The two factors might vary in different situations. So, scalability must be seriously considered. Spark can dynamically add more worker nodes to scale performance.
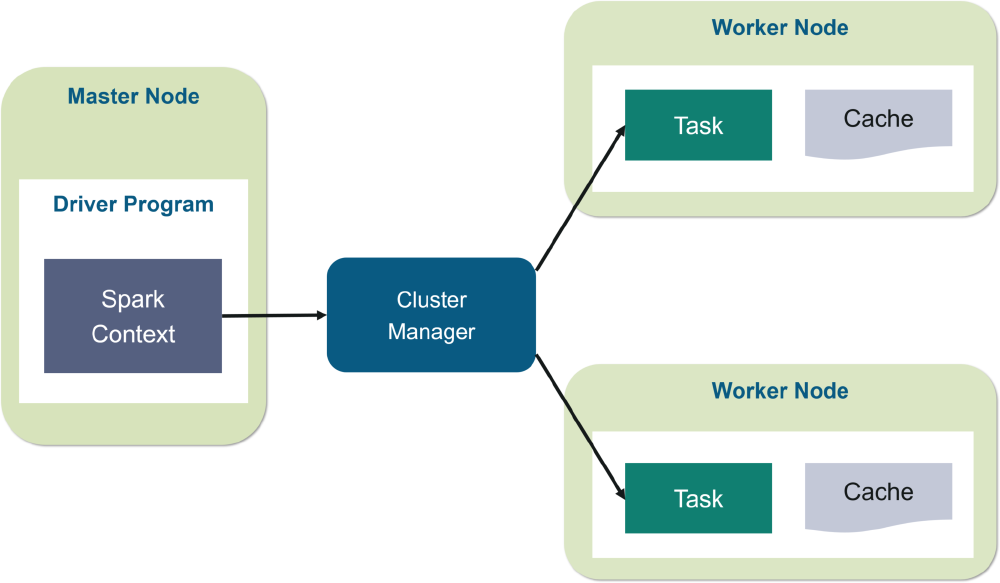
Figure: Spark Architecture
Spark also has some excellent properties, which can help develop and optimize performance. The two properties are listed below.
-
Lazy evaluation: for big data applications, developers need to wait for a long time to get the output, which can dramatically slow down the debugging and development. To solve this issue, Spark provides lazy evaluation, where the whole results are evaluated only when explicitly invoked. Otherwise, only a small set of data is processed for debugging purposes.
-
MapReduce: MapReduce is a special programming model for the distributed computing area. It can help developers easily write fast and efficient big data applications. The MapReduce model defines which operations can be parallelable (Map) and which operations cannot (Reduce). Reduce operations usually introduce many communications among a cluster, causing degraded performance. In Spark, “Reduce” operations are also called “shuffling”. Spark developers should try to avoid using “Reduce” operations to get the best performance.
Ethics consideration
Privacy and confidentiality are huge aspects of social life that we always have the dangers of misuse. For instance, in medical fields, patients' personal data like addresses, cell-phone numbers are some of the sensitive attributes 5. These data should be with-held from leaking into the public. Anonymization is a way to handle these sensitive attributes in the sense that there will be only limited data available so as to make sure the privacy is preserved. Apache Spark system uses In-memory processing of data. The way of processing the data doesn’t involve moving the data to and from the disk, thereby decreasing the risk of leaking privacy.
The most wonderful thing about Apache Spark is that it has a massive and thriving Open-source community behind it. The common drive of it is to support and improve a solution that both the enterprise and the individual developer benefit from (and believe in). The Open-source community could introduce new concepts and capabilities better, faster, and more effectively.
Though Spark performs well regarding the privacy and open-source aspects, computer energy use when using Spark is disappointing and expensive8. The result is mainly caused by the following reasons: The cluster manager is widely used in industries, which causes multiple computers to exchange data. Furthermore, the overhead could occur because the distributed computing leads to repeating computing. As a result, the whole process of computing in Spark will cost a significant amount of energies(like electricity).
Reference
-
Preetipatel. How GOOGLE handles BIG DATA. Sep, 2020. https://medium.com/@preetipatel0710/how-google-handles-big-data-1c801948ebd0 ↩︎
-
Wikipedia. Distributed computing. https://en.wikipedia.org/wiki/Distributed_computing ↩︎
-
Amir Kalron. How do Hadoop and Spark Stack Up. Jan, 2020. https://logz.io/blog/hadoop-vs-spark/ ↩︎
-
Amazon. Amazon EMR. https://aws.amazon.com/emr/?nc1=h_ls&whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc ↩︎
-
Google Cloud. Dataproc. https://cloud.google.com/dataproc ↩︎
-
Apache Spark. Spark Streaming Programming Guide. https://spark.apache.org/docs/latest/streaming-programming-guide.html ↩︎
-
Karlijn Willems. Apache Spark Tutorial: ML with PySpark. July, 2017. https://www.datacamp.com/community/tutorials/apache-spark-tutorial-machine-learning ↩︎
-
Maroulis, S., Zacheilas, N., & Kalogeraki, V. A Framework for Efficient Energy Scheduling of Spark Workloads.https://ieeexplore.ieee.org/document/7980254 ↩︎