ThingsBoard - Distribution Analysis
After providing and gaining much deeper insight into ThingsBoard’s IoT platform and architecture1, we now present a deeper analysis of ThingsBoard’s most exciting aspect: the distribution architecture.
Distributed Components
To recap, ThingsBoard consists of six main distributed components which are, (IoT) devices, ThingsBoard Transport microservices, Thingsboard Core microservices, ThingsBoard Rule Engine microservices, ThingsBoard Web UI and Third-Party systems.
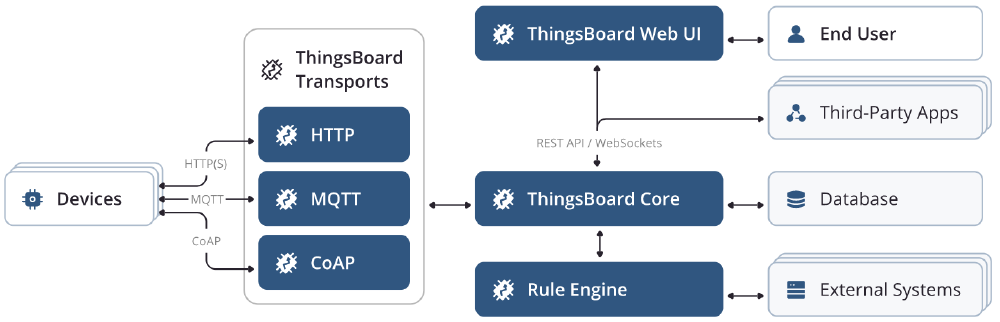
Figure: ThingsBoard Architecture
Devices represent the range of various types of IoT devices which can be connected to ThingsBoard such as, thermostats, sensors, gps trackers, etc.
ThingsBoard Transport microservices is the collection of transport servers which responsible for transporting the data from the IoT device to the ThingsBoard Core. This includes the HTTP 2, MQTT 3 and CoAP 4 servers.
ThingsBoard Core microservices consists of core node(s) responsible for handling REST API calls, websocket subscriptions, process messages from devices via Rule Engine and monitor connectivity state of the devices.
ThingsBoard Rule Engine microservices include configurable chain of rules that are used to process incoming messages from the devices. They also include JavaScript Executor Microservices which allows users to add custom JavaScript functions to process incoming data.
ThingsBoard Web UI allows users to interact with the system by letting them visualize the devices data and configure the rule engine.
Things-Party systems entails databases (Cassandra, PostgreSQL), queuing software (Apache Kafka), data structure storage for caching (Redis) and distribution coordination servers (ZooKeeper).5 A more in-depth analysis of these components can be found in one of our previous essays titled ‘ThingsBoard - Architecture’.6
Inter-component Communication
In this section, we will look at how the components communicate with each other and what information is exchanged between them.
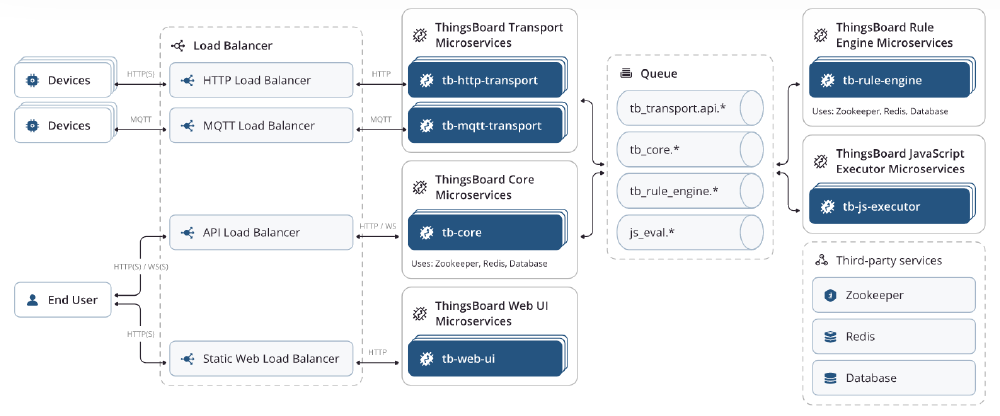
Figure: ThingsBoard microservice Architecture
Communication between Devices and ThingsBoard Transport Microservices
ThingsBoard Transport Microservices consist of HTTP(S), MQTT and CoAP server nodes. There can be multiple instances of each server if the number of devices is high. In that case, a load balancer (HA Proxy7) is used to distribute the server requests. The devices can use standard client libraries for the protocol they use to communicate with their respective servers. For authentication, access tokens are used. The access tokens are automatically generated when a new device is registered on the WEB UI or through automated device provisioning.8 2 3 4
By default, ThingsBoard expects the data from devices to be in JSON format. However, it is also possible to change this format to Protocol Buffer by changing the device payload parameter to Protobuf9. The code to do this is shown below, in line 6. Protocol Buffer is a language and platform-neutral way of serializing structured data. By serializing the data, the size of transmitted data is minimized.10
case DeviceTransportType.MQTT:
const mqttTransportConfiguration: MqttDeviceProfileTransportConfiguration = {
deviceTelemetryTopic: 'v1/devices/me/telemetry',
deviceAttributesTopic: 'v1/devices/me/attributes',
// Configure Transport Payload type
transportPayloadTypeConfiguration: {transportPayloadType: TransportPayloadType.PROTOBUF}
};
The information that is exchanged between the de devices and Transport microservices is mainly telemetry data from the devices (like temperature, GPS position, energy consumption), and device attribute updates and connectivity status data. Below is an example of how an MQTT device publishes its telemetry data to its server using a message string and a JSON file.
# Publish telemetry data
myMQTT_device -d -q 1 -h "thingsboard.cloud" -t "v1/devices/me/telemetry" -u "$ACCESS_TOKEN" -m "{"temperature":42}"
# Publish telemetry data from file
myMQTT_device -d -q 1 -h "thingsboard.cloud" -t "v1/devices/me/telemetry" -u "$ACCESS_TOKEN" -f "telemetry-data-as-object.json"
Communication between ThingsBoard WEB UI and ThingsBoard Core Microservices
The comminication between the WEB UI and ThingsBoard Core Microservices is done using WebSockets API which uses the WebSocket protocol that opens a bi-directional interactive communication session. The WebSockets API11 gives access to all the functionalities of the REST API and also allows to directly open a connection to Telemetry data service and subscribe to data updates.
Queues : Communication between the rest of the components
Aside from the devices, the rest of the distributed components use queues to communicate with each other. Apache Kafka is used by default to implement queues. Kafka is a distributed, reliable and scalable persistent message queue and streaming platform.12 However, other queue imeplementation including RabbitMQ, AWS SQS, Azure Service Bus, Google Pub/Sub and more are also supported. The messages in the queue are serialized using Protocol Buffers. So, if the devices use JSON format for messages, they are serialized before arriving at the queue and vice-versa.
The queues are implemented with an abstraction layer which contains topics and partitions. Topics allow components to be isolated from each other and run asynchronously, which enables distribution of a system. Message producers push their message to a certain topic and the consumers of the topic pull the messages. Partitions of a topic allow for a higher message processing throughput. This is because, partitioning divides/duplicates a topic into several replicas so that multiple consumers can pull a message from multiple topic partitions at the same time. Each partition of a topic can also be placed on a different machine, which also contributes to better distributability of the system. Below is a figure13 to illustrate how the partitions of a topic are used.
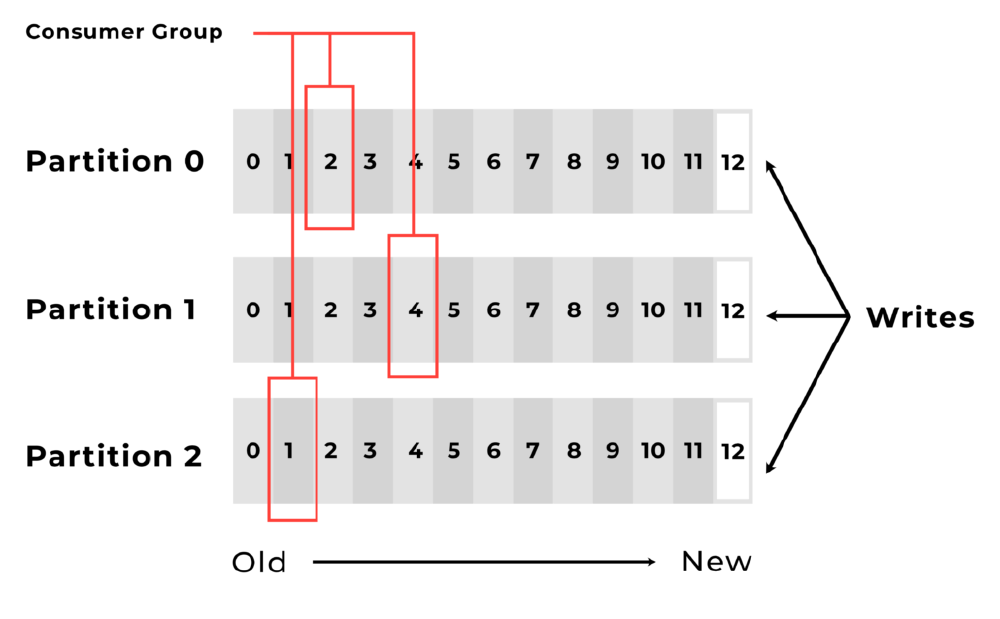
Figure: Schematic overview of paritions
Next, we will discuss the topics that are used for communication between the components. A list of the used topics is given below. The topics are catagorized according to their corresponding service type.
- transport :
- tb_transport.api.requests
- tb_transport.api.responses
- tb_transport.notifications
- core :
- tb_core
- tb_usage_stats
- rule engine :
- tb_rule_engine.main
- tb_rule_engine.hp
- tb_rule_engine.sq
The topic ‘tb_transport.api.requests’ is used to execute transport server API call in order to check device credentials or register new devices. The responses to the API calls are published on ‘tb_transport.api.responses’. These topics are used to exchange information between Core microservices and Devices via Transport microservices. ‘tb_transport.notifications’ is used for high priority notifications coming from devices that require minimum latency and processing time.
The topic ‘tb_core’ is used to publish messages from Rule Engine microservices and devices via. Transport microservices to Core microservices. The published messages include session lifecycle events, attributes, RPC subscriptions, etc. When a cluster of ThingsBoard Core nodes are used, they also use this topic to communicate with each other.14. ‘tb_usage_stats’ is used to report the usage statistics of the Core microservices.
The topic ‘tb_rule_engine.main’ is used to publish messages from Core microservices and Transport microservices to the Rule engine. The messages include device data to be processed by the Rule Engine Microservices. ‘tb_rule_engine.hp’is used for high priority messages. ‘tb_rule_engine.sq’ is used for messages that have to be processed in a sequence set by the originator. A message can thus only be processed if there is an acknowledgment of the preceding message in the sequence being finished.
Fault Tolerence
ThingsBoard claims to be fault-tolerant as it has “no single-point-of-failure, every node in the cluster is identical”. The following section will investigate this claim and how the different components of ThingsBoard handle faults.
The message queues form a critical part of the system. For the reliability of ThingsBoard, it is very important that the message queues are tolerant to faults, losses and crashes. The default message queue used by ThingsBoard is Apache Kafka. Fault-tolerance is natively embedded in Kafka. This fault-tolerance is achieved by highly available and replicated partitions, a schematic overview can be found under this section. If a task runs on a machine which fails, this task is automatically restarted by the Kafka streams in one of the remaining running instances of the application. In order to make the partitions also robust to failure, each partition maintains a replicated changelog Kafka topic in which any state updates are tracked. Even if a task crashes on a machine and is restarted on another machine, the Kafka Streams guarantees to restore their associated states by replaying the changelog topics prior the failure. Via this way no data is lost and it makes the failure handling completely transparant to the end user. 15 16 17
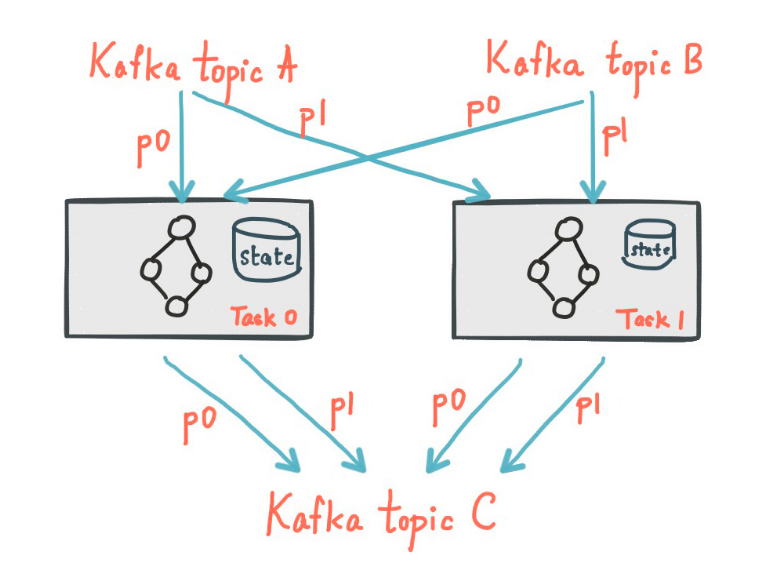
Figure: Schematic overview Kafka partitions
The ThingsBoard core microservice is one of the most important component of the system and requires to be resistent against errors. The core is using the Actor System 18 and which is implemented over different nodes. The partitions of the incoming messages are handled by the responsible nodes. 19 In this case are the actors the tenants and devices. The actors divide their tasks into smaller subtasks by starting child actors. By splitting the tasks into small pieces, failures only have a very small effect and do not propagate in the hierachy allowing for a safe and fault proof behaviour.
The default database used by ThingsBoard is PostgreSQL. The nature of this database falls in line with rest of ThingsBoard as also this system is designed to be fault-tolerant. It makes use of multiple servers or nodes which make up a cluster. The node that allows a user to make changes is known as the primary node and can be seen as the source of changes. The database server which allows read-only access is called the stand-by node. The key aspect of replication is transferring the data captured by the primary node to the different nodes. In PostgreSQL, the primary node sends the data to the WAL (Write-Ahead Logging)20, which can be seen as a log file. Then, the data is fetched from the WAL and stored in the stand-by nodes. To improve efficiency and availablity, different modes of stand-by nodes are used. An overview can be found under this section.
| WAL Level | Suitable for |
|---|---|
| minimal | crash recovery |
| replica | physical replication/ file-based archiving |
| logical | logical replication |
In case a primary node crashes, one of the standby nodes is promoted to momentarily take its place. Depending on the duration and severity of the crash, a Switchover (temporarily switch the primary node) or a Failover (permanent promotion) is possible.21
Trade-offs of Distributed system
In order to discuss the trade-offs of ThingsBoard being a distributed system, we will use the CAP Theorem. CAP stands for Consistency, Availablility and Partition tolerance, which are the three core desired properties of a distributed system.22 The CAP theorem states that only two of these three properties can be achieved simultaneously, so there must be a trade-off. Below is the definition of these properties.
- (Strong) Consistency : Each read contains the most recent write or gives an error
- Availibility : Each read request gets a non-error response, which does not have to contain the most recent write
- (Network) Partition tolerence : The system can continue functioning even if some messages are dropped or delayed in the network
We always want our distributed system to be partition tolerant. Depending on how Partition tolerence is implemented, only either Strong Consistency or Availability can be achieved. In the case that the system just cancels a process and returns an error due to a message drop or delay, then only Consistency is achieved. If the system continues to run the process with older available data, then the system is Available but not Consistent. The main communication method used by the core components of ThingsBoard is Kafka queues with topic partitions, as discussed in previous section ‘Queues : Communication between the rest of the components’. Kafka guarantees that published messages to a topic are kept in a log in the order they are sent, and only after all partitions recieve the message and put it in their log, the published message is considered ‘commited’.23 So, we can say the ThingsBoard favors Availability over Strong Consistency as messages can be delayed when waiting for all topic partitions to be synced. As for consistency, Sequential consistency is still achieved as the order of the messages in all partitions are still preserved.
Conclusion
Since this is our final written report on ThingsBoard, we would like to take the opportunity to conclude all of our findings. ThingsBoard can still make some improvements with regard to their open source guidelines and (automated) quality control. However, overall, ThingsBoard has an advanced, well-developed software architecture that results in a scalable, robust and customizable application. ThingsBoard’s architects show craftmanship with respect to the system’s distributed backend system especially and we trust that their goals for the future, such as the move towards edge gateways, will be handled well.
References
-
https://2021.desosa.nl/projects/thingsboard/posts/2.-architecture/ ↩︎
-
https://thingsboard.io/docs/user-guide/device-provisioning/ ↩︎
-
https://github.com/protocolbuffers/protobuf#protocol-buffers---googles-data-interchange-format ↩︎
-
https://thingsboard.io/docs/user-guide/device-profiles/#transport-configuration ↩︎
-
https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API ↩︎
-
https://thingsboard.io/docs/reference/msa/#transport-microservices ↩︎
-
https://scalac.io/blog/what-is-apache-kafka-and-what-are-kafka-use-cases/ ↩︎
-
https://thingsboard.io/docs/reference/msa/#thingsboard-node ↩︎
-
https://kafka.apache.org/0102/documentation/streams/architecture#:~:text=Kafka%20Streams%20builds%20on%20fault,needs%20to%20re%2Dprocess%20it. ↩︎
-
https://thingsboard.io/docs/reference/#message-queues-are-awesome ↩︎
-
https://jack-vanlightly.com/blog/2018/8/31/rabbitmq-vs-kafka-part-5-fault-tolerance-and-high-availability-with-rabbitmq ↩︎
-
https://doc.akka.io/docs/akka/current/general/actor-systems.html ↩︎
-
https://thingsboard.io/docs/reference/#:~:text=ThingsBoard%20Core%20is%20responsible%20for%20handling%20REST%20API%20calls%20and%20WebSocket%20subscriptions.&text=ThingsBoard%20Core%20uses%20Actor%20System,partitions%20of%20the%20incoming%20messages. ↩︎
-
https://www.2ndquadrant.com/en/blog/evolution-of-fault-tolerance-in-postgresql-replication-phase/ ↩︎
-
https://sookocheff.com/post/kafka/kafka-in-a-nutshell/#:~:consistency%20and%20Availability ↩︎