PaddleOCR is an ultra-lightweight OCR tool for extracting texts from pictures, which can be further integrated with other software systems or embedded devices. This week’s blog will explore the software quality and integration process of this effective OCR tool mainly based on its Github and the paper1 published by PaddleOCR developer team.
- Overall Software Testing Processes
- Key Elements in Continuous Integration
- Hotspot!Which Part is Mostly Updated?
- Pull Request Analysis
- Technical Debt: Code Shows the Fact
- Reference
Overall Software Testing Processes
Software testing has a prescribed order in which things should be done to guarantee the user experience of software, serving as the ‘guardian’ of software quality. The figure below briefly shows the steps taken to fully test PaddleOCR in preparation for releasing it. For PaddleOCR, its quality process mainly focuses on integration, system, and acceptance testing.
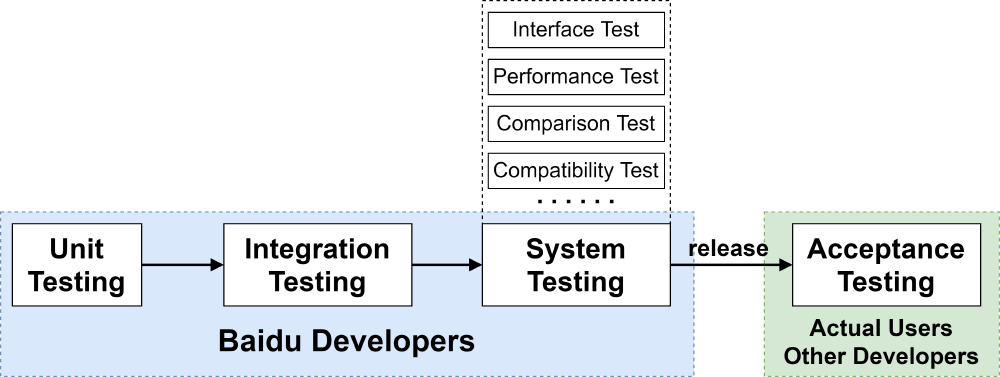
Figure: PaddleOCR Test Process
Integration Testing
Integration testing involves testing of each code module, playing a crucial role in the testing influence of each module on the entire program model. Baidu developers emphasize the ablation experiments of each module’s algorithms in the paper “PP-OCR: A Practical Ultra Lightweight OCR System”, which reflects the rigorous integration testing they have conducted. By the utilization and analysis of various methods in one module, developers select and design their algorithms to not only enhance the model ability but lighten PaddleOCR as well.
System Testing
System testing executed by professional testing agents covers enormous fields, includes at least 50 types of specific testing methods. PaddleOCR mainly concerns with following several system testing methods.
Through interface testing, development teams can evaluate whether systems or components pass data and control correctly to one another.
Performance Testing conducted in PaddleOCR concentrates on three aspects - accuracy (F-score), model size and inference time according to paper1. Different from other software systems, in PaddleOCR, self-developers could also participate in performance testing by training the model offered by PaddleOCR and then contribute to this project.
Compatibility testing aims to check whether the software system could run on different hardware, operating systems, mobile devices and applications, which is critical for deploying PaddleOCR and helping developers to properly choose training environments.
To highlight the light-weight and effectiveness of PaddleOCR, Baidu presents its comparison testing results in their paper1. This paper compares the F-score, model size and inference time of the ultra-lightweight and the large-scale model. It proves that the former one makes a great improvement in size and speed at the expense of less than 5% F-score.
Acceptance Testing
Acceptance testing is performed by actual users. For PaddleOCR, other developers in deep learning or other fields can implement this testing as well. The benefit of an open-source project is that numerous talents could polish PaddleOCR by pulling requests on Github.
Key Elements in Continuous Integration Processes
Continuous integration(CI) is the practice of automating the integration of code changes from multiple contributors into a single software project. Continuous integration can benefit the developers a lot ranging from the easily detected and tracked integration bugs to the constant availability of the latest build for testing, demo, or release purposes.
Based on the CI and roadmap of PaddleOCR, this section analyzes important updates of the PaddleOCR system, which mainly focused on the model, the deployment and the tools as shown in the figure below.
From the perspective of the PaddleOCR model, the first big step starting from the open-source of 8.6MB1 lightweight Chinese OCR model was to bring a general use model, followed by recognizing the character “space”. To attract more subscribers, PaddleOCR updated the multilingual recognition model not only for English but also for German, French, Japanese and Korean. More language recognition models are under development. To highlight the special feature of ultra-weight, PaddleOCR designed the ultra-lightweight compressed ppocr_mobile_slim series models, the overall model size is just 3.5MB1, suitable for mobile deployment.
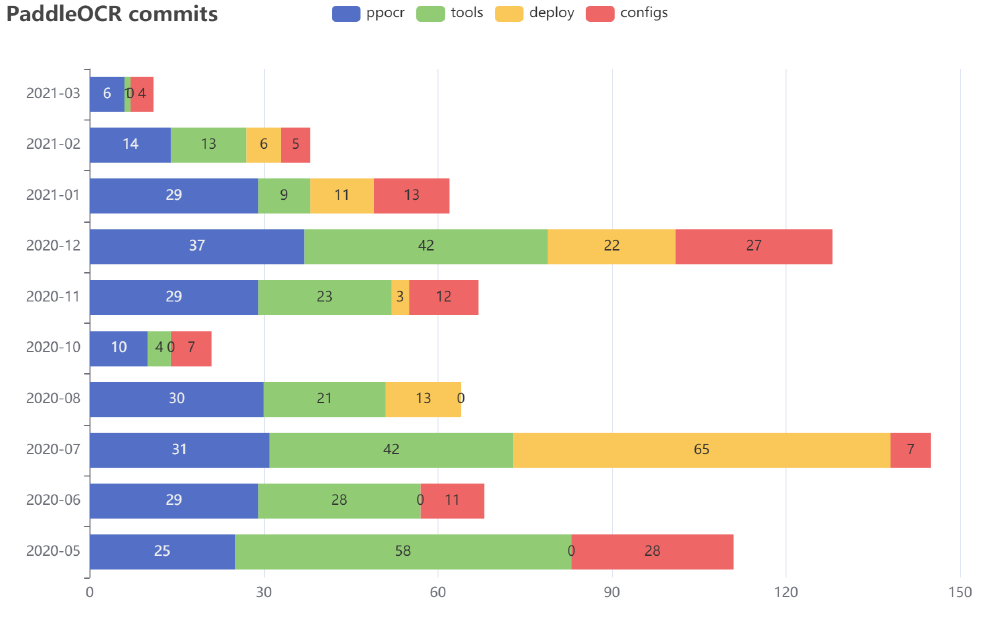
Figure: Commits Statistics since May 2020
As for the deployment, PaddleOCR firstly supported the model prediction and training on Windows OS. Then it improved the deployment ability by adding the C++ inference, serving deployment, as well as the benchmarks of the ultra-lightweight OCR model, are provided.
What’s more, PaddleOCR has updated tools in the integration process. Tools in the code structure of PaddleOCR are made up of the evaluation function, the export of the inference model, and inference based on the inference engine. Also, the program (starting the overall process) and training (starting training) are included.
Hotspot! Which Part is Mostly Updated?
Since we mentioned some of the major commits of the whole project in the last paragraph, this part further analyzes the specific changes of the commit in the ppocr model and deployment. As we address in essay2, PaddleOCR has a modular architecture. We analyze the number of commits in the ppocr(main model) and deployment since PaddleOCR was published on Github in May 2020, whose result has been visualized in the figure below.
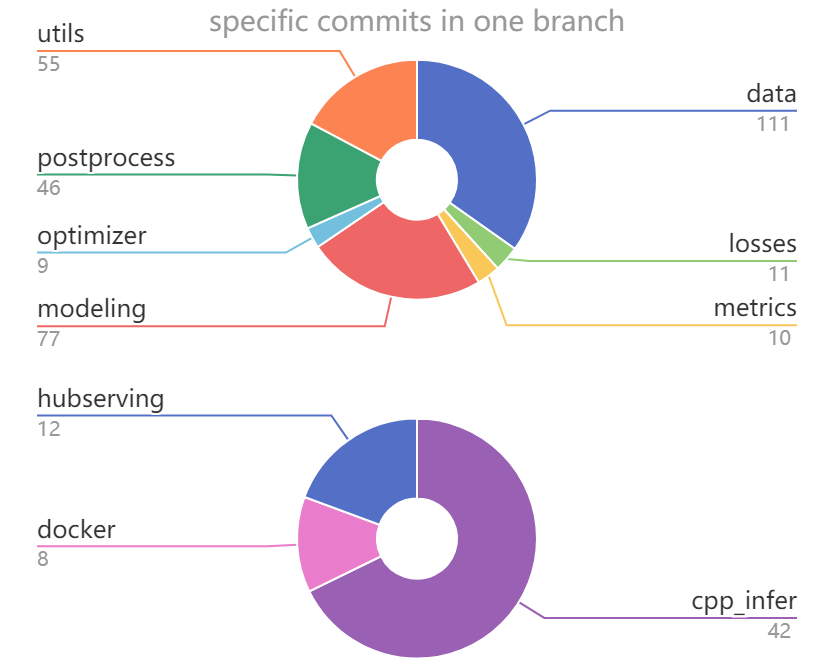
Figure: Specific Commits Changes in ppocr and deploy Branch
We can find that the data, modeling, and post-processing procedure account for the largest part. Because these important components have the most direct and significant impact on recognition accuracy - one of the most important evaluation metric in the field of OCR system.
Following past updates in PaddleOCR, we deduce that, in the future, the most intuitive goal still is the design of versatility and diversity. More specifically, PaddleOCR is supposed to be able to be used in a more general way and equipped with more diverse multilingual recognition models.
Pull Request Analysis
This section will analyze some PRs from the project following the timeline. We will scrutinize what roles they act and how they contribute to the whole project. We mainly divide the roles into four categories, including functional PRs, optimizing PRs, debugging PRs and documenting PRs.
- Pull Request #210 (Functionality) It adds a new function that can visualize the results and give different colours to the corresponding identified texts. Therefore, users can get the knowledge of which texts are detected and recognized along with their relative positions. It mainly contributes to the “Design From the Client’s Perspective”. The modification is tiny, but the achievement is significant.

Figure: Self-test: Colourful Prediction Demo
- Pull Request #241 (Optimization) It optimizes the stability of the code. For instance, it substitutes the relative path address to the absolute one. Moreover, as shown in the code below, when calculating the width and height of an image, it previously merely considers one situation but it now considers them more comprehensively.
# img_crop_width = int(np.linalg.norm(points[0] - points[1]))
# img_crop_height = int(np.linalg.norm(points[0] - points[3]))
img_crop_width = int(max(np.linalg.norm(points[0] - points[1]),
np.linalg.norm(points[2] - points[3])))
img_crop_height = int(max(np.linalg.norm(points[0] - points[3]),
np.linalg.norm(points[1] - points[2])))
-
Pull Request #277 (Debug) The original code wrongly uses
math.ceilto set the width of an image, and it should use the floor value. Althoughmath.ceilmay not adversely impact the current final results, it indeed generates an array larger than the usage. -
Pull Request #288 (Functionality and Optimization) This PR mainly has two contributions. The first one is establishing a new function that can recognize the space between characters. This contribution is quite vital, as it improves the product quality directly. The range of recognition is wider. Another one is that users can set whether to distort the images for data augmentation, which is useful when the number of training images is insufficient.
-
Pull Request #350 (Optimization) This PR introduces L2 normalization which acts as a restriction to the model so as to avoid overfitting during training.
-
Pull Request #360 (Documentation) It provides an English version
quick-startinstruction for CPP inference to the users, so users can set up a demo easily. A well organized guiding document is attractive for both users and developers. -
Pull Request #420 (Optimization) This PR tunes the structure of the code, which makes the code run in a more efficient way. It puts file opening
open()and readingfin.readlines()outside theifcondition statement, so opening and reading will not run repeatedly. -
Pull Request #435 (Functionality) It defines a new function
check_and_read_gif(img_path). This function can load gif images. In so far, it can be used for jpg, bmp, png, rgb, tif formats and a new one, gif. This PR extends the current OCR reading ability to make it more compatible with different formats of inputs. -
Pull Request #510 (Functionality) GPU is originally necessary for deployment, however not every device has a GPU or a powerful one. This PR makes the training process independent of GPUs. If users only want to use CPU, they can add
--use_gpu=Falsein the argument to disable the GPU. -
Pull Request #622 (Debug) The text file should be read in binary which is necessary and crucial to be mentioned using
open(path, 'rb'). The PR fixes this bug by adding'rb'to clarify the reading format. -
Pull Request #1184 (Functionality) This PR is revolutionary. It adds a classifier for directional detecting. Thereafter, the product has the current function
clswhere users can set different hyperparameters for training the direction’s recognition. -
Pull Request #1103 (Functionality) Thanks for this PR, the package for Go is added to this project. The OCR model can be imported and implemented in Go. Because the design obeys the Interface Segregation Principle, the transplant among different platforms is not difficult.
Technical Debt: Code Shows the Fact
Technical debt refers to the accumulated quality defects within the software3. This will bring obstacles to future modification and expansion of the system, although it is usually not intuitive and obvious. Like any other software system, PaddleOCR architecture design and code implementation will bring inevitable risks.
We use the tool SonarQube4 to perform code analysis to assess all python files in the system. The analysis report gives the result shown below.
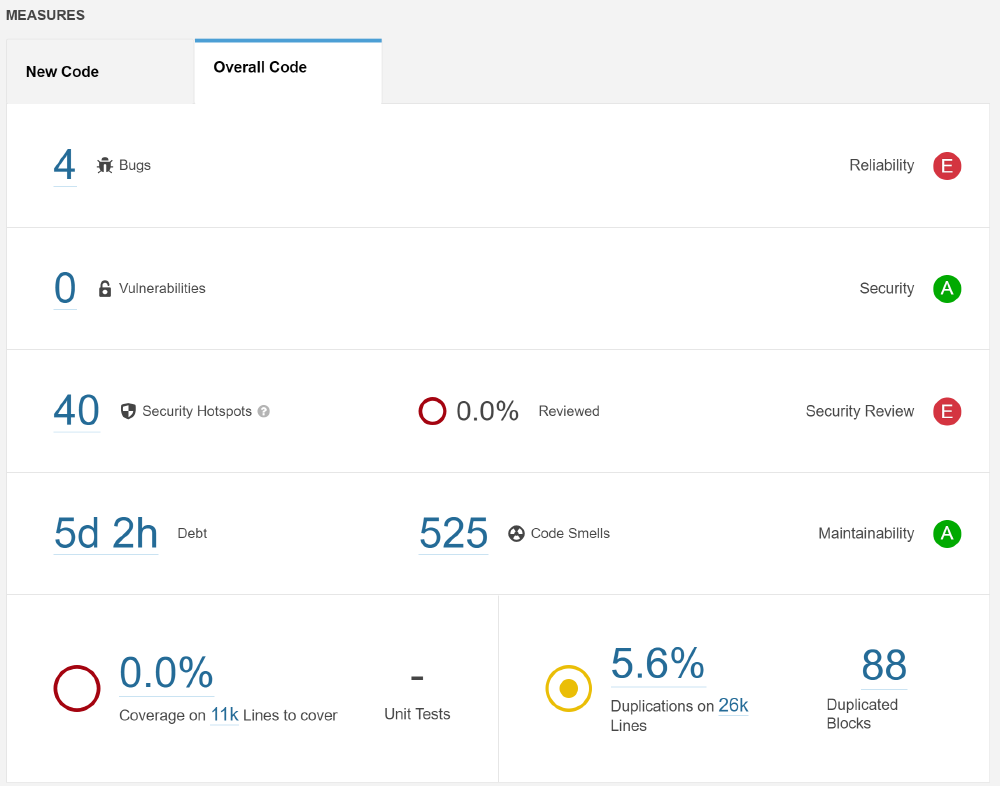
Figure: Code Analysis Report
Bug Matters?
SonarQube found 4 bugs in 26K lines of code and gives E a level of reliability. The first bug is in saveLabels(), from tool/program.py, which uses a try-except structure to capture exceptions. An error message is thrown after the exception occurs, and the function self.errorMessage() has two arguments but the programmer only gives one string here. Considering that this function is only responsible for outputting information, the lack of parameters will not affect the operation of the system.
Other bugs are self-assignment issues. In a function definition, such as add_special_char(self, dict_character), the programmer uses dict_character = dict_character. The function finally returns dict_character, the value of the variable in the class has not been modified.
Yes, those are errors in codes. It will, not now, but probably break at the worst moment. Currently, we fix two bugs by pulling requests and issues. However, we cannot assess the severity of some bugs since some bugs are caused by lack of code. We can not replace the developers to add the details. The good news is, that developers of PaddleOCR are very responsible!They check pull requests and issues every day. They also publish FAQs weekly, which guarantees the quality of the code.
Code Smells and Their Debts
Code smells are maintainability-related issues in the code5. There are 525 code smells, looks like a lot! But is this a serious problem? No. More code smells mean that the maintainer will have a harder time when they try to make changes to the code, the system will not be ‘harmed’ by this but a human.
There are lots of code smells, like from PyQt4.QtGui import *, multiple layers nested if-else, and variable naming issue. It is possible maintainers confused by the code may introduce additional errors as they make changes. Debt is the effort to fix all code smells. Totally 42h needed, SonarQube measured by its database.
Duplications
Measuring the degree of repetition of the PaddleOCR code, we noticed that the average repetition rate is 5.6 %. These duplications reduce the maintainability of the code. Considering that this is a system characterized by ultra-lightweight, we believe that it is appropriate to increase the weight of this indicator in debt analysis. There is still room for the improvement of such a repetition rate. Rewriting the repetitive code into a function will make PaddleOCR more ultra-lightweight!
Hard to Find an Excellent Model
From an architectural perspective, PaddleOCR’s modular design minimizes the technical debt of replacement and renewal of the module. The characteristics of OCR itself make the test cost of the whole system very high, and only the final training result can be used to evaluate the quality of a model. This process requires preparing a large number of training sets, and processing images will also consume a lot of time. It takes 5-6 days to train a model6 . Engineers suffer from a lack of assessment methods and quickly get excellent models.
Reference
[1] Yuning Du, Chenxia Li, Ruoyu Guo, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Zilin Yu, Yehua Yang, Qingqing Dang, Haoshuang Wang.“PP-OCR: A Practical Ultra Lightweight OCR System”. arXiv:2009.09941v3 15 Oct 2020.
[2] Continous integration -Wikipedia https://en.wikipedia.org/wiki/Continuous_integration
[3] TechnicalDebt https://www.martinfowler.com/bliki/TechnicalDebt.html
[4] SonarQube https://www.sonarqube.org/
[5] SonarQube Concepts https://docs.sonarqube.org/latest/user-guide/concepts/