Spark - From Vision to Architecture
Spark’s general introduction can be found in Essay1. We start for architectural analysis by a general introduction of the vision underlying Spark and its next step. In this essay, we would like to introduce a more detailed architecture of Spark.
Spark architecture
As discussed in our first essay, a summary for Spark application architecture can be illustrated by the following graph.
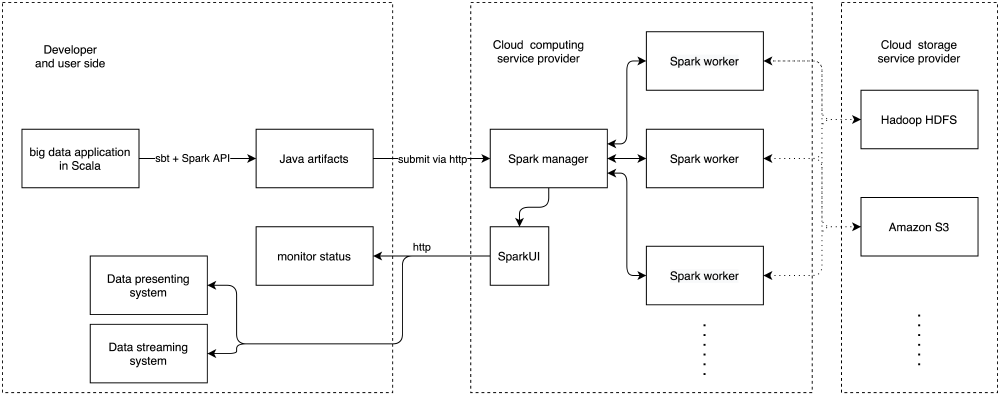
Figure: The Spark architecture
From the aspect of applications, the most obvious architecture is model-view architecture. There is no controller because Spark applications cannot be controlled at runtime. In this model-view architecture, the model consists of Spark manager and Spark workers, which are only responsible for computations. The view part is the SparkUI, which deliveries the runtime status to developers.
Despite the model-view architecture, Spark is also a layered architecture. This layered structure contains six layers. Higher layers need lower layers to work1. These layers are described below:
- Data storage layer, such as Amazon S3, Hadoop HDFS.
- Worker layer, a cluster with Spark worker deployed.
- Cluster management layer, where a single computer is deployed with Spark cluster manager.
- Directed Acyclic Graph (DAG) scheduler, analyze the Spark application and form a DAG. The DAG contains the data dependency and computing stages.
- Computing layer, computing layer is based on cluster management layer and DAG scheduler layer. It allocates computing tasks in DAG to worker nodes via cluster management. There are also two data abstraction layers in the computing layer, and they are RDD and dataset. As mentioned in the previous essay, RDD represents an immutable and partitioned collection of data, which can be distributed to different workers. The dataset means the original data, which is not partitioned and more user-friendly. Spark can automatically convert the dataset to RDD at runtime.
- User interface layer, which is also called SparkUI, is used to present current computing status via the web page and remote procedure calling (RPC).
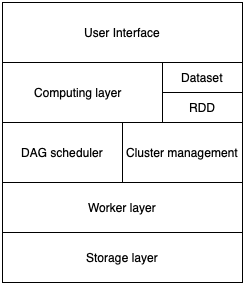
Figure: The Spark layer
Running Spark on execution environments
One of the leading execution environments for Spark is YARN. Spark’s YARN support allows scheduling Spark workloads on Hadoop alongside a variety of other data-processing frameworks. Each spark executor will run on a YARN container. Running spark on YARN, while MapReduce schedules a container and assigns a Java virtual machine for each task, spark hosts multiple tasks within the same container2.
“Application Master” is the key concept in YARN containers, which is included in every application instance in YARN. “Resource Manager” for an application instance is to grant resources and allocate resources, during which time it will tell NodeManagers to start containers on its behalf.
There are two types of mode for running on YARN in Spark, one is “YARN-cluster,” and another is “YARN-client,” Production jobs are mainly done in YARN-cluster, whereas YARN-client implements interactive and debugging work. As for the YARN-cluster mode, the drivers will execute on the Application Manager, which means that the same process needs to drive the application and request resources from YARN.
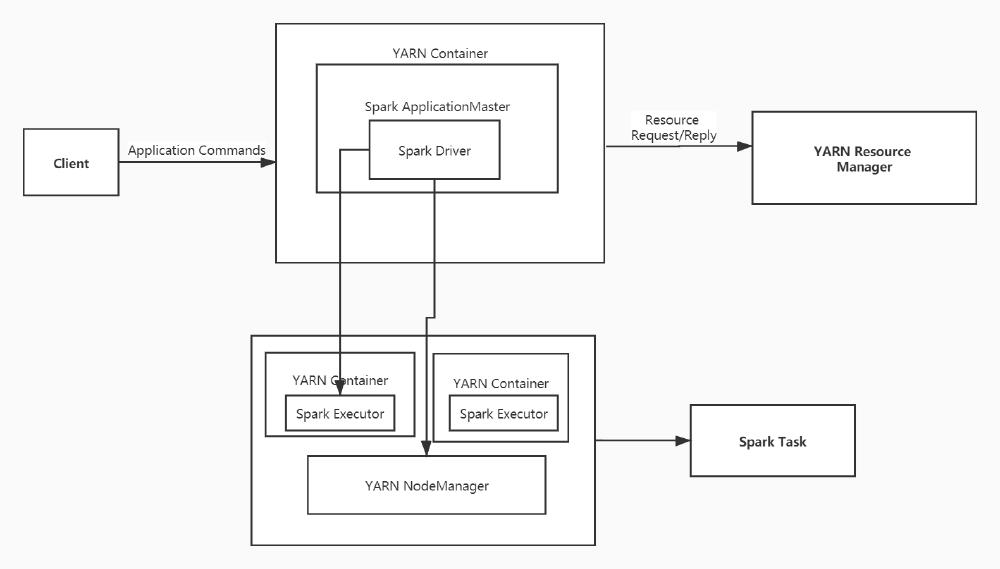
Figure: Yarn-Cluster Mode
Both Spark Driver and Spark Executor are under the supervision of YARN when a client submits a spark application to YARN in YARN cluster mode. However, only the spark executor is under the supervision of YARN in YARN client mode. And the YARN application master just requests resources for the spark executor.
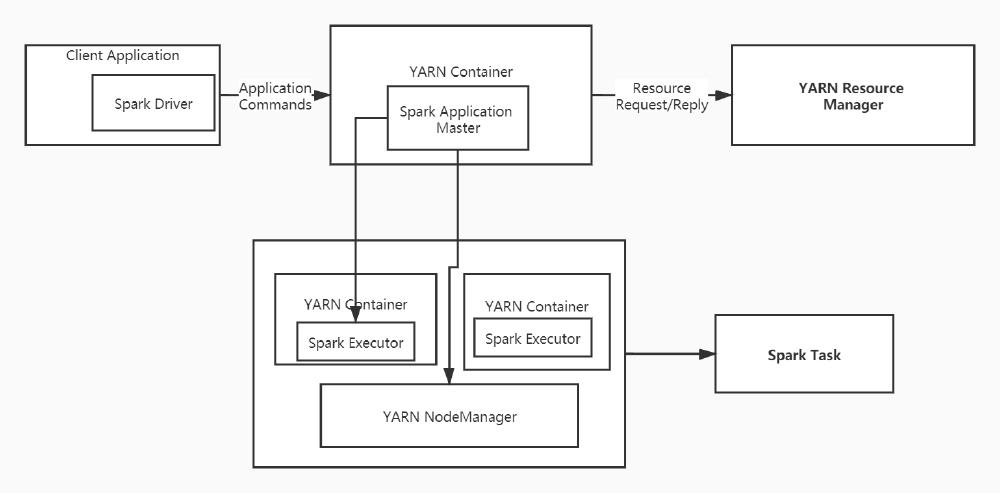
Figure: YARN-Client Mode
Besides, all spark components like Driver, Master, and Executor processes run in Java virtual machines. A JVM is a cross-platform runtime engine that can execute the instructions compiled into Java bytecode3.
Spark Run time architecture
For a better understanding of the run time architecture of Spark, two important concepts should be illustrated: RDD and DAG.
Resilient Distributed Dataset (RDD) is a collection of elements that can be operated on multiple devices parallelly. Every dataset in an RDD can be divided into logical portions, which are then executed on different nodes of a cluster.
Directed Acyclic Graph(DAG) is a sequence of computations performed on data where each node is an RDD partition, and the edge is a transformation on top of data4. The DAB helps eliminate the Hadoop MapReduce execution model and provides performance enhancements over Hadoop.
Generally, a master/slave architecture with a cluster manager is applied in Apache Spark. When a client submits a spark user application code, the initial step is to build operator DAG, in which time there are two types of transformation processes applied on RDD: Narrow Transformations and Wide Transformations. Once the DAG is built, the Spark stakeholder creates a physical execution plan and splits the operators into stages of tasks. A stage takes up tasks based on partitions of the input data. Subsequently, all of those stages are assigned to the Task Scheduler that launches tasks by cluster managers like Yarn5. In the end, the worker executes the tasks on the Slave.
Visualization of Spark Streaming statistics is also an essential part. The DAG visualization allows the user to click into a stage and expand on the details within the stage6. For instance, Zoomdata leverages spark data stream processing as a processing layer with the Zoomdata server. When users submit requests for data, Zoomedata retrieves the data from the spark streaming result set cache. Therefore, Zoomdata also could perform some kind of interaction7.
Spark components view and connection view
Spark consists of the following modules: Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX.
Spark Core enables Spark to achieve the basic and core functions, including initializing SparkContext, dispatching mode, setting storage framework, and carrying out and submitting operations. Also, the computing engine is also in Spark Core8.
Spark SQL provides Spark with the ability of SQL processing. In the process of Spark SQL, SQL is transformed to a grammar tree by SQL Parser. After that, Rule Executor applies a series of rules to the tree to work out physical operation plans and then implement them by an actuator. The actuator consists of a grammar analyzer and optimizer.
Similar to Apache Storm, Spark Streaming is also used for streaming processing. It can support a variety of data input sources, including Kafka, Twitter, and Flume. The input data is received through a receiver. Dstream is the abstract of all data flow in Spark Streaming. It is constructed by a series of sequential RDDs.
MLlib enables Spark to process machine learning problems. It is a machine-learning frame offered by Spark. MLlib can process many different algorithms, such as classification, regression, Bayesian approach, clustering, and feature capturing.
Spark can do graph processing through GraphX. As a distributed graph computing frame, GraphX obeys the Pregel model of Bulk Synchronous Parallel (BSP). Currently, GraphX has packaged a variety of algorithms, including the shortest path, the connection of components, etc.
Spark UI is a high-efficient simple and event-driven monitoring component.
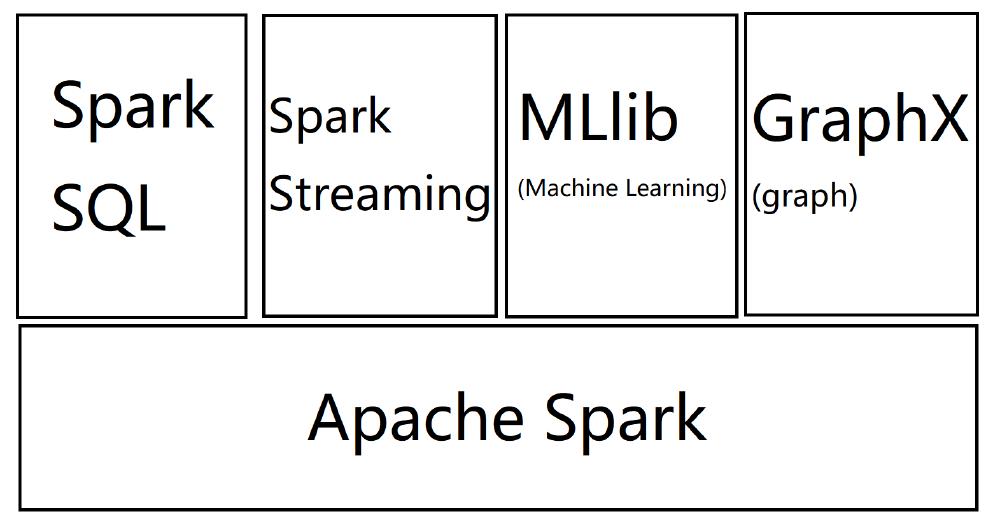
Figure: The structure of Spark
As The picture above shows, Spark SQL, Spark Streaming, MLlib, and GraphX are all based on Spark core. In the real process, users write driver applications with API offered by Spark Context. In this stage, SQL Context, Hive Context, and Streaming Context pack Spark Context and provide related API. After that, the Hadoop configuration of these applications will be broadcasted by Block Manager and Broadcast Manager. Then, the tasks are transferred into RDD and then DAG by DAG Scheduler. Finally, the tasks are submitted to Cluster Manager by Task Scheduler.
Development view
SparkContext overview
SparkContext is a module in the driver program, which will connect to a cluster manager that allocates the different tasks to executors in the worker nodes. Also, SparkContext contains several contents such as network communication, distributed deployment, message communication, cache, files services, Web services, etc. Therefore, the developer could simply use the API that SparkContext provides to implement their works. SparkContext has different parameters for the developer to change to adapt to different working situations, which is charged by the SparkConf control panel, which is the input variable of SparkContext configurator.
SparkContext is the most important module that will drive the running of all Spark applications. It has several steps for initialization. The overall workflow of the initialization has been listed as below:
| Step | Action |
|---|---|
| 1 | Create executing environment of Spark |
| 2 | Create metaCleaner for cleaning RDD |
| 3 | Create and initialize Spark UI |
| 4 | Hadoop related configuration and the setting of Executor environment variables |
| 5 | Create TaskScheduler |
| 6 | Create and Initiate DAGScheduler |
| 7 | Initiate BlockManager |
| 8 | Initiate MetricsSystem |
| 9 | Create and Initiate ExecutorAllocationManager |
| 10 | Create and Initiate ContextCleaner |
| 11 | Update Spark environment |
| 12 | Create DAGSchedulerSource and BlockManagerSouce |
| 13 | Activation of SparkContext Tag |
Spark Shuffle
Shuffle is the module that enables the execution of the Map and Reduce process. With the Shuffle module, the Map process could allocation the tasks into different computing nodes, and the Reduce process would also be able to rearrange and Integrate the data outputted by computing nodes. Therefore, it is an essential bridge between Map and Reduces process. The ShuffleManager module controls the shuffle’s primary function, often running on the executor. If the user wants to call the ShuffleManager module in the driver, they have to run this in the local mode.
BlockManager
BlockManager module is often used for managing the block data in both driver and executor. It will provide the interface for uploading and fetching blocks both locally and remotely using various stores, i.e. memory, disk and off-heap9.
DAGScheduler
DAGScheduler is used for preparation works before submitting jobs. The data structure of DAGScheduler mainly establishes the relationship between jobs and stages. DAGScheduler has several functions. The first function is computing DAG. In order to obtain the stage and corresponding task, DAGScheduler would run the DAG and submit the tasks and stages to TaskScheduler. The second function of DAGScheduler is the preferred location. DAGScheduler could obtain the preferred location according to the cache information and preferred location of RDD. The third function of DAGScheduler is fault-tolerant. DAGScheduler can resubmit the corresponding tasks and stages if a failure occurred when reducer reads the output generated after shuffle operation.
Memorystore
MemoryStore could save the non-serializable Java object data structure or serializable byte buffer into RAM. MemoryStore has higher priority than DiskStore. If the block satisfies RAM storage and Disk storage, it will save the block first into RAM storage.
Diskstore
The main function of DiskStore is saving the block data into the disk. Data cannot be stored by MemoryStore will be stored in DiskStore.
Qualities achieved by the architecture
- Result correctness: In Spark, computations are presented by a DAG graph. If one of the stages fails, the computation can restart from the last successful stage. Data on each stage is stored by RDD, which is also fault-tolerance. So overall, the result correctness can be guaranteed.
- Scalability: Spark has good scalability due to two reasons. First, the hardware resources can be dynamically scaled by adding/removing Spark workers. Spark manager can detect the new workers and automatically allocate new tasks to them. Second, the abstraction of Dataset and RDD hides the scalability problem from Spark users. Users only need to interact with the dataset, which is similar to the dataset concept in the database. Spark can automatically split the dataset into many RDDs and dynamically allocates them to different workers.
- Performance: The performance of Spark is related to the number of Spark workers: more workers, better performance. For more details, please refer to the first essay.
Spark API design principle
From the aspects of API functionality, Spark provides a complete collection of interfaces to operate a dataset via SQL-like APIs and inherits the distributed computing APIs, such as MapReduce, from Hadoop10. These APIs are carefully designed and follow several important principles, which are listed below.
-
Minimal but complete: Spark API is designed to be as small as possible. Spark only provides less than 20 functions for the dataset, but these functions contain all operations on it. Minimal APIs also help users to memorize, so they can also speed up development.
-
Abstraction: Spark API hides all details, such as cluster management, data serialization, and data communication, from users. Thus they can focus on their product’s logic.
-
Lazy evaluation: all Spark APIs are designed to be lazy evaluation, which means the data operations will not be executed immediately after the API is called. The result will only be evaluated when explicitly called or shuffled. This property can greatly save time in debugging and running.
-
Intuitive and readable: Spark API is similar to SQL API and Hadoop MapReduce API. Users with properly related backgrounds can quickly understand the use and the meaning of Spark API.
-
Customizable: Users can customize the behavior of the Spark API. A good example is that users can customize the serialization method in Spark, which is important if they want to store complex data structure in Spark dataset. In addition, a faster serialization method can also improve performance.
Reference
-
Neha Vaidya. Apache Spark Architecture - Spark Cluster Architecture Explained. https://www.edureka.co/blog/spark-architecture/#:~:text=Scala%20and%20Python.-,Spark%20Architecture%20Overview,Resilient%20Distributed%20Dataset%20(RDD) ↩︎
-
Datasax Documentation. Spark JVMs and memory management. https://docs.datastax.com/en/dse/5.1/dse-dev/datastax_enterprise/spark/sparkJVMs.html ↩︎
-
Jeffrey Aven. Tutorial: Spark application architecture and clusters. https://www.infoworld.com/article/3307106/tutorial-spark-application-architecture-and-clusters.html ↩︎
-
Thessaloniki. Distributed Link Prediction in Large Scale Graphs using Apache Spark. [https://www.slideshare.net/tasostheodosioy/distributed-link-prediction-in-large-scale-graphs-using-apache-spark-thesis](https://en.wikipedia.org/wiki/Distributed_computing](https://en.wikipedia.org/wiki/Distributed_computing) ↩︎
-
Petar Zečević and Marko Bonaći. Running Spark: an overview of Spark’s runtime architecture. https://freecontent.manning.com/running-spark-an-overview-of-sparks-runtime-architecture/ ↩︎
-
Andrew Or. Understanding your Apache Spark Application Through Visualization. https://databricks.com/blog/2015/06/22/understanding-your-spark-application-through-visualization.html ↩︎
-
Zoomdata. Zoomdata Introduces Zoomdata Fusion for Big Data Blending. https://www.zoomdata.com/press-release/zoomdata-fusion/ ↩︎
-
Spark. Apache Spark - Core Programming.https://www.tutorialspoint.com/apache_spark/apache_spark_core_programming.htm#:~:text=Spark%20Core%20is%20the%20base,of%20data%20partitioned%20across%20machines. ↩︎
-
Mallikarjuna G. Block Manager — Key-Value Store for Blocks. https://mallikarjuna_g.gitbooks.io/spark/content/spark-blockmanager.html ↩︎
-
Spark. Spark API Documentation.https://spark.apache.org/docs/2.4.0/api.html ↩︎